Archive for the ‘Tools’ Category
eAdam
Enkitec’s Oracle AWR Data Mining Tool
 eAdam is a free tool that extracts a subset of data and metadata from an Oracle database with the objective to perform some data mining using a separate staging Oracle database. The data extracted is relevant to Performance Evaluations projects. Most of the data eAdam extracts is licensed by Oracle under the Diagnostics Pack, and some under the Tuning Pack. Therefore, in order to use this eAdam tool, the source database must be licensed to use both Oracle Packs (Tuning and Diagnostics).
eAdam is a free tool that extracts a subset of data and metadata from an Oracle database with the objective to perform some data mining using a separate staging Oracle database. The data extracted is relevant to Performance Evaluations projects. Most of the data eAdam extracts is licensed by Oracle under the Diagnostics Pack, and some under the Tuning Pack. Therefore, in order to use this eAdam tool, the source database must be licensed to use both Oracle Packs (Tuning and Diagnostics).
To a point, eAdam is similar to eDB360; both access the Data Dictionary in order to produce some reports. The key difference is that eDB360 generates all the reports (after doing some intensive processing) at the source database, while eAdam simply extracts a set of flat files into a TAR file, using a very light-weight script, delaying all the intensive processing for a later time and on a separate staging system. This feature can be very attractive for busy systems where the amount of processing of any external monitoring tool needs to be minimized.
On the source system, eAdam only needs to execute a short script to extract the data and metadata of interest, producing a dense TAR file. On a staging system, eAdam does the heavy lifting, requiring the creation of a repository, the load of this repository and finally the computation of meaningful reports. The processing of the TAR file into the staging system is usually performed by the requestor, using a lower-level database, or a remote one.
The list of objects eAdam extracts as flat files from the source database includes the following:
dba_hist_active_sess_history
dba_hist_database_instance
dba_hist_event_histogram
dba_hist_osstat
dba_hist_parameter
dba_hist_pgastat
dba_hist_sga
dba_hist_sgastat
dba_hist_snapshot
dba_hist_sql_plan
dba_hist_sqlstat
dba_hist_sqltext
dba_hist_sys_time_model
dba_hist_sysstat
gv$active_session_history
gv$log
gv$sql_monitor
gv$sql_plan_monitor
gv$sql_plan_statistics_all
gv$sql
gv$system_parameter2
v$controlfile
v$datafile
v$tempfile
eAdam works on 10gR2, 11gR2, and on higher releases of Oracle; and it can be used on Linux or UNIX Platforms. It has not been tested on Windows. An eAdam sample output is available at this Dropbox location; after downloading the sample output, look for the 0001_eadam36_N_dbname_index.html file and start browsing.
Instructions – Source Database
Download the tool, uncompress the master ZIP file, and look for file eadam-master/source_system/eadam_extract.sql. Review and execute this single and short script connecting to the source database as SYS or DBA. Locate the TAR file produced, and send it to the requestor.
Be aware that the TAR file produced by the extraction process can be large, so be sure you execute this extract script from a directory with at least 10 GBs of free space. Common sizes of this TAR file range between 100 MBs and 1 GB. Execution time for this extraction process may exceed 1 hour, depending on the size of the Data Dictionary.
Instructions – Staging Database
Be sure you have both the eAdam tool (eadam-master.zip) and the TAR file produced on a source system. Your staging database can be of equal, higher or lower release level than the source, but equal or higher is recommended. The Platform can be the same or different.
To install, load and report on the staging database, proceed with the following steps:
- Create on the staging system a file directory available to Oracle for read and write. Most probably you want to create this directory connecting to OS as Oracle and create a new directory like /home/oracle/eadam-master. Put in there the content of the eadam-master.zip file.
- Create the eAdam repository on the staging database. This step is needed only one time. Follow instructions from the eadam_readme.txt. Basically you need to execute eadam-master/stage_system/eadam_install.sql connected as SYS. This script asks for 4 parameters: Tablespace names for permanent and temporary schema objects, and the username and password of the new eAdam account. For the username I recommend eadam, but you can use any valid name.
- Load the data contained in the TAR file into the database. To do this you need first to copy the TAR file into the eadam-master/stage_system sub-directory and execute next the stage_system/eadam_load.sql script while on the stage_system sub-directory, and connecting as SYS. This script asks for 4 parameters. Pass first the directory path of your stage_system sub-directory, for example /home/oracle/eadam-master/stage_system (this sub-directory must contain the TAR file). Pass next the username and password of your eadam account as you created them. Pass last the name of the TAR file to be loaded into the database.
- The load process performs some data transformations and it produces at the end an output similar to eDB360 but smaller in content. After you review the eAdam output, you may decide to generate new output for shorter time series, in such case use the eadam-master/stage_system/eadam_report.sql connecting as the eadam user. This reporting process asks for 3 parameters. Pass the EADAM_SEQ_ID which identifies your particular load (a list of values is displayed), then pass the range of dates using format YYYY-MM-DD/HH24:MI, for example 2014-07-27/17:33.
Download
EADAM @ GitHub is available as free software. You can see its eadam_readme.txt, license.txt or any other piece of the tool before downloading it. Use this link eadam-master.zip to actually download eAdam as a compressed file.
Feedback
Please post your feedback about this eAdam tool at this blog, or send and email directly to the tool author: Carlos Sierra.
eDB360
An Oracle Database 360-degree View
 eDB360 is a free tool that executes on an Oracle database and produces a compressed file which includes a large set of small Reports. This set of Reports provides a 360-degree view of an Oracle Database. eDB360 is mostly used for one of the following 3 reasons, listed here in order of frequency of use: 1) Keystone of an Oracle database Health-Check. 2) Kick-off for an Oracle database Performance Evaluation. 3) High-level view of System Resources demand and utilization for an Oracle database Sizing and Provisioning project.
eDB360 is a free tool that executes on an Oracle database and produces a compressed file which includes a large set of small Reports. This set of Reports provides a 360-degree view of an Oracle Database. eDB360 is mostly used for one of the following 3 reasons, listed here in order of frequency of use: 1) Keystone of an Oracle database Health-Check. 2) Kick-off for an Oracle database Performance Evaluation. 3) High-level view of System Resources demand and utilization for an Oracle database Sizing and Provisioning project.
Usually, Developers, Sys Admins and Consultants are not given open access to a database in a Production environment. This eDB360 free tool helps approved users to become familiar with an Oracle database in a non-intrusive way. Without installing anything on the database, the eDB360 tool connects to an Oracle database and produces a large set of flat files that can be reviewed offline while using an HTML browser or a Text editor.
eDB360 can be executed by someone with very limited access to an Oracle database (i.e. a Developer, Sys Admin or Consultant with just query access to the Data Dictionary views); or if executed by an authorized DBA, there is no actual need to provide any additional access to the Oracle database to the party requesting eDB360.
eDB360 works on 10gR2, 11gR2, and on higher releases of Oracle; and it can be used on Linux or UNIX Platforms. It has not been tested on Windows.
Instructions
Download the eDB360 tool and review the readme.md file included. Uncompress the master ZIP file on the Database Server of interest. Navigate to the main (master) directory and execute script edb360.sql connected as SYS or any other account with access to the Data Dictionary views (a DBA account is not required but it is preferred).
Execution time for eDB360 may exceed 1 hour, depending on the size of the Data Dictionary. And the size of the output may reach 1 GB, so be sure you execute this tool from a file system directory with at least 1 GB or free space. Common sizes of the output range between 10 and 100 MB.
eDB360 has only one required execution parameter:
- Oracle Pack License: A big portion of the information presented by eDB360 comes from Oracle’s Automatic Workload Repository (AWR), and AWR is licensed by Oracle under the Diagnostics Pack. A small part of the output of eDB360 comes from the SQL Monitoring repository, which is part of the Oracle Tuning Pack. This parameter accepts one of 3 values: “T”, “D” or “N”. If you database is licensed under the Oracle Tuning Pack, enter then the value of “T”. If your database is not licensed to use the Oracle Tuning Pack but it is licensed to use the Oracle Diagnostics Pack, enter “D” then. If your site is not licensed on any of these two Oracle Packs, enter “N” then. Be aware that a value of “N” reduces substantially the content and value of the output. Thus the preferred parameter value is “T” (Oracle Tuning Pack).
Sample
# unzip edb360-master.zip # cd edb360-master # sqlplus / as sysdba SQL> @edb360.sql T
Download
eDB360, now part of SQLdb360, is available as free-to-use software. You can see its readme.md, license.txt or any other piece of the tool before downloading it.
Feedback
Please post your feedback about this eDB360 tool at this blog, or send and email directly to the tool author: Carlos Sierra.
SQLTXPLAIN PL/SQL Public APIs to execute XTRACT from 3rd party tools
Many tools offer Public APIs, which expose some functionality to other tools. SQLTXPLAIN contains also some Public APIs. They are provided by package SQLTXADMIN.SQLT$E. I would say the most relevant one is XTRACT_SQL_PUT_FILES_IN_DIR. This blog post is about this Public API and how it can be used by other tools to execute a SQLT XTRACT from PL/SQL instead of SQL*Plus.
Imagine a tool that deals with SQL statements, and with the click of a button it invokes SQLTXTRACT on a SQL of interest, and after a few minutes, most files created by SQLTXTRACT suddenly show on an OS pre-defined directory. Implementing this SQLT functionality on an external tool is extremely easy as you will see below.
Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR inputs a SQL_ID and two other optional parameters: A tag to identify output files, and a directory name. Only SQL_ID parameter is mandatory, and the latter two are optional, but I recommend to pass values for all 3.
I used “Q1” as a tag to be included in all output files. And I used staging directory “FROG_DIR” at the database layer, which points to “/home/oracle/frog” at the OS layer.
On sample below, I show how to use this Public API for a particular SQL_ID “8u0n7w1jug5dg”. I call this API from SQL*Plus, but keep in mind that if I were to call it from within a tool’s PL/SQL library, the method would be the same.
Another consideration is that Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR may take several minutes to execute, so you may want to “queue” the request using a Task or a Job within the database. What is important here on this blog post is to explain and show how this Public API works.
SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR parameters:
Find below code snippet showing API Parameters. Notice this API is overloaded, so it may return the STATEMENT_ID or nothing. This STATEMENT_ID is the 5 digits number you see on each SQLT execution.
CREATE OR REPLACE PACKAGE &&tool_administer_schema..sqlt$e AUTHID CURRENT_USER AS
/* $Header: 215187.1 sqcpkge.pks 12.1.03 2013/10/10 carlos.sierra mauro.pagano $ */
/*************************************************************************************/
/* -------------------------
*
* public xtract_sql_put_files_in_dir
*
* executes sqlt xtract on a single sql then
* puts all generated files into an os directory,
* returning the sqlt statement id.
*
* ------------------------- */
FUNCTION xtract_sql_put_files_in_dir (
p_sql_id_or_hash_value IN VARCHAR2,
p_out_file_identifier IN VARCHAR2 DEFAULT NULL,
p_directory_name IN VARCHAR2 DEFAULT 'SQLT$STAGE' )
RETURN NUMBER;
/* -------------------------
*
* public xtract_sql_put_files_in_dir (overload)
*
* executes sqlt xtract on a single sql then
* puts all generated files into an os directory.
*
* ------------------------- */
PROCEDURE xtract_sql_put_files_in_dir (
p_sql_id_or_hash_value IN VARCHAR2,
p_out_file_identifier IN VARCHAR2 DEFAULT NULL,
p_directory_name IN VARCHAR2 DEFAULT 'SQLT$STAGE' );
Staging Directory
To implement Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR on your tool, you need first to create and test a staging directory where the API will write files. This directory needs to be accessible to the “oracle” account, so I show below how to create sample directory “frog” while connected to the OS as “oracle”.
Since the API uses UTL_FILE, it is important that “oracle” can write into it, so be sure you test this UTL_FILE write after you create the directory and before you test Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR.
Use code snippet provided below to test the UTL_FILE writing into this new staging OS directory.
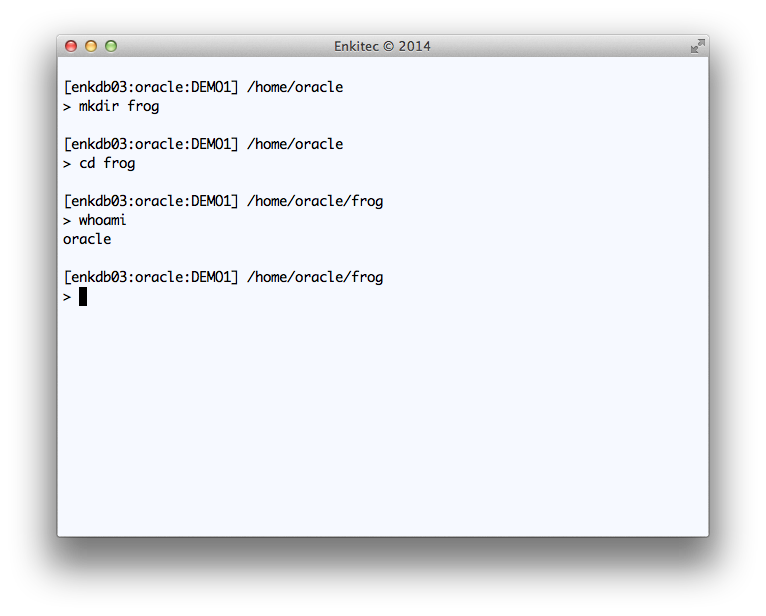
Creating “frog” OS directory connected to OS as “oracle”
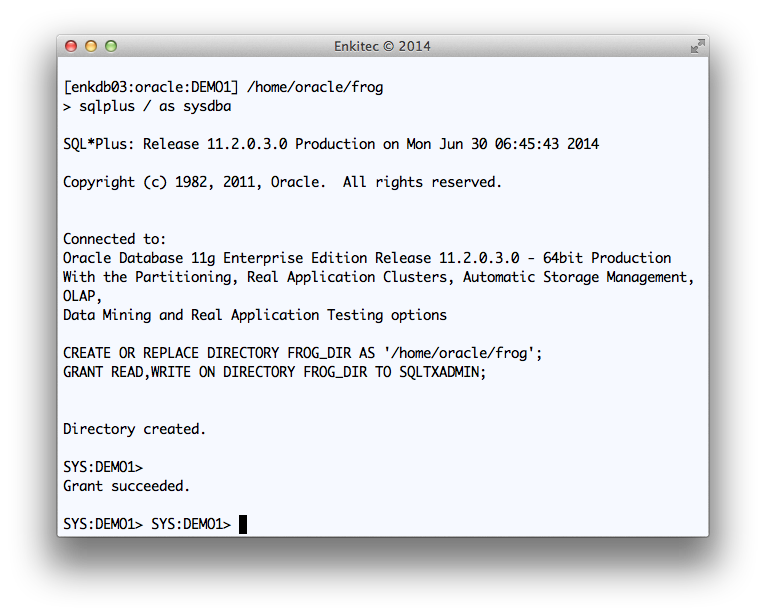
Creating FROG_DIR database directory and providing access to SQLTXADMIN
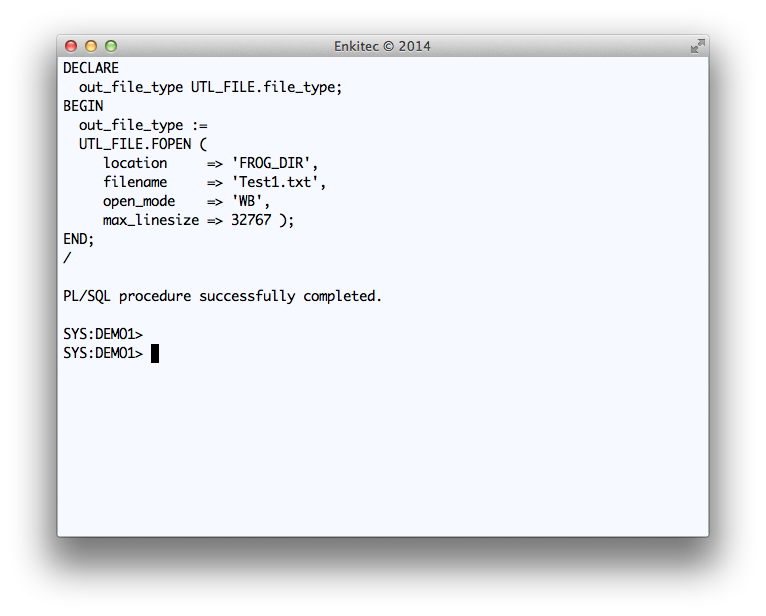
Testing a simple WRITE to FROG_DIR
DECLARE
out_file_type UTL_FILE.file_type;
BEGIN
out_file_type :=
UTL_FILE.FOPEN (
location => 'FROG_DIR',
filename => 'Test1.txt',
open_mode => 'WB',
max_linesize => 32767 );
END;
/
Executing SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR
On your tool, you can call this SQLT Public API from PL/SQL. You may want to use a Task or Job since the API may take several minutes to execute and you do not want the user to simply wait until SQLT completes.
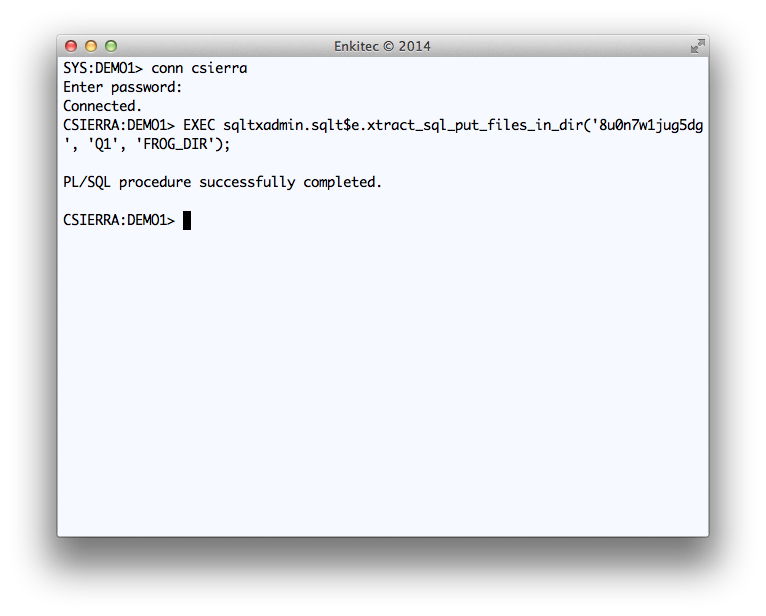
Execution of Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR
Reviewing the output of SQLT XTRACT for SQL_ID “8u0n7w1jug5dg”
Conclusion
Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR is available for any 3rd party tool to use. If SQLT has been pre-installed on a system where your tool executes, then calling this API as shown above, will generate a set of SQLT files on a pre-defined staging OS directory.
If the system where you install your tool does not have SQLT pre-installed, your tool can direct its users to download and install SQLT out of My Oracle Support (MOS) under document 215187.1.
Once you generate all these SQLT XTRACT files into an OS staging directory, you may want to zip them, or make them visible to your tool user. If the latter, then show the “main” html report.
SQLT is an Oracle community tool hosted at Oracle MOS under 215187.1. This tool is not supported, but if you have a question or struggle while implementing this Public API, feel free to shoot me an email or post your question/concern on this blog.
Why using SQLTXPLAIN
Every so often I see on a distribution list a posting that starts like this: “I upgraded my application from database release X to release Y and now many queries are performing poorly, can you tell why?”
As everyone else on a distribution list, my first impulse is to make an educated guess permeated by a prior set of experiences. The intentions are always good, but the process is painful and time consuming. Many of us have seen this kind of question, and many of us have good hunches. Still I think our eagerness to help blinds us a bit. The right thing to do is to step back and analyze the facts, and I mean all the diagnostics supporting the observation.
What is needed to diagnose a SQL Tuning issue?
The list is large, but I will enumerate some of the most important pieces:
- SQL Text
- Version of the database (before and after upgrade)
- Database parameters (before and after)
- State of the CBO Statistics (before and after)
- Changes on Histograms
- Basics about the architecture (CPUs, memory, etc.)
- Values of binds if SQL has them
- Indexes compare, including state (visible?, usable?)
- Execution Plan (before and after)
- Plan stability? (Stored Outlines, Profiles, SQL Plan Management)
- Performance history as per evidence on AWR or StatsPack
- Trace from Event 10053 to understand the CBO
- Trace from Event 10046 level 8 or 12 to review Waits
- Active Session History (ASH) if 10046 is not available
I could keep adding bullets to the list, but I think you get the point: There are simply too many things to check! And each takes some time to collect. More important, the state of the system changes overtime, so you may need to re-collect the same diagnostics more than once.
SQLTXPLAIN to the rescue
SQLT or SQLTXPLAIN, has been available on MetaLink (now MOS) under note 215187.1 for over a decade. In short, SQLT collects all the diagnostics listed above and a lot more. That is WHY Oracle Support uses it every day. It simply saves a lot of time! So, I always encourage fellow Oracle users to make use of the FREE tool and expedite their own SQL Tuning analysis. When time permits, I do volunteer to help on an analysis. So, if you get to read this, and you want to help yourself while using SQLT but feel intimidated by this little monster, please give it a try and contact me for assistance. If I can help, I will, if I cannot, I will let you know.
Conclusion
It is fun to guess WHY a SQL is not performing as expected, and trying different guesses is educational but very time consuming. If you want to actually find root causes before trying to fix your SQL, you may want to collect relevant diagnostics. SQLT is there to help, and if installing this tool is not something you can do in a short term, consider then SQL Health-Check SQLHC.
What is new with EDB360?
Many things, but most important is that it got bigger and better. This EDB360 free tool provided is maturing over time. Its core function has not changed although, which is to present a 360-degree view of a database (10g or higher).
EDB360 is a nice complement to other tools like Exacheck, Raccheck or Oracheck. It has some additional benefits, like taking a snapshot of a system to then be analyzed offline or simply to preserve this snapshot as a baseline.
Keep in mind that EDB360 does not install anything on the database, nor it changes any data on it. In some cases, where direct access to the database server is not an option, having the capability of executing EDB360 through a SQL*Plus client connection is a big plus.
I use EDB360 as a starting place to perform a whole database health-check.
Since pictures tell more than words, please find below 4. The first two are about the new entries on EDB360 main menu (menu is a tad bigger than what you see in these two pictures, and its content is dynamic). The last two pictures are just a sample of the charts that are now part of EDB360.
EDB360 execution parameters changed from 4 to 6:
- Oracle Pack License: If your site has the Tuning Pack, then enter ‘T’, else if your site has the Diagnostics Pack enter ‘D’, else enter ‘N’.
- Days of History to consider. If you entered ‘T’ or ‘D’ on first parameter, then specify on 2nd parameter up to how many days of history you want EDB360 to use. By default it uses 31, assuming your AWR history is at least that big.
- Do you want HTML Reports? By default it is ‘Y’.
- Do you want Text Reports? Defaults to ‘Y’.
- Do you want CSV Files? Defaults to ‘Y’.
- Do you want Charts? Defaults to ‘Y’.
Once you login into SQL*Plus while on top of the edb360 directory, simply execute script edb360.sql and pass all 6 parameters one by one or all of them inline. For example: @edb360 T 31 Y Y Y Y
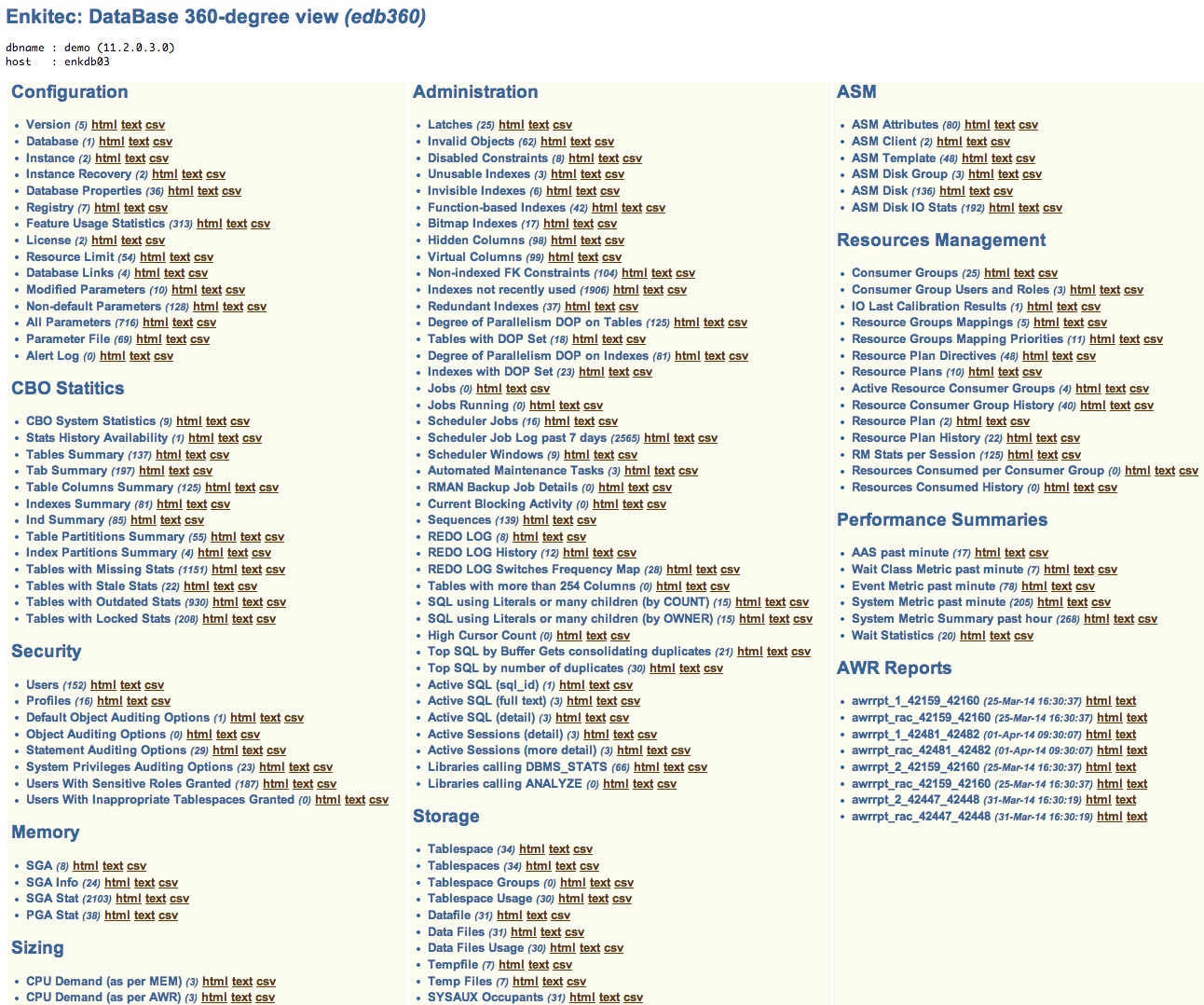
EDB360 Dynamic Menu (part 1)

EDB360 Dynamic Menu (part 2)
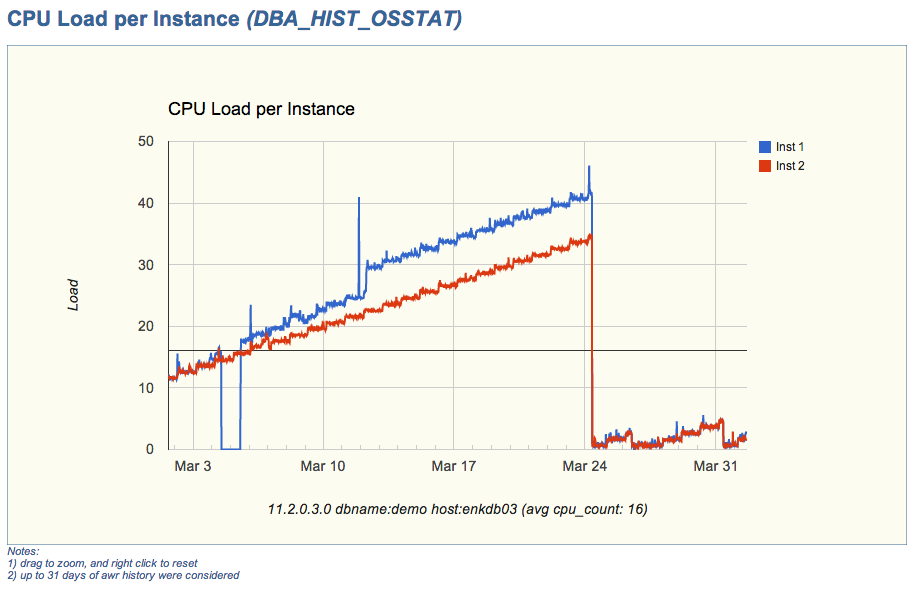
CPU Load per Instance (sample chart)
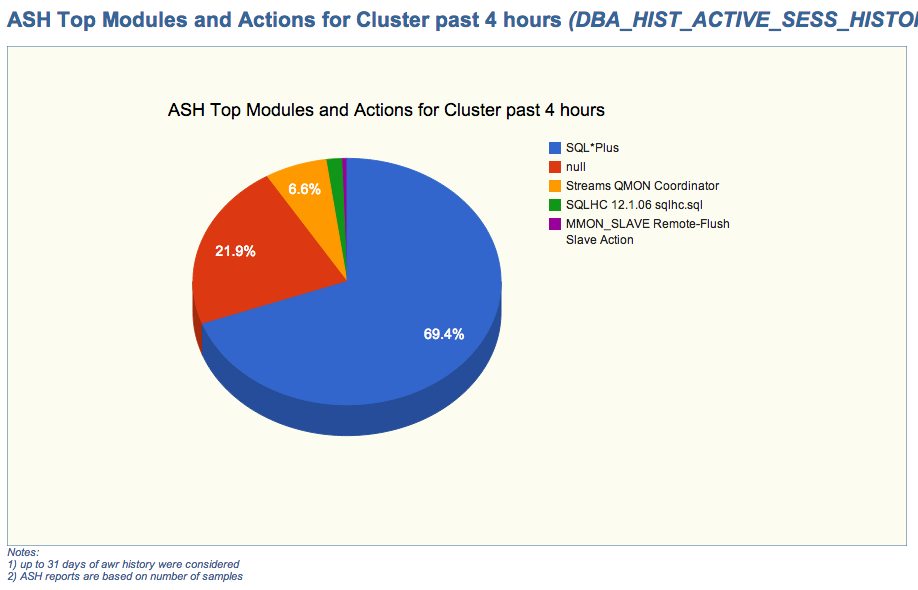
ASH Top Modules and Actions for Cluster (sample chart)
If you have downloaded EDB360 before, then I encourage you to download and test the new version. If you have never used it, I hope you find this tool useful.
