Archive for the ‘eAdam’ Category
eDB360 meets eAdam 3.0 – when two heads are better than one!

Version v1711 of eDB360 invites eAdam 3.0 to the party. What does it mean? We recently learned that eDB360 v1706 introduced the eDB360 repository, which materialized the content of 26 core DBA_HIST views into a staging repository made of heap tables. This in order to expedite the execution of eDB360 on a database with an enlarged AWR. New version v1711 expands the list from 26 views to a total of 219. And these 219 views include now DBA_HIST, DBA, GV$ and V$.
Expanding existing eDB360 repository 8.4x from 26 to 219 views is not what is key on version v1710. The real impact of the latest version of eDB360 is that now it benefits of eAdam 3.0, providing the same benefits of the 219 views of the eDB360 heap-tables repository, but using External Tables, which are easily transported from a source database to a target database. This simple fact opens many doors.
Using the eAdam 3.0 repository from eDB360, we can now extract the metadata from a production database, then restore it on a staging database where we can produce the eDB360 report for the source database. We could also use this new external repository for: finer-granularity data mining; capacity planning; sizing for potential hardware refresh; provisioning tools; to estimate candidate segments for partitioning or for offloading into Hadoop; etc.
With the new external-tables eAdam 3.0 repository, we could easily build a permanent larger heap-table permanent repository for multiple databases (multiple tenants), or for multiple time versions of the same database. Thus, now that eDB360 has met eAdam 3.0, the combination of these two enables multiple innovative future features (custom or to be packaged and shipped with eDB360).
eDB360 recap
eDB360 is a free tool that gives a 360-degree view of an Oracle database. It installs nothing on the database, and it runs on 10g to 12c Oracle databases. It is designed for Linux and UNIX, but runs well on Windows as well (you may want to install first UNIX Utilities UnxUtils and a zip program, else a few OS commands may not properly work on Windows). This repository-less version is the default way to use eDB360, and is the right method for most cases. But now, in addition to the default use, eDB360 can also make use of one of two repositories.
eDB360 takes time to execute (several hours). It is designed to time-out after 24 hours by default. First reason for long execution times is the intentional serial-processing method used, with sequential execution of query after query, while consuming little resources. Such serial execution, plus the fact that it is common to have the tool execute on large databases where the state of AWR is suboptimal, causes the execution to take long. We often discover that source AWR repositories lack expected partitioning, and in many cases they hold years of data instead of expected 8 to 31 days. Therefore, the nature of serial-execution combined with enlarged and suboptimal AWR repositories, usually cause eDB360 to execute for many hours more than expected. With 8 to 31 days of AWR data, and when such reasonable history is well partitioned, eDB360 usually executes in less than 6 hours.
To overcome the undesired extended execution times of eDB360, and besides the obvious (partition and purge AWR), the tool provides the capability to execute in multiple threads splitting its content by column. And now, in addition to the divide-and-conquer approach of column execution, eDB360 provides 2 repositories with different objectives in mind:
- eDB360 repository: Use this method to create a staging repository based on heap tables inside the source database. This method helps to expedite the execution of eDB360 by at least 10x. Repository heap-tables are created and consumed inside the same database.
- eAdam3 repository: Use this method to generate a repository based on external tables on the source database. Such external-tables repository can be moved easily to a remote target system, allowing to efficiently generate the eDB360 report there. This method helps to reduce computations in the source database, and enables potential data mining on the external repository without any resources impact on the source database. This method also helps to build other functions on top of the 219-tables repository.
Views included on both eDB360 and eAdam3 repositories:
- dba_2pc_neighbors
- dba_2pc_pending
- dba_all_tables
- dba_audit_mgmt_config_params
- dba_autotask_client
- dba_autotask_client_history
- dba_cons_columns
- dba_constraints
- dba_data_files
- dba_db_links
- dba_extents
- dba_external_tables
- dba_feature_usage_statistics
- dba_free_space
- dba_high_water_mark_statistics
- dba_hist_active_sess_history
- dba_hist_database_instance
- dba_hist_event_histogram
- dba_hist_ic_client_stats
- dba_hist_ic_device_stats
- dba_hist_interconnect_pings
- dba_hist_memory_resize_ops
- dba_hist_memory_target_advice
- dba_hist_osstat
- dba_hist_parameter
- dba_hist_pgastat
- dba_hist_resource_limit
- dba_hist_seg_stat
- dba_hist_service_name
- dba_hist_sga
- dba_hist_sgastat
- dba_hist_snapshot
- dba_hist_sql_plan
- dba_hist_sqlstat
- dba_hist_sqltext
- dba_hist_sys_time_model
- dba_hist_sysmetric_history
- dba_hist_sysmetric_summary
- dba_hist_sysstat
- dba_hist_system_event
- dba_hist_tbspc_space_usage
- dba_hist_wr_control
- dba_ind_columns
- dba_ind_partitions
- dba_ind_statistics
- dba_ind_subpartitions
- dba_indexes
- dba_jobs
- dba_jobs_running
- dba_lob_partitions
- dba_lob_subpartitions
- dba_lobs
- dba_obj_audit_opts
- dba_objects
- dba_pdbs
- dba_priv_audit_opts
- dba_procedures
- dba_profiles
- dba_recyclebin
- dba_registry
- dba_registry_hierarchy
- dba_registry_history
- dba_registry_sqlpatch
- dba_role_privs
- dba_roles
- dba_rsrc_consumer_group_privs
- dba_rsrc_consumer_groups
- dba_rsrc_group_mappings
- dba_rsrc_io_calibrate
- dba_rsrc_mapping_priority
- dba_rsrc_plan_directives
- dba_rsrc_plans
- dba_scheduler_job_log
- dba_scheduler_jobs
- dba_scheduler_windows
- dba_scheduler_wingroup_members
- dba_segments
- dba_sequences
- dba_source
- dba_sql_patches
- dba_sql_plan_baselines
- dba_sql_plan_dir_objects
- dba_sql_plan_directives
- dba_sql_profiles
- dba_stat_extensions
- dba_stmt_audit_opts
- dba_synonyms
- dba_sys_privs
- dba_tab_cols
- dba_tab_columns
- dba_tab_modifications
- dba_tab_partitions
- dba_tab_privs
- dba_tab_statistics
- dba_tab_subpartitions
- dba_tables
- dba_tablespace_groups
- dba_tablespaces
- dba_temp_files
- dba_triggers
- dba_ts_quotas
- dba_unused_col_tabs
- dba_users
- dba_views
- gv$active_session_history
- gv$archive_dest
- gv$archived_log
- gv$asm_disk_iostat
- gv$database
- gv$dataguard_status
- gv$event_name
- gv$eventmetric
- gv$instance
- gv$instance_recovery
- gv$latch
- gv$license
- gv$managed_standby
- gv$memory_current_resize_ops
- gv$memory_dynamic_components
- gv$memory_resize_ops
- gv$memory_target_advice
- gv$open_cursor
- gv$osstat
- gv$parameter
- gv$pga_target_advice
- gv$pgastat
- gv$pq_slave
- gv$pq_sysstat
- gv$process
- gv$process_memory
- gv$px_buffer_advice
- gv$px_process
- gv$px_process_sysstat
- gv$px_session
- gv$px_sesstat
- gv$resource_limit
- gv$result_cache_memory
- gv$result_cache_statistics
- gv$rsrc_cons_group_history
- gv$rsrc_consumer_group
- gv$rsrc_plan
- gv$rsrc_plan_history
- gv$rsrc_session_info
- gv$rsrcmgrmetric
- gv$rsrcmgrmetric_history
- gv$segstat
- gv$services
- gv$session
- gv$session_blockers
- gv$session_wait
- gv$sga
- gv$sga_target_advice
- gv$sgainfo
- gv$sgastat
- gv$sql
- gv$sql_monitor
- gv$sql_plan
- gv$sql_shared_cursor
- gv$sql_workarea_histogram
- gv$sysmetric
- gv$sysmetric_summary
- gv$sysstat
- gv$system_parameter2
- gv$system_wait_class
- gv$temp_extent_pool
- gv$undostat
- gv$waitclassmetric
- gv$waitstat
- v$archive_dest_status
- v$archived_log
- v$ash_info
- v$asm_attribute
- v$asm_client
- v$asm_disk
- v$asm_disk_stat
- v$asm_diskgroup
- v$asm_diskgroup_stat
- v$asm_file
- v$asm_template
- v$backup
- v$backup_set_details
- v$block_change_tracking
- v$cell_config
- v$cell_state
- v$controlfile
- v$database
- v$database_block_corruption
- v$datafile
- v$flashback_database_log
- v$flashback_database_stat
- v$instance
- v$io_outlier
- v$iostat_file
- v$kernel_io_outlier
- v$lgwrio_outlier
- v$log
- v$log_history
- v$logfile
- v$mystat
- v$nonlogged_block
- v$option
- v$parallel_degree_limit_mth
- v$parameter
- v$pdbs
- v$recovery_area_usage
- v$recovery_file_dest
- v$restore_point
- v$rman_backup_job_details
- v$rman_output
- v$segstat
- v$spparameter
- v$standby_log
- v$sys_time_model
- v$sysaux_occupants
- v$system_parameter2
- v$tablespace
- v$tempfile
- v$thread
- v$version
Instructions to use eDB360 and eAdam3 repositories
Both repositories are implemented under the edb360-master/repo subdirectory. Each has a readme file, which explains how to create the repository, consume it and drop it. The eAdam3 repository also includes instructions how to clone an external-table-based eAdam repository into a heap-table-based eDB360 repository.
Executing eDB360 on the eDB360 repository is faster than executing it on the eAdam3 repository, while avoiding new bug 25802477. This new Oracle database bug inflicts compressed external-tables like the ones used by the eAdam3 repository.
If you use eDB360 or eAdam3 repositories and have questions or concerns, do not hesitate to contact the author.
eDB360 new features (March 2017)

As many of you know, eDB360 is a free tool that provides a 360-degree view of an Oracle database without any installation. A new version is available like once per month, but occasionally a large number of enhancements are implemented at once. This new release v1708 (March 25, 2017) includes several new features requested recently by some users of the tool, thus the need to blog about what is new:
- Reducing the scope of eDB360 is now possible without having to generate a custom configuration file. Prior to this version, if a user wanted to generate output for let’s say AWR reports only (section 7a), the tool needed a custom.sql file with line DEF edb360_sections = ‘7a’;. Then we would pass to edb360.sql as 2nd execution parameter the name of this custom configuration file (too cumbersome!). Starting on v1708, we can directly pass to edb360.sql the section that we desire (i.e. SQL> @edb360 T 7a). This 2nd parameter can either input the name of a custom configuration file (legacy functionality), but now it also accepts a column, a section, a list of columns or a list of sections; for example: 7a, 7, 7a-7b, 1-4 and 3 are all valid values.
- A couple of reports were added to section 3h: “SQL in logon storms” and “SQL executed row-by-row”. The former identifies those SQL statements that are seen frequently on very short-lived sessions (based on ASH), and the latter presents a list of SQL statements with large number of executions and small number of rows processed.
- eDB360 now extracts ASH from eAdam for top 16 SQL_ID (as per SQLd360 list) + top 12 SNAP_ID (as per AWR MAX from column 7a). What it means is that eDB360 includes now a tar file with raw ASH data for both: SQL statements of interest and for AWR periods of interest (both according to what eDB360 considers important). Using eAdam is easy, so when content of eDB360 does not include a very specific aggregation of ASH data that we need, or when we have to understand the sequence of some ASH samples for example, we can then restore this eAdam data on any Oracle database and data mine it.
- Some reports on section 2b show now totals at the bottom. That is to SUM some numeric values. Other reports may follow in future releases.
- RMAN section includes now a new report “Blocks with Corruption or Non-logged”.
- Added Load Profile (Per Sec, Per Txn and Count) as per DBA_HIST_SYSMETRIC_SUMMARY. This Load Profile resembles what we see on AWR at the top, but this is computed for the entire period of diagnostics (31 days by default). It shows max values, average, median and several percentiles. With this new report on section 1a, we can glance over it and discover in minutes some areas of further interest, for example: logons per second too high, just to mention one.
- There is a new section 4i with “Waits Count v.s. Average Latency for top 24 Wait Events”. With this set of 24 reports (one for each of the top wait events) we can observe if patterns on the number of counts relate to patterns on the latency for such wait event; for example we are able to see if an increase in the number of waits for db file sequential reads correlates to an increase of average latency for such wait event. We can also observe cases were latency for a wait event cannot be explained by load on current database, thus hinting an external influence.
- Fixed “ORA-01476: divisor is equal to zero” on planx at DBA_HIST_SQLSTAT.
- Added AWR DIFF reports for RAC and per instance. These are computed comparing MAX reports to MEDIAN reports, and they help to quickly identify large differences on load. These new AWR DIFF reports are regulated by configuration parameter edb360_conf_incl_addm_rpt (enabled by default). They exist on 11R2 and higher.
- Added the ASH Analytics Active report for 12c. This new ASH report is regulated by configuration parameter edb360_conf_incl_ash_analy_rpt (enabled by default). This applies to 12c and higher.
- The name of the database is now part of the main filename. Some users requested to include this database name as part of the main zip file since they are using eDB360 periodically on several databases. This new feature is regulated by configuration parameter edb360_conf_incl_dbname_file (disabled by default).
- At completion, main eDB360 zip file can now by automatically moved to a location other than the standard SQL*Plus working directory. All output files are still generated on the local SQL*Plus directory from where the script edb360.sql is executed (i.e. edb360-master directory), but at the completion of the execution the consolidated output zip file is now moved to a location specified by a new parameter. This new feature is regulated by configuration parameter edb360_move_directory (disabled by default).
- Added new report on “Database and Schema Triggers” under column 3h. This new report can be used to see potential LOGON or other global triggers. For triggers on specific tables, refer to SQLd360 which is automatically included on eDB360 for top SQL.
- All queries executed by eDB360 to generate its output were modified. New format is q'[query]’. Reason for this change is to improve readability of the code.
Always download and use the latest version of this tool. For questions or feedback email me. And I hope you get to enjoy eDB360 as much as I do!
SQLTXPLAIN under new administration
During my 17 years at Oracle, I developed several tools and scripts. The largest and more widely used is SQLTXPLAIN. It is available through My Oracle Support (MOS) under document_id 215187.1.
SQLTXPLAIN, also know as SQLT, is a tool for SQL diagnostics, including Performance and Wrong Results. I am the original developer and author, but since very early stages of its development, this tool encapsulates the expertise of many bright engineers, DBAs, developers and others, who constantly helped to improve this tool on every new release by providing valuable feedback. SQLT is then nothing but the collection of many good ideas from many people. I was just the lucky guy that decided to build something useful for the Oracle SQL tuning community.
When I decided to join Enkitec back on 2013, I asked Mauro Pagano to look after my baby (I mean SQLT), and sure enough he did an excellent job. Mauro fixed most of my bugs, as he jokes about, and also incorporated some of his own :-). Mauro kept SQLT in good shape and he was able to continue improving it on every new release. Now Mauro also works for Enkitec, so SQLT has a new owner and custodian at Oracle.
Abel Macias is the new owner of SQLT, and as such he gets busy maintaining and enhancing this tool among other duties at Oracle. So, if you have enhancement requests, or positive feedback, please reach out to Abel at his Oracle account: abel.macias@oracle.com. If you come across some of my other tools and scripts, and they show my former Oracle account (carlos.sierra@oracle.com), please reach out to Abel and he might be able to route your concern or question.
Since one of my hobbies is to build free software that I also consume, my current efforts are on eDB360, eAdam and eSP. The most popular and openly available is eDB360, which basically gives your a 360-degree view of a database without installing anything. Then, Mauro is also building something cool on his own free time. Mauro is building the new SQLd360 tool, which is already available on the web (search for SQLd360). This SQLd360 tool, similar to eDB360, provides a 360-degree view, but instead of a database its focus is one SQL. And similarly than eDB360 it installs nothing on the database. Both are available as “free software” for anyone to download and use. That is the nice part: everyone likes free! (specially if any good).
What is the difference between SQLd360 and SQLT?
Both are exceptional tools. And both can be used for SQL Tuning and for SQL diagnostics. The main differences in my opinion are these:
- SQLT has it all. It is huge and it covers pretty much all corners. So, for SQL Tuning this SQLTXPLAIN is “THE” tool.
- SQLd360 in the other hand is smaller, newer and faster to execute. It gives me what is more important and most commonly used.
- SQLT requires to install a couple of schemas and hundreds of objects. SQLd360 installs nothing!
- To download SQLT you need to login into MOS. In contrast, SQLd360 is wide open (free software license), and no login is needed.
- Oracle Support requires SQLT, and Oracle Engineers are not exposed yet to SQLd360.
- SQLd360 uses Google charts (as well as eDB360 does) which enhance readability of large data sets, like time series for example. Thus SQLd360 output is quite readable.
- eDB360 calls SQLd360 on SQL of interest (large database consumers), so in that sense SQLd360 enhances eDB360. But SQLd360 can also be used stand-alone.
If you ask me which one would I recommend, I would answer: both!. If you can use both, then that is better than using just one. Each of these two tools (SQLT and SQLd360) has pros and cons compared to the other. But at the end both are great tools. And thanks to Abel Macias, SQLT continues its lifecycle with frequent enhancements. And thanks to Mauro, we have now a new kid on the block! I would say we have a win-win for our large Oracle community!
eSP
 Enkitec’s Sizing and Provisioning (eSP) is a new internal tool designed and developed with Oracle Engineered Systems in mind. Thanks to the experience and insights from Randy Johnson, Karl Arao and Frits Hoogland, what began as a pet project for some of us, over time became an actual robust APEX/PLSQL application, developed by Christoph Ruepprich and myself, and ready to debut at Oracle Open World 2014.
Enkitec’s Sizing and Provisioning (eSP) is a new internal tool designed and developed with Oracle Engineered Systems in mind. Thanks to the experience and insights from Randy Johnson, Karl Arao and Frits Hoogland, what began as a pet project for some of us, over time became an actual robust APEX/PLSQL application, developed by Christoph Ruepprich and myself, and ready to debut at Oracle Open World 2014.
This posting is about eSP, what it does, and how it helps on the sizing and provisioning of Oracle Engineered System, or I would rather say, any System where Oracle runs.
We used to size Engineered Systems using a complex and very useful spread sheet developed by Randy Johnson and Karl Arao. Now, it is the turn for eSP to take the next step, and move this effort forward into a more scalable application that sits on top of one of our Exadata machines.
Sizing an Engineered System
Sizing a System can be quite challenging, especially when the current system is composed of several hosts with multiple databases of diverse use, size, versions, workloads, etc. The new target system may also bring some complexities; as the number of possible configurations grows, finding the right choice becomes harder. Then we also have the challenge of disk redundancy, recovery areas, the potential benefits of offloading with their smart scans, just to mention some added complexities.
At a very high level, Sizing a System is about 3 entities: Resources, Capacity and Utilization. Resources define what I call “demand”, which is basically the set of computational resources from your original System made of one or many databases and instances over some hosts. Capacity, which I also call it “supply”, is the set of possible target Systems with their multiple Configurations, in other words Engineered Systems, or any other hardware capable to host Oracle databases. Utilization, which I may also refer as “allocation” is where the magic and challenge resides. It is a clever and unbiassed mapping between databases and configurations, then between instances and nodes. This mapping has to consider at the very least CPU footprint, Memory for SGA and PGA, database disk space, and throughput in terms of IOPS and MBPS. Additional constraints, as mentioned before, include redundancy and offloading among others. CPU can be a bit tricky since each CPU make and model has its own characteristics, so mapping them requires the use of SPEC.
Other challenge a Sizing tool has to consider is the variability of the Resources. The question becomes: Do we see the Resources as a worst case scenario, or shall we rather consider them as time series? In other words, do we compute and use peaks, or do we observe the use of Resources over time, then develop some methods to aggregate them consistently as time series? If we decide to use a reduced set of data points, do we use peaks or percentiles? if the latter, which percentile is well balanced? 99.9, 99, 95 or maybe 90? How conservative are those values? There are so many questions and the answer for most of them, as you may guess is: “it all depends”.
How eSP Works
Without getting into the technical details, I can say that eSP is an APEX application with a repository on an Oracle database, which inputs collected “Requirements” from the databases to be sized, then it processes these Requirements and prepares them to be “Allocated” into one or more defined hardware configurations. The process is for the most part “automated”, meaning this: we execute some tool or script in the set of hosts where the databases reside, then upload the output of these collectors into eSP and we are ready to Plan and apply “what-if” scenarios. Having an Exadata System as our work engine, it allows this eSP application to scale quite well. A “what-if” scenario takes as long as it takes to navigate APEX pages,while all the computations are done in sub-seconds behind scenes, thanks to Exadata!
Once we load the Resources from the eSP collector script, or from the eAdam tool, we can start playing with the metadata. Since eSP’s set of known Configurations (Capacity) include current Engineered Systems (X4), allocating Configurations is a matter of seconds, then mapping databases and instances becomes the next step. eSP contains an auto “allocate” algorithm for databases and instances, where we can choose between a “balanced” allocation or one that is “dense” with several density factors to choose from (100%, 90%, 80%, 70%, 60% and 50%). With all these automated options, we can try multiple sizing and allocation possibilities in seconds, regardless if we are Sizing and Provisioning for one database or a hundred of them.
eSP and OOW
 The Enkitec’s Sizing and Provisioning (eSP) tool is an internal application that we created to help our customers to Size their next System or Systems in a sensible manner. The methods we implemented are transparent and unbiassed. We are bringing eSP to Oracle Open World 2014. I will personally demo eSP at our assigned booth, which is #111 at the Moscone South. I will be on and off the booth, so if you are interested on a demo please let me know, or contact your Enkitec/Accenture representative. We do prefer appointments, but walk-ins are welcomed. Hope to see you at OOW!
The Enkitec’s Sizing and Provisioning (eSP) tool is an internal application that we created to help our customers to Size their next System or Systems in a sensible manner. The methods we implemented are transparent and unbiassed. We are bringing eSP to Oracle Open World 2014. I will personally demo eSP at our assigned booth, which is #111 at the Moscone South. I will be on and off the booth, so if you are interested on a demo please let me know, or contact your Enkitec/Accenture representative. We do prefer appointments, but walk-ins are welcomed. Hope to see you at OOW!
Free script to generate a Line Chart on HTML
Performance Metrics are easier to digest if visualized trough some Line Charts. OEM, eDB360, eAdam and other tools use them. If you already have a SQL Statement that provides the Performance Metrics you care about, and just need to generate a Line Chart for them, you can easily create a CSV file and open it with MS-Excel. But if you want to build an HTML Report out of your SQL, that is a bit harder, unless you use existing technologies. Tools like eDB360 and eAdam use Google Charts as a mechanism to easily generate such Charts. A peer asked me if we could have such functionality stand-alone, and that challenged me to create and share it.
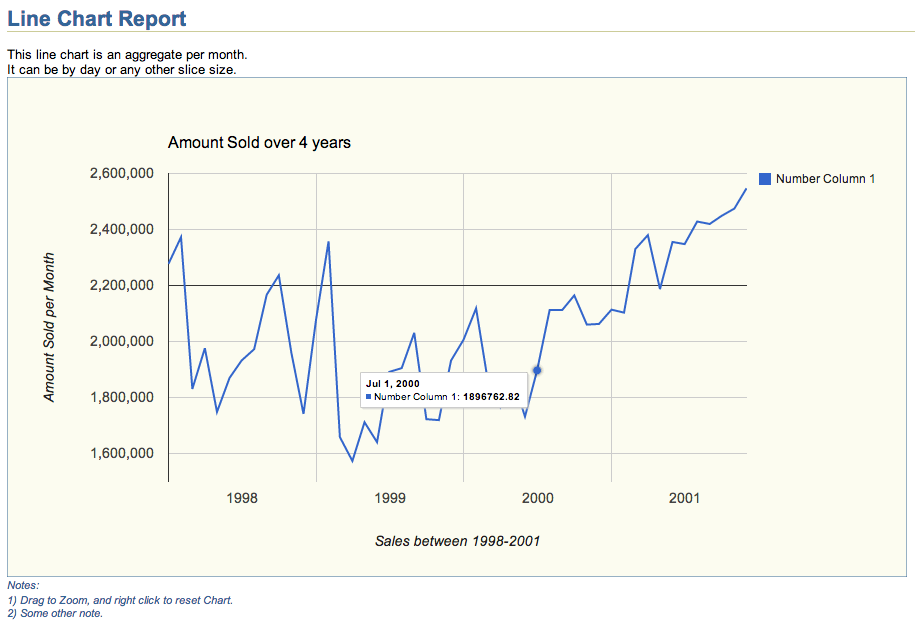
This HTML Line Chart Report above was created with script line_chart.sql shown below. The actual chart, which includes Zoom functionality on HTML can be downloaded from this Dropbox location. Feel free to use this line_chart.sql script as a template to display your Performance Metrics. It can display several series into one Chart (example above shows only one), and by reviewing code below you will find out how easy it is to adjust to your own needs. Chart above was created using a simple query against the Oracle Sample Schema SH, but the actual use could be Performance Metrics or any other Application time series.
Script
SET TERM OFF HEA OFF LIN 32767 NEWP NONE PAGES 0 FEED OFF ECHO OFF VER OFF LONG 32000 LONGC 2000 WRA ON TRIMS ON TRIM ON TI OFF TIMI OFF ARRAY 100 NUM 20 SQLBL ON BLO . RECSEP OFF;
PRO
DEF report_title = "Line Chart Report";
DEF report_abstract_1 = "<br>This line chart is an aggregate per month.";
DEF report_abstract_2 = "<br>It can be by day or any other slice size.";
DEF report_abstract_3 = "";
DEF report_abstract_4 = "";
DEF chart_title = "Amount Sold over 4 years";
DEF xaxis_title = "Sales between 1998-2001";
--DEF vaxis_title = "Amount Sold per Hour";
--DEF vaxis_title = "Amount Sold per Day";
DEF vaxis_title = "Amount Sold per Month";
DEF vaxis_baseline = ", baseline:2200000";
DEF chart_foot_note_1 = "<br>1) Drag to Zoom, and right click to reset Chart.";
DEF chart_foot_note_2 = "<br>2) Some other note.";
DEF chart_foot_note_3 = "";
DEF chart_foot_note_4 = "";
DEF report_foot_note = "This is a sample line chart report.";
PRO
SPO line_chart.html;
PRO <html>
PRO <!-- $Header: line_chart.sql 2014-07-27 carlos.sierra $ -->
PRO <head>
PRO <title>line_chart.html</title>
PRO
PRO <style type="text/css">
PRO body {font:10pt Arial,Helvetica,Geneva,sans-serif; color:black; background:white;}
PRO h1 {font-size:16pt; font-weight:bold; color:#336699; border-bottom:1px solid #cccc99; margin-top:0pt; margin-bottom:0pt; padding:0px 0px 0px 0px;}
PRO h2 {font-size:14pt; font-weight:bold; color:#336699; margin-top:4pt; margin-bottom:0pt;}
PRO h3 {font-size:12pt; font-weight:bold; color:#336699; margin-top:4pt; margin-bottom:0pt;}
PRO pre {font:8pt monospace;Monaco,"Courier New",Courier;}
PRO a {color:#663300;}
PRO table {font-size:8pt; border_collapse:collapse; empty-cells:show; white-space:nowrap; border:1px solid #cccc99;}
PRO li {font-size:8pt; color:black; padding-left:4px; padding-right:4px; padding-bottom:2px;}
PRO th {font-weight:bold; color:white; background:#0066CC; padding-left:4px; padding-right:4px; padding-bottom:2px;}
PRO td {color:black; background:#fcfcf0; vertical-align:top; border:1px solid #cccc99;}
PRO td.c {text-align:center;}
PRO font.n {font-size:8pt; font-style:italic; color:#336699;}
PRO font.f {font-size:8pt; color:#999999; border-top:1px solid #cccc99; margin-top:30pt;}
PRO </style>
PRO
PRO <script type="text/javascript" src="https://www.google.com/jsapi"></script>
PRO <script type="text/javascript">
PRO google.load("visualization", "1", {packages:["corechart"]})
PRO google.setOnLoadCallback(drawChart)
PRO
PRO function drawChart() {
PRO var data = google.visualization.arrayToDataTable([
/* add below more columns if needed (modify 3 places) */
PRO ['Date Column', 'Number Column 1']
/****************************************************************************************/
WITH
my_query AS (
/* query below selects one date_column and a small set of number_columns */
SELECT --TRUNC(time_id, 'HH24') date_column /* preserve the column name */
--TRUNC(time_id, 'DD') date_column /* preserve the column name */
TRUNC(time_id, 'MM') date_column /* preserve the column name */
, SUM(amount_sold) number_column_1 /* add below more columns if needed (modify 3 places) */
FROM sh.sales
GROUP BY
--TRUNC(time_id, 'HH24') /* aggregate per hour, but it could be any other */
--TRUNC(time_id, 'DD') /* aggregate per day, but it could be any other */
TRUNC(time_id, 'MM') /* aggregate per month, but it could be any other */
/* end of query */
)
/****************************************************************************************/
/* no need to modify the date column below, but you may need to add some number columns */
SELECT ', [new Date('||
TO_CHAR(q.date_column, 'YYYY')|| /* year */
','||(TO_NUMBER(TO_CHAR(q.date_column, 'MM')) - 1)|| /* month - 1 */
--','||TO_CHAR(q.date_column, 'DD')|| /* day */
--','||TO_CHAR(q.date_column, 'HH24')|| /* hour */
--','||TO_CHAR(q.date_column, 'MI')|| /* minute */
--','||TO_CHAR(q.date_column, 'SS')|| /* second */
')'||
','||q.number_column_1|| /* add below more columns if needed (modify 3 places) */
']'
FROM my_query q
ORDER BY
date_column
/
/****************************************************************************************/
PRO ]);
PRO
PRO var options = {
PRO backgroundColor: {fill: '#fcfcf0', stroke: '#336699', strokeWidth: 1},
PRO explorer: {actions: ['dragToZoom', 'rightClickToReset'], maxZoomIn: 0.1},
PRO title: '&&chart_title.',
PRO titleTextStyle: {fontSize: 16, bold: false},
PRO focusTarget: 'category',
PRO legend: {position: 'right', textStyle: {fontSize: 12}},
PRO tooltip: {textStyle: {fontSize: 10}},
PRO hAxis: {title: '&&xaxis_title.', gridlines: {count: -1}},
PRO vAxis: {title: '&&vaxis_title.' &&vaxis_baseline., gridlines: {count: -1}}
PRO }
PRO
PRO var chart = new google.visualization.LineChart(document.getElementById('chart_div'))
PRO chart.draw(data, options)
PRO }
PRO </script>
PRO </head>
PRO <body>
PRO <h1>&&report_title.</h1>
PRO &&report_abstract_1.
PRO &&report_abstract_2.
PRO &&report_abstract_3.
PRO &&report_abstract_4.
PRO <div id="chart_div" style="width: 900px; height: 500px;"></div>
PRO <font class="n">Notes:</font>
PRO <font class="n">&&chart_foot_note_1.</font>
PRO <font class="n">&&chart_foot_note_2.</font>
PRO <font class="n">&&chart_foot_note_3.</font>
PRO <font class="n">&&chart_foot_note_4.</font>
PRO <pre>
L
PRO </pre>
PRO <br>
PRO <font class="f">&&report_foot_note.</font>
PRO </body>
PRO </html>
SPO OFF;
SET HEA ON LIN 80 NEWP 1 PAGES 14 FEED ON ECHO OFF VER ON LONG 80 LONGC 80 WRA ON TRIMS OFF TRIM OFF TI OFF TIMI OFF ARRAY 15 NUM 10 NUMF "" SQLBL OFF BLO ON RECSEP WR;
eAdam
Enkitec’s Oracle AWR Data Mining Tool
 eAdam is a free tool that extracts a subset of data and metadata from an Oracle database with the objective to perform some data mining using a separate staging Oracle database. The data extracted is relevant to Performance Evaluations projects. Most of the data eAdam extracts is licensed by Oracle under the Diagnostics Pack, and some under the Tuning Pack. Therefore, in order to use this eAdam tool, the source database must be licensed to use both Oracle Packs (Tuning and Diagnostics).
eAdam is a free tool that extracts a subset of data and metadata from an Oracle database with the objective to perform some data mining using a separate staging Oracle database. The data extracted is relevant to Performance Evaluations projects. Most of the data eAdam extracts is licensed by Oracle under the Diagnostics Pack, and some under the Tuning Pack. Therefore, in order to use this eAdam tool, the source database must be licensed to use both Oracle Packs (Tuning and Diagnostics).
To a point, eAdam is similar to eDB360; both access the Data Dictionary in order to produce some reports. The key difference is that eDB360 generates all the reports (after doing some intensive processing) at the source database, while eAdam simply extracts a set of flat files into a TAR file, using a very light-weight script, delaying all the intensive processing for a later time and on a separate staging system. This feature can be very attractive for busy systems where the amount of processing of any external monitoring tool needs to be minimized.
On the source system, eAdam only needs to execute a short script to extract the data and metadata of interest, producing a dense TAR file. On a staging system, eAdam does the heavy lifting, requiring the creation of a repository, the load of this repository and finally the computation of meaningful reports. The processing of the TAR file into the staging system is usually performed by the requestor, using a lower-level database, or a remote one.
The list of objects eAdam extracts as flat files from the source database includes the following:
dba_hist_active_sess_history
dba_hist_database_instance
dba_hist_event_histogram
dba_hist_osstat
dba_hist_parameter
dba_hist_pgastat
dba_hist_sga
dba_hist_sgastat
dba_hist_snapshot
dba_hist_sql_plan
dba_hist_sqlstat
dba_hist_sqltext
dba_hist_sys_time_model
dba_hist_sysstat
gv$active_session_history
gv$log
gv$sql_monitor
gv$sql_plan_monitor
gv$sql_plan_statistics_all
gv$sql
gv$system_parameter2
v$controlfile
v$datafile
v$tempfile
eAdam works on 10gR2, 11gR2, and on higher releases of Oracle; and it can be used on Linux or UNIX Platforms. It has not been tested on Windows. An eAdam sample output is available at this Dropbox location; after downloading the sample output, look for the 0001_eadam36_N_dbname_index.html file and start browsing.
Instructions – Source Database
Download the tool, uncompress the master ZIP file, and look for file eadam-master/source_system/eadam_extract.sql. Review and execute this single and short script connecting to the source database as SYS or DBA. Locate the TAR file produced, and send it to the requestor.
Be aware that the TAR file produced by the extraction process can be large, so be sure you execute this extract script from a directory with at least 10 GBs of free space. Common sizes of this TAR file range between 100 MBs and 1 GB. Execution time for this extraction process may exceed 1 hour, depending on the size of the Data Dictionary.
Instructions – Staging Database
Be sure you have both the eAdam tool (eadam-master.zip) and the TAR file produced on a source system. Your staging database can be of equal, higher or lower release level than the source, but equal or higher is recommended. The Platform can be the same or different.
To install, load and report on the staging database, proceed with the following steps:
- Create on the staging system a file directory available to Oracle for read and write. Most probably you want to create this directory connecting to OS as Oracle and create a new directory like /home/oracle/eadam-master. Put in there the content of the eadam-master.zip file.
- Create the eAdam repository on the staging database. This step is needed only one time. Follow instructions from the eadam_readme.txt. Basically you need to execute eadam-master/stage_system/eadam_install.sql connected as SYS. This script asks for 4 parameters: Tablespace names for permanent and temporary schema objects, and the username and password of the new eAdam account. For the username I recommend eadam, but you can use any valid name.
- Load the data contained in the TAR file into the database. To do this you need first to copy the TAR file into the eadam-master/stage_system sub-directory and execute next the stage_system/eadam_load.sql script while on the stage_system sub-directory, and connecting as SYS. This script asks for 4 parameters. Pass first the directory path of your stage_system sub-directory, for example /home/oracle/eadam-master/stage_system (this sub-directory must contain the TAR file). Pass next the username and password of your eadam account as you created them. Pass last the name of the TAR file to be loaded into the database.
- The load process performs some data transformations and it produces at the end an output similar to eDB360 but smaller in content. After you review the eAdam output, you may decide to generate new output for shorter time series, in such case use the eadam-master/stage_system/eadam_report.sql connecting as the eadam user. This reporting process asks for 3 parameters. Pass the EADAM_SEQ_ID which identifies your particular load (a list of values is displayed), then pass the range of dates using format YYYY-MM-DD/HH24:MI, for example 2014-07-27/17:33.
Download
EADAM @ GitHub is available as free software. You can see its eadam_readme.txt, license.txt or any other piece of the tool before downloading it. Use this link eadam-master.zip to actually download eAdam as a compressed file.
Feedback
Please post your feedback about this eAdam tool at this blog, or send and email directly to the tool author: Carlos Sierra.
Enkitec’s free AWR data mining tool (eAdam) is now available!
As of today, you can download this free tool out of our Enkitec‘s web page. Just select “eAdam” under the Products Tab.
The next version of eAdam will incorporate the GV$views, equivalent to the currently extracted DBA_HIST set. The reason of this enhancement is to handle read-only databases (DataGuard – DG). So views like GV$ACTIVE_SESSION_HISTORY will be available for data mining within the eAdam staging repository.
Any ways, I hope you enjoy this new tool. Feel free to provide constructive feedback on this blog, or by sending an email to carlos.sierra@enkitec.com.
Meet: eAdam – Enkitec’s free AWR data mining tool
You recently learned about eDB360, and now eAdam? What is this eAdam tool? Before you continue reading, please be aware that eAdam reads data from AWR, thus you must have a license for the Oracle Diagnostics Pack in order to use this new eAdam tool.
Introduction
New eAdam is a free tool to perform data mining on performance related historical data recorded by AWR. The main characteristics of eAdam are:
- Installs nothing on the Source database (usually Production)
- Extracts AWR performance related data as plain text flat files (no export or data pump binary files)
- Upload extracted AWR data into a Staging database of same or different platform and release
- Data mining is performed on the Staging database instead of Production
How does eAdam work?
It is better to explain eAdam by functions. So I would say eAdam has the following 4 modules:
- AWR extraction from Source (Production)
- eAdam installation on Staging system
- Loading into eAdam Stage a set of AWR files extracted from Source
- AWR data mining on eAdam Stage
AWR extraction from Source (Production)
This is the simplest part. You just need to execute a simple and short script on a Source system (usually Production). This script extracts into flat files the content of the following AWR views. Then it compresses them into a TAR file. List below may expand over time as new eAdam versions become available.
DBA_HIST_ACTIVE_SESS_HISTORY
DBA_HIST_DATABASE_INSTANCE
DBA_HIST_DATAFILE
DBA_HIST_DLM_MISC
DBA_HIST_EVENT_HISTOGRAM
DBA_HIST_FILESTATXS
DBA_HIST_IOSTAT_DETAIL
DBA_HIST_IOSTAT_FILETYPE
DBA_HIST_IOSTAT_FUNCTION
DBA_HIST_OSSTAT
DBA_HIST_PGASTAT
DBA_HIST_SERVICE_STAT
DBA_HIST_SGA
DBA_HIST_SGASTAT
DBA_HIST_SNAPSHOT
DBA_HIST_SQL_PLAN
DBA_HIST_SQLSTAT
DBA_HIST_SQLTEXT
DBA_HIST_SYS_TIME_MODEL
DBA_HIST_SYSSTAT
DBA_HIST_SYSTEM_EVENT
DBA_HIST_TEMPFILE
DBA_HIST_TEMPSTATXS
eAdam installation on Staging system
You install eAdam once and then use it multiple times. If you download a newer version just install it on top of the prior one, so you get the eAdam delta. eAdam should be installed on a Staging database and not in Production or UAT. Pretty much any database could be your Staging database (QA or any other lower environment). It could even be a database on your laptop for example. Your Staging database does not have to be the same platform or database release than Source.
To install eAdam you simply execute another script. It creates a schema (you provide the name and password), and this script creates the eAdam repository on your Staging database.
Loading into eAdam Stage a set of AWR files extracted from Source
You can load into eAdam as many TAR files as you want. Each set is identified within eAdam with a sequence key. So your eAdam repository can contain AWR data from different systems, and they could be from same or different platforms and database releases. The data model of your eAdam repository is determined from your Staging database release, so it is ideal your Staging database is of equal or higher release than your Sources, but this is not mandatory.
To load a TAR file with AWR data into your Staging eAdam repository, you execute another script that asks for the TAR name and it produces a set of External Tables, then uploads the AWR data from the temporary external Tables into permanent staging Tables:
DBA_HIST_ACTIVE_SESS_HIST_S
DBA_HIST_DATABASE_INSTANC_S
DBA_HIST_DATAFILE_S
DBA_HIST_DLM_MISC_S
DBA_HIST_EVENT_HISTOGRAM_S
DBA_HIST_FILESTATXS_S
DBA_HIST_IOSTAT_DETAIL_S
DBA_HIST_IOSTAT_FILETYPE_S
DBA_HIST_IOSTAT_FUNCTION_S
DBA_HIST_OSSTAT_S
DBA_HIST_PGASTAT_S
DBA_HIST_SERVICE_STAT_S
DBA_HIST_SGASTAT_S
DBA_HIST_SGA_S
DBA_HIST_SNAPSHOT_S
DBA_HIST_SQLSTAT_S
DBA_HIST_SQLTEXT_S
DBA_HIST_SQL_PLAN_S
DBA_HIST_SYSSTAT_S
DBA_HIST_SYSTEM_EVENT_S
DBA_HIST_SYS_TIME_MODEL_S
DBA_HIST_TEMPFILE_S
DBA_HIST_TEMPSTATXS_S
DBA_HIST_XTR_CONTROL_S
DBA_TAB_COLUMNS_S
AWR Data mining on eAdam Stage
Once your AWR is available inside eAdam, you can perform all the Data Mining you may need. A sample script that produces several CSV files out of your data is provided. This sample script is automatically executed at the end of your upload, so you get a set of CSV files that can be used on Excel or any other tool that reads CSV files. I use Excel, where I can easily generate Charts out of the CSV files created by the sample script. That means I can easily visualize trends out of performance data without having access to the Source (Production) environment.
To produce the sample CSV files, eAdam provides a set of views on top of its own repository. These set of views will evolve over time as new releases become available. As of 1st release we provide the following views:
SH_AAS_APPLICATION_V1
ASH_AAS_CLUSTER_V1
ASH_AAS_COMMIT_V1
ASH_AAS_CONCURRENCY_V1
ASH_AAS_ON_CPU_V1
ASH_AAS_OTHER_V1
ASH_AAS_SCHEDULER_V1
ASH_AAS_TOTAL_V1
ASH_AAS_USER_IO_V1
ASH_INST_V1
ASH_RAC_V1
EVENT_HISTOGRAM_INST_V1
EVENT_HISTOGRAM_IO_RAC_V1
EVENT_HISTOGRAM_RAC_V1
EVENT_HISTOGRAM_RAC_V2
OSSTAT_BUSY_TIME_PERC_V1
OSSTAT_DELTA_V1
OSSTAT_INST_V1
OSSTAT_LOAD_V1
OSSTAT_RAC_V1
SYSTEM_EVENT_DELTA_V1
SYSTEM_EVENT_INST_V1
SYSTEM_EVENT_NON_IDLE_V1
SYSTEM_EVENT_RAC_V1
SYS_TIME_MODEL_DB_CPU_V3
SYS_TIME_MODEL_DB_TIME_V3
SYS_TIME_MODEL_DB_WAIT_V3
SYS_TIME_MODEL_DELTA_V1
SYS_TIME_MODEL_INST_V1
SYS_TIME_MODEL_RAC_V1
FAQ
Q1: Where can I download eAdam?
A1: From the Enkitec web page. Click on the “Products” tab. The tool will be available on March 7, 2014.
Q2: Is it really free?
A2: Yes. And before you ask what is the catch: “there is no catch”. Just be aware you must have an Oracle Diagnostics Pack license in order to access AWR data, and this eAdam tool is not an exception. Besides that, eAdam is free to download and use.
Q3: I need some extra functionality. How do I get it?
A3: If you need something that eAdam does not provide out of the box, of course you can extend its functionality directly. If the addition is something of general interest, you can submit an “Enhancement Request” (an email actually or a comment on this post). But it you want something more advanced and of particular use, you can contact Enkitec for a quote for this customization on top of eAdam (for example an Apex application).
Q4: Can I share this eAdam tool or its output?
A4: Sure you can. Just credit Enkitec for the tool. In other words, use it any way you want, but please honor authorship and ownership.
Q5: Who “owns” eAdam?
A5: Enkitec owns this new tool. Carlos Sierra is the author of eAdam, but the vision and some critical components were provided by: Frits Hoogland, Karl Arao and Randy Johnson. So eAdam is the product of a collaboration effort of some geeks working for Enkitec.
Conclusion
Enkitec is providing this eAdam tool for AWR Data Mining for free. Having an Oracle Diagnostics Pack is a must before using this tool. Besides that, feel free to use this tool at will, and perform all your AWR Data Mining outside the Source system, which is very important for a Production environment. This eAdam is very resource conscious on the Source system, and it empowers anyone to do performance analysis without having direct access to the Source database.
Having an AWR repository created with eAdam, enables many possibilities, like having baselines for particular processes, or compare performance between different time intervals (pre and post an application upgrade for example) or between two different systems (UAT and Production for example). If you already have a set of scripts to do data mining on DBA_HIST views, you can easily convert them to use the matching eAdam Staging tables so you would no longer be constrained to connect to the live system.
Performing Data Mining in entities like ASH as stored by AWR is like digging in a gold mine. There is so much the database wants to tell you. You just need this kind of of tool to listen carefully and find what is important.
