Archive for the ‘Installation’ Category
eDB360 meets eAdam 3.0 – when two heads are better than one!

Version v1711 of eDB360 invites eAdam 3.0 to the party. What does it mean? We recently learned that eDB360 v1706 introduced the eDB360 repository, which materialized the content of 26 core DBA_HIST views into a staging repository made of heap tables. This in order to expedite the execution of eDB360 on a database with an enlarged AWR. New version v1711 expands the list from 26 views to a total of 219. And these 219 views include now DBA_HIST, DBA, GV$ and V$.
Expanding existing eDB360 repository 8.4x from 26 to 219 views is not what is key on version v1710. The real impact of the latest version of eDB360 is that now it benefits of eAdam 3.0, providing the same benefits of the 219 views of the eDB360 heap-tables repository, but using External Tables, which are easily transported from a source database to a target database. This simple fact opens many doors.
Using the eAdam 3.0 repository from eDB360, we can now extract the metadata from a production database, then restore it on a staging database where we can produce the eDB360 report for the source database. We could also use this new external repository for: finer-granularity data mining; capacity planning; sizing for potential hardware refresh; provisioning tools; to estimate candidate segments for partitioning or for offloading into Hadoop; etc.
With the new external-tables eAdam 3.0 repository, we could easily build a permanent larger heap-table permanent repository for multiple databases (multiple tenants), or for multiple time versions of the same database. Thus, now that eDB360 has met eAdam 3.0, the combination of these two enables multiple innovative future features (custom or to be packaged and shipped with eDB360).
eDB360 recap
eDB360 is a free tool that gives a 360-degree view of an Oracle database. It installs nothing on the database, and it runs on 10g to 12c Oracle databases. It is designed for Linux and UNIX, but runs well on Windows as well (you may want to install first UNIX Utilities UnxUtils and a zip program, else a few OS commands may not properly work on Windows). This repository-less version is the default way to use eDB360, and is the right method for most cases. But now, in addition to the default use, eDB360 can also make use of one of two repositories.
eDB360 takes time to execute (several hours). It is designed to time-out after 24 hours by default. First reason for long execution times is the intentional serial-processing method used, with sequential execution of query after query, while consuming little resources. Such serial execution, plus the fact that it is common to have the tool execute on large databases where the state of AWR is suboptimal, causes the execution to take long. We often discover that source AWR repositories lack expected partitioning, and in many cases they hold years of data instead of expected 8 to 31 days. Therefore, the nature of serial-execution combined with enlarged and suboptimal AWR repositories, usually cause eDB360 to execute for many hours more than expected. With 8 to 31 days of AWR data, and when such reasonable history is well partitioned, eDB360 usually executes in less than 6 hours.
To overcome the undesired extended execution times of eDB360, and besides the obvious (partition and purge AWR), the tool provides the capability to execute in multiple threads splitting its content by column. And now, in addition to the divide-and-conquer approach of column execution, eDB360 provides 2 repositories with different objectives in mind:
- eDB360 repository: Use this method to create a staging repository based on heap tables inside the source database. This method helps to expedite the execution of eDB360 by at least 10x. Repository heap-tables are created and consumed inside the same database.
- eAdam3 repository: Use this method to generate a repository based on external tables on the source database. Such external-tables repository can be moved easily to a remote target system, allowing to efficiently generate the eDB360 report there. This method helps to reduce computations in the source database, and enables potential data mining on the external repository without any resources impact on the source database. This method also helps to build other functions on top of the 219-tables repository.
Views included on both eDB360 and eAdam3 repositories:
- dba_2pc_neighbors
- dba_2pc_pending
- dba_all_tables
- dba_audit_mgmt_config_params
- dba_autotask_client
- dba_autotask_client_history
- dba_cons_columns
- dba_constraints
- dba_data_files
- dba_db_links
- dba_extents
- dba_external_tables
- dba_feature_usage_statistics
- dba_free_space
- dba_high_water_mark_statistics
- dba_hist_active_sess_history
- dba_hist_database_instance
- dba_hist_event_histogram
- dba_hist_ic_client_stats
- dba_hist_ic_device_stats
- dba_hist_interconnect_pings
- dba_hist_memory_resize_ops
- dba_hist_memory_target_advice
- dba_hist_osstat
- dba_hist_parameter
- dba_hist_pgastat
- dba_hist_resource_limit
- dba_hist_seg_stat
- dba_hist_service_name
- dba_hist_sga
- dba_hist_sgastat
- dba_hist_snapshot
- dba_hist_sql_plan
- dba_hist_sqlstat
- dba_hist_sqltext
- dba_hist_sys_time_model
- dba_hist_sysmetric_history
- dba_hist_sysmetric_summary
- dba_hist_sysstat
- dba_hist_system_event
- dba_hist_tbspc_space_usage
- dba_hist_wr_control
- dba_ind_columns
- dba_ind_partitions
- dba_ind_statistics
- dba_ind_subpartitions
- dba_indexes
- dba_jobs
- dba_jobs_running
- dba_lob_partitions
- dba_lob_subpartitions
- dba_lobs
- dba_obj_audit_opts
- dba_objects
- dba_pdbs
- dba_priv_audit_opts
- dba_procedures
- dba_profiles
- dba_recyclebin
- dba_registry
- dba_registry_hierarchy
- dba_registry_history
- dba_registry_sqlpatch
- dba_role_privs
- dba_roles
- dba_rsrc_consumer_group_privs
- dba_rsrc_consumer_groups
- dba_rsrc_group_mappings
- dba_rsrc_io_calibrate
- dba_rsrc_mapping_priority
- dba_rsrc_plan_directives
- dba_rsrc_plans
- dba_scheduler_job_log
- dba_scheduler_jobs
- dba_scheduler_windows
- dba_scheduler_wingroup_members
- dba_segments
- dba_sequences
- dba_source
- dba_sql_patches
- dba_sql_plan_baselines
- dba_sql_plan_dir_objects
- dba_sql_plan_directives
- dba_sql_profiles
- dba_stat_extensions
- dba_stmt_audit_opts
- dba_synonyms
- dba_sys_privs
- dba_tab_cols
- dba_tab_columns
- dba_tab_modifications
- dba_tab_partitions
- dba_tab_privs
- dba_tab_statistics
- dba_tab_subpartitions
- dba_tables
- dba_tablespace_groups
- dba_tablespaces
- dba_temp_files
- dba_triggers
- dba_ts_quotas
- dba_unused_col_tabs
- dba_users
- dba_views
- gv$active_session_history
- gv$archive_dest
- gv$archived_log
- gv$asm_disk_iostat
- gv$database
- gv$dataguard_status
- gv$event_name
- gv$eventmetric
- gv$instance
- gv$instance_recovery
- gv$latch
- gv$license
- gv$managed_standby
- gv$memory_current_resize_ops
- gv$memory_dynamic_components
- gv$memory_resize_ops
- gv$memory_target_advice
- gv$open_cursor
- gv$osstat
- gv$parameter
- gv$pga_target_advice
- gv$pgastat
- gv$pq_slave
- gv$pq_sysstat
- gv$process
- gv$process_memory
- gv$px_buffer_advice
- gv$px_process
- gv$px_process_sysstat
- gv$px_session
- gv$px_sesstat
- gv$resource_limit
- gv$result_cache_memory
- gv$result_cache_statistics
- gv$rsrc_cons_group_history
- gv$rsrc_consumer_group
- gv$rsrc_plan
- gv$rsrc_plan_history
- gv$rsrc_session_info
- gv$rsrcmgrmetric
- gv$rsrcmgrmetric_history
- gv$segstat
- gv$services
- gv$session
- gv$session_blockers
- gv$session_wait
- gv$sga
- gv$sga_target_advice
- gv$sgainfo
- gv$sgastat
- gv$sql
- gv$sql_monitor
- gv$sql_plan
- gv$sql_shared_cursor
- gv$sql_workarea_histogram
- gv$sysmetric
- gv$sysmetric_summary
- gv$sysstat
- gv$system_parameter2
- gv$system_wait_class
- gv$temp_extent_pool
- gv$undostat
- gv$waitclassmetric
- gv$waitstat
- v$archive_dest_status
- v$archived_log
- v$ash_info
- v$asm_attribute
- v$asm_client
- v$asm_disk
- v$asm_disk_stat
- v$asm_diskgroup
- v$asm_diskgroup_stat
- v$asm_file
- v$asm_template
- v$backup
- v$backup_set_details
- v$block_change_tracking
- v$cell_config
- v$cell_state
- v$controlfile
- v$database
- v$database_block_corruption
- v$datafile
- v$flashback_database_log
- v$flashback_database_stat
- v$instance
- v$io_outlier
- v$iostat_file
- v$kernel_io_outlier
- v$lgwrio_outlier
- v$log
- v$log_history
- v$logfile
- v$mystat
- v$nonlogged_block
- v$option
- v$parallel_degree_limit_mth
- v$parameter
- v$pdbs
- v$recovery_area_usage
- v$recovery_file_dest
- v$restore_point
- v$rman_backup_job_details
- v$rman_output
- v$segstat
- v$spparameter
- v$standby_log
- v$sys_time_model
- v$sysaux_occupants
- v$system_parameter2
- v$tablespace
- v$tempfile
- v$thread
- v$version
Instructions to use eDB360 and eAdam3 repositories
Both repositories are implemented under the edb360-master/repo subdirectory. Each has a readme file, which explains how to create the repository, consume it and drop it. The eAdam3 repository also includes instructions how to clone an external-table-based eAdam repository into a heap-table-based eDB360 repository.
Executing eDB360 on the eDB360 repository is faster than executing it on the eAdam3 repository, while avoiding new bug 25802477. This new Oracle database bug inflicts compressed external-tables like the ones used by the eAdam3 repository.
If you use eDB360 or eAdam3 repositories and have questions or concerns, do not hesitate to contact the author.
eDB360 new features (March 2017)

As many of you know, eDB360 is a free tool that provides a 360-degree view of an Oracle database without any installation. A new version is available like once per month, but occasionally a large number of enhancements are implemented at once. This new release v1708 (March 25, 2017) includes several new features requested recently by some users of the tool, thus the need to blog about what is new:
- Reducing the scope of eDB360 is now possible without having to generate a custom configuration file. Prior to this version, if a user wanted to generate output for let’s say AWR reports only (section 7a), the tool needed a custom.sql file with line DEF edb360_sections = ‘7a’;. Then we would pass to edb360.sql as 2nd execution parameter the name of this custom configuration file (too cumbersome!). Starting on v1708, we can directly pass to edb360.sql the section that we desire (i.e. SQL> @edb360 T 7a). This 2nd parameter can either input the name of a custom configuration file (legacy functionality), but now it also accepts a column, a section, a list of columns or a list of sections; for example: 7a, 7, 7a-7b, 1-4 and 3 are all valid values.
- A couple of reports were added to section 3h: “SQL in logon storms” and “SQL executed row-by-row”. The former identifies those SQL statements that are seen frequently on very short-lived sessions (based on ASH), and the latter presents a list of SQL statements with large number of executions and small number of rows processed.
- eDB360 now extracts ASH from eAdam for top 16 SQL_ID (as per SQLd360 list) + top 12 SNAP_ID (as per AWR MAX from column 7a). What it means is that eDB360 includes now a tar file with raw ASH data for both: SQL statements of interest and for AWR periods of interest (both according to what eDB360 considers important). Using eAdam is easy, so when content of eDB360 does not include a very specific aggregation of ASH data that we need, or when we have to understand the sequence of some ASH samples for example, we can then restore this eAdam data on any Oracle database and data mine it.
- Some reports on section 2b show now totals at the bottom. That is to SUM some numeric values. Other reports may follow in future releases.
- RMAN section includes now a new report “Blocks with Corruption or Non-logged”.
- Added Load Profile (Per Sec, Per Txn and Count) as per DBA_HIST_SYSMETRIC_SUMMARY. This Load Profile resembles what we see on AWR at the top, but this is computed for the entire period of diagnostics (31 days by default). It shows max values, average, median and several percentiles. With this new report on section 1a, we can glance over it and discover in minutes some areas of further interest, for example: logons per second too high, just to mention one.
- There is a new section 4i with “Waits Count v.s. Average Latency for top 24 Wait Events”. With this set of 24 reports (one for each of the top wait events) we can observe if patterns on the number of counts relate to patterns on the latency for such wait event; for example we are able to see if an increase in the number of waits for db file sequential reads correlates to an increase of average latency for such wait event. We can also observe cases were latency for a wait event cannot be explained by load on current database, thus hinting an external influence.
- Fixed “ORA-01476: divisor is equal to zero” on planx at DBA_HIST_SQLSTAT.
- Added AWR DIFF reports for RAC and per instance. These are computed comparing MAX reports to MEDIAN reports, and they help to quickly identify large differences on load. These new AWR DIFF reports are regulated by configuration parameter edb360_conf_incl_addm_rpt (enabled by default). They exist on 11R2 and higher.
- Added the ASH Analytics Active report for 12c. This new ASH report is regulated by configuration parameter edb360_conf_incl_ash_analy_rpt (enabled by default). This applies to 12c and higher.
- The name of the database is now part of the main filename. Some users requested to include this database name as part of the main zip file since they are using eDB360 periodically on several databases. This new feature is regulated by configuration parameter edb360_conf_incl_dbname_file (disabled by default).
- At completion, main eDB360 zip file can now by automatically moved to a location other than the standard SQL*Plus working directory. All output files are still generated on the local SQL*Plus directory from where the script edb360.sql is executed (i.e. edb360-master directory), but at the completion of the execution the consolidated output zip file is now moved to a location specified by a new parameter. This new feature is regulated by configuration parameter edb360_move_directory (disabled by default).
- Added new report on “Database and Schema Triggers” under column 3h. This new report can be used to see potential LOGON or other global triggers. For triggers on specific tables, refer to SQLd360 which is automatically included on eDB360 for top SQL.
- All queries executed by eDB360 to generate its output were modified. New format is q'[query]’. Reason for this change is to improve readability of the code.
Always download and use the latest version of this tool. For questions or feedback email me. And I hope you get to enjoy eDB360 as much as I do!
eDB360 includes now an optional staging repository
eDB360 has always worked under the premise “no installation required”, and still is the case today – it is part of its fundamental essence: give me a 360-degree view of my Oracle database with no installation whatsoever. With that in mind, this free tool helps sites that have gone to the cloud, as well as those with “on-premises” databases; and in both cases not installing anything certainly expedites diagnostics collections. With eDB360, you simply connect to SQL*Plus with an account that can select from the catalog, execute then a set of scripts behind eDB360 and bingo!, you get to understand what is going on with your database just by navigating the html output. With such functionality, we can remotely diagnose a database, and even elaborate on the full health-check of it. After all, that is how we successfully use it every day!, saving us hundreds of hours of metadata gathering and cross-reference analysis.
Starting with release v1706, eDB360 also supports an optional staging repository of the 26 AWR views listed below. Why? the answer is simple: improved performance! This can be quite significant on large databases with hundreds of active sessions, with frequent snapshots, or with a long history on AWR. We have seen cases where years of data are “stuck” on AWR, specially in older releases of the database. Of course cleaning up the outdated AWR history (and corresponding statistics) is highly recommended, but in the meantime trying to execute edb360 on such databases may lead to long execution hours and frustration, taking sometimes days for what should take only a few hours.
- dba_hist_active_sess_history
- dba_hist_database_instance
- dba_hist_event_histogram
- dba_hist_ic_client_stats
- dba_hist_ic_device_stats
- dba_hist_interconnect_pings
- dba_hist_memory_resize_ops
- dba_hist_memory_target_advice
- dba_hist_osstat
- dba_hist_parameter
- dba_hist_pgastat
- dba_hist_resource_limit
- dba_hist_service_name
- dba_hist_sga
- dba_hist_sgastat
- dba_hist_sql_plan
- dba_hist_sqlstat
- dba_hist_sqltext
- dba_hist_sys_time_model
- dba_hist_sysmetric_history
- dba_hist_sysmetric_summary
- dba_hist_sysstat
- dba_hist_system_event
- dba_hist_tbspc_space_usage
- dba_hist_wr_control
- dba_hist_snapshot
Thus, if you are contemplating executing eDB360 on a large database, and provided pre-check script edb360-master/sql/awr_ash_pre_check.sql shows that eDB360 might take over 24 hours, then while you clean up your AWR repository you can use the eDB360 staging repository as a workaround to speedup eDB360 execution. The use of this optional staging repository is very simple, just look inside the edb360-master/repo directory for instructions. And as always, shoot me an email or comment here if there were any questions.
SQLTXPLAIN PL/SQL Public APIs to execute XTRACT from 3rd party tools
Many tools offer Public APIs, which expose some functionality to other tools. SQLTXPLAIN contains also some Public APIs. They are provided by package SQLTXADMIN.SQLT$E. I would say the most relevant one is XTRACT_SQL_PUT_FILES_IN_DIR. This blog post is about this Public API and how it can be used by other tools to execute a SQLT XTRACT from PL/SQL instead of SQL*Plus.
Imagine a tool that deals with SQL statements, and with the click of a button it invokes SQLTXTRACT on a SQL of interest, and after a few minutes, most files created by SQLTXTRACT suddenly show on an OS pre-defined directory. Implementing this SQLT functionality on an external tool is extremely easy as you will see below.
Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR inputs a SQL_ID and two other optional parameters: A tag to identify output files, and a directory name. Only SQL_ID parameter is mandatory, and the latter two are optional, but I recommend to pass values for all 3.
I used “Q1” as a tag to be included in all output files. And I used staging directory “FROG_DIR” at the database layer, which points to “/home/oracle/frog” at the OS layer.
On sample below, I show how to use this Public API for a particular SQL_ID “8u0n7w1jug5dg”. I call this API from SQL*Plus, but keep in mind that if I were to call it from within a tool’s PL/SQL library, the method would be the same.
Another consideration is that Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR may take several minutes to execute, so you may want to “queue” the request using a Task or a Job within the database. What is important here on this blog post is to explain and show how this Public API works.
SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR parameters:
Find below code snippet showing API Parameters. Notice this API is overloaded, so it may return the STATEMENT_ID or nothing. This STATEMENT_ID is the 5 digits number you see on each SQLT execution.
CREATE OR REPLACE PACKAGE &&tool_administer_schema..sqlt$e AUTHID CURRENT_USER AS
/* $Header: 215187.1 sqcpkge.pks 12.1.03 2013/10/10 carlos.sierra mauro.pagano $ */
/*************************************************************************************/
/* -------------------------
*
* public xtract_sql_put_files_in_dir
*
* executes sqlt xtract on a single sql then
* puts all generated files into an os directory,
* returning the sqlt statement id.
*
* ------------------------- */
FUNCTION xtract_sql_put_files_in_dir (
p_sql_id_or_hash_value IN VARCHAR2,
p_out_file_identifier IN VARCHAR2 DEFAULT NULL,
p_directory_name IN VARCHAR2 DEFAULT 'SQLT$STAGE' )
RETURN NUMBER;
/* -------------------------
*
* public xtract_sql_put_files_in_dir (overload)
*
* executes sqlt xtract on a single sql then
* puts all generated files into an os directory.
*
* ------------------------- */
PROCEDURE xtract_sql_put_files_in_dir (
p_sql_id_or_hash_value IN VARCHAR2,
p_out_file_identifier IN VARCHAR2 DEFAULT NULL,
p_directory_name IN VARCHAR2 DEFAULT 'SQLT$STAGE' );
Staging Directory
To implement Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR on your tool, you need first to create and test a staging directory where the API will write files. This directory needs to be accessible to the “oracle” account, so I show below how to create sample directory “frog” while connected to the OS as “oracle”.
Since the API uses UTL_FILE, it is important that “oracle” can write into it, so be sure you test this UTL_FILE write after you create the directory and before you test Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR.
Use code snippet provided below to test the UTL_FILE writing into this new staging OS directory.
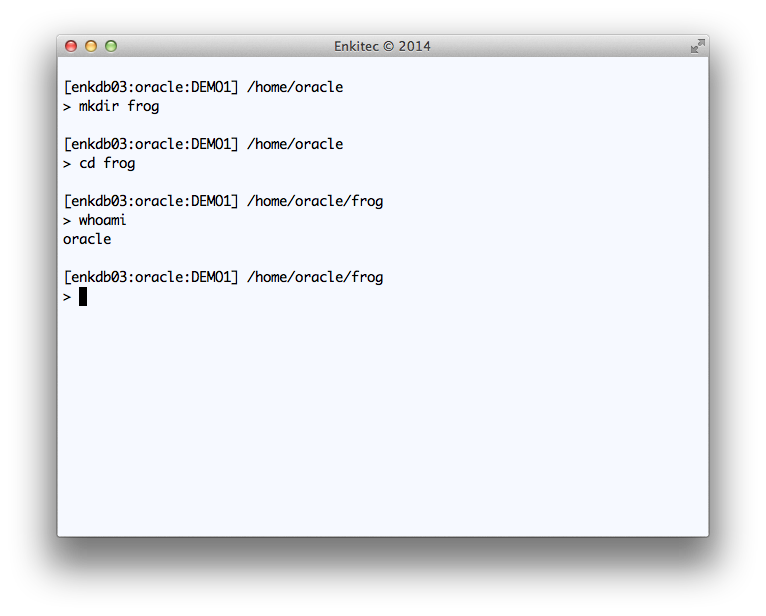
Creating “frog” OS directory connected to OS as “oracle”
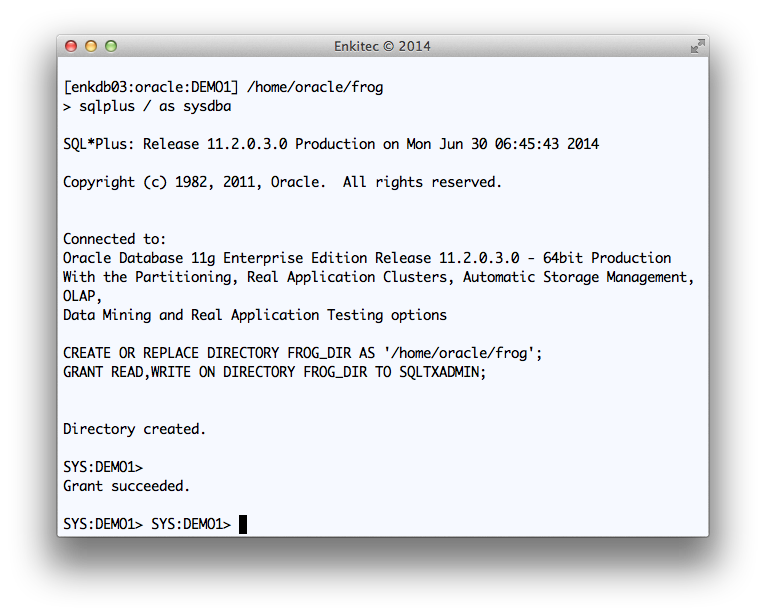
Creating FROG_DIR database directory and providing access to SQLTXADMIN
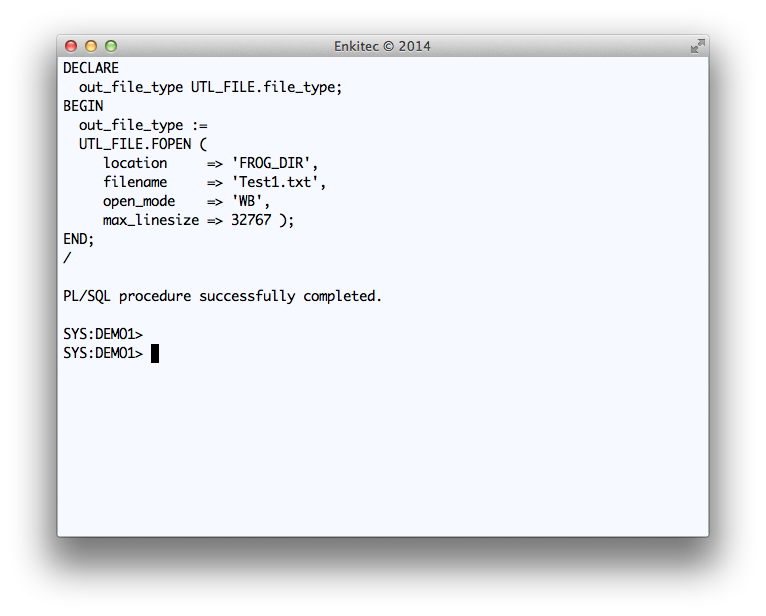
Testing a simple WRITE to FROG_DIR
DECLARE
out_file_type UTL_FILE.file_type;
BEGIN
out_file_type :=
UTL_FILE.FOPEN (
location => 'FROG_DIR',
filename => 'Test1.txt',
open_mode => 'WB',
max_linesize => 32767 );
END;
/
Executing SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR
On your tool, you can call this SQLT Public API from PL/SQL. You may want to use a Task or Job since the API may take several minutes to execute and you do not want the user to simply wait until SQLT completes.
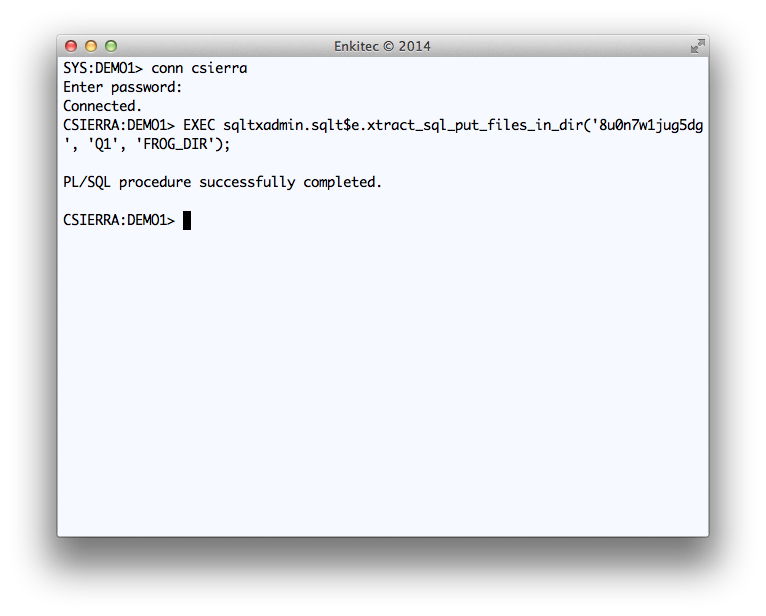
Execution of Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR
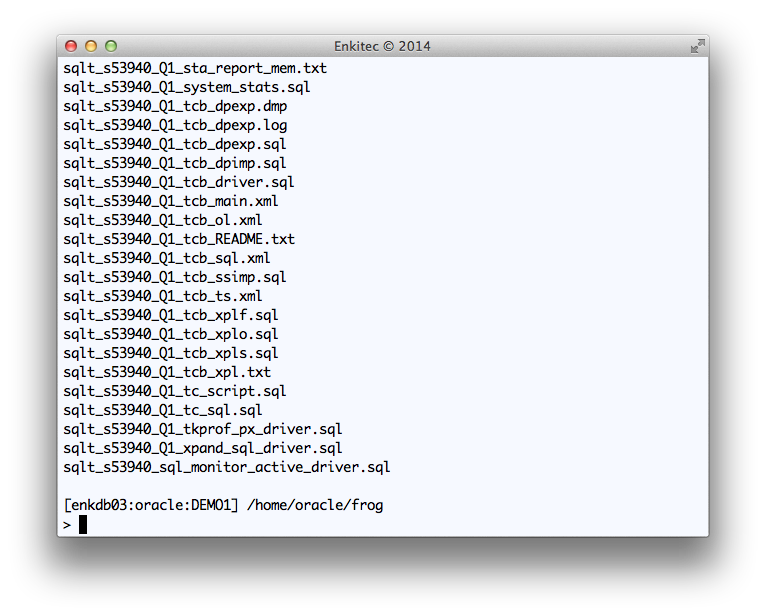
Reviewing the output of SQLT XTRACT for SQL_ID “8u0n7w1jug5dg”
Conclusion
Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR is available for any 3rd party tool to use. If SQLT has been pre-installed on a system where your tool executes, then calling this API as shown above, will generate a set of SQLT files on a pre-defined staging OS directory.
If the system where you install your tool does not have SQLT pre-installed, your tool can direct its users to download and install SQLT out of My Oracle Support (MOS) under document 215187.1.
Once you generate all these SQLT XTRACT files into an OS staging directory, you may want to zip them, or make them visible to your tool user. If the latter, then show the “main” html report.
SQLT is an Oracle community tool hosted at Oracle MOS under 215187.1. This tool is not supported, but if you have a question or struggle while implementing this Public API, feel free to shoot me an email or post your question/concern on this blog.
About AWR, SQLT and DB360
This blog posting is about answering this first question below, which I often get asked:
Can I use SQLTXPLAIN (SQLT) instead of AWR?
The answer is: it depends. If you are doing SQL Tuning and you already know the SQL_ID, then you may want to use SQLT XTRACT (MOS 215187.1) directly on the SQL_ID of concern. But even in that case, keep in mind that SQLT accesses AWR data, so your environment must have a valid license to use the Oracle Diagnostics Pack. In fact, when you install SQLT, it asks if you have the Oracle Tuning Pack, the Oracle Diagnostics Pack or none. Depending how you respond, SQLT access or not the set of views and APIs included on those Oracle Packs. That means you can configure SQLT to access or not AWR data.
What is the difference between AWR and SQLT?
In short, the difference between these two is the scope. You use AWR to diagnose database performance, while you use SQLT to diagnose one SQL. Sometimes I explain this difference by saying: “AWR is to an entire database to what SQLT is to one SQL”. One is for system-wide performance, the other is very centric to one SQL at a time.
Why SQLT exists?
I envisioned SQLT on the late 90’s when I was a road-warrior fighting fires in the area of performance, and in particular SQL performance. I found back then that Oracle-provided tools like TKPROF were excellent, but I always needed something more, like knowing the state of the CBO Statistics, Tables and Indexes, etc.
These days, my good friend Mauro Pagano from Oracle, is keeping the ball rolling. He is keeping SQLT in constant motion, making it a better tool on every new version. So, I would say this: SQLT is filling up some gaps that me, and many others, consider important in order to be diligent on root cause analysis for cases were a SQL performs poorly.
What is DB360?
As SQLT brings to the table several pieces of information that we need for SQL Tuning, and which are not available using out-of-the-box tools like TKPROF or SQL Monitoring, the new DB360 tool is doing something similar for the entire database: It complements what AWR provides by producing a report with meaningful information about an entire database. This DB360 is a tool that installs nothing on the database, and produces an HTML report with sections such as Configuration, Sizing, CBO Statistics, Performance Trends, etc.
Is DB360 a licensed product?
No. This DB360 tool belongs to Enkitec. It is not yet available to the Oracle community, but it will be soon. Same as SQLT, if you have an Oracle Tuning or Diagnostics Pack, then when you execute DB360 you would get to see in your DB360 report some pieces of information generated out of views and APIs covered by those Oracle Packs, else you get only the pieces which require no Oracle Pack license. Besides the restriction to limit your use of DB360 as per your Oracle Pack license, DB360 itself will be available to the Oracle community for free, and with no strings attached, same as SQLT.
Why are SQLT and DB360 free to download and use?
These tools are simply a contribution to the Oracle community. “Sharing tools is like sharing knowledge: it makes our IT experience more pleasurable”. The only payback comes when you share back with the Oracle community some of your knowledge, or some of your tools and scripts. If you have been a speaker in an Oracle Users Groups, then you may relate to this gratifying experience to share with others what you know. At RMOUG these past 3 days, I have had the opportunity to experience once again this special sense of community, that is always eager to share and to learn from each other.
Conclusion
SQLT complements TKPROF and SQL Monitor. DB360 complements AWR. When it comes to diagnostics, either for one SQL or for an entire Database, having to our disposal additional diagnostics in the context of our analysis, improves our chances to do a diligent job, while reducing the time that it would take to assembly those pieces manually; all with the extra benefit of having these extra diagnostics pieces consistent to a point in time. So, I hope you continue enjoying SQLT and in the near future DB360!
Displaying and fixing compilation errors on a SQLTXPLAIN package
If you are installing SQLTXPLAIN and for some reason you get a PL/SQL compilation error in a SQLT log like the one below, chances are the SHOW ERRORS command on SQL*Plus won’t show the actual error. This is because the installation connects as SYS and the packages are owned by SQLTXADMIN. In most cases the cause of the error is missing a GRANT or a SYNONYM in libraries called by SQLT like DBMS_METADATA or UTL_FILE.
... creating package body for SQLT$R Warning: Package Body created with compilation errors. No errors. ... SELECT column_value libraries FROM TABLE(SQLTXADMIN.sqlt$r.libraries_versions) ERROR at line 1: ORA-04063: package body "SQLTXADMIN.SQLT$R" has errors
How to display PL/SQL package compilation error on SQLTXPLAIN
You may need to unlock the schema owner of SQLT packages and compile the invalid object connecting as this SQLTXADMIN account, then lock it back. By following steps below you will get to see the actual compile error. Then proceed to fix it and recompile the invalid package body. If it is a missing GRANT/SYNONYM you may want to create the GRANT EXECUTE of the SYS library to SQLTXADMIN then create a SYNONYM with same name (not a PUBLIC SYNONYM). Ex: GRANT EXECUTE ON SYS.DBMS_METADATA TO SQLTXADMIN; CREATE SYNONYM SQLTXADMIN.DBMS_METADATA FOR SYS.DBMS_METADATA;
$ cd sqlt/install $ sqlplus / AS SYSDBA -- SQL> SELECT object_name, object_type FROM dba_objects WHERE owner = 'SQLTXADMIN' AND object_type LIKE 'PACKAGE%' AND status = 'INVALID'; SQL> START sqcommon1.sql SQL> GRANT CREATE SESSION TO sqltxadmin; SQL> ALTER USER sqltxadmin IDENTIFIED BY &&password. ACCOUNT UNLOCK; SQL> CONN sqltxadmin/&&password.; -- -- compile invalid packages as per query output above -- SQL> ALTER PACKAGE sqlt$m COMPILE; SQL> ALTER PACKAGE sqlt$r COMPILE; -- -- fix root cause of error -- SQL> CONN / AS SYSDBA SQL> REVOKE CREATE SESSION FROM sqltxadmin; SQL> ALTER USER sqltxadmin PASSWORD EXPIRE ACCOUNT LOCK;
How to diagnose a SQLTXPLAIN installation failure
SQLTXPLAIN is easy to install. Yes, unless you hit a rock! So, if you are trying to install SQLT and you do not see the message that reads “SQCREATE completed. Installation completed successfully.” then something went bad. First, you have to identify if the reason was captured by SQLT or not. In other words, if it was captured by SQLT you will see in your screen that your session ended normally. If it was not trapped by SQLT you will see an error like ORA-07445 or ORA-03113 and a statement that says something like “end-of-file on communication channel”. In such case SQLT could not trap the error.
Session ends normally
If you do not see an “end-of-file on communication channel” and your session were you were installing SQLT seems to have exited normally (but without displaying “SQCREATE completed. Installation completed successfully.”) , then look at your current SQL*Plus directory (“HOS ls” OR “HOS dir”)and look for a log file “YYMMDDHH24MISS_NN_%.log”. This file should contain your error. In some cases you have to look also at the most recent file(s) inside the SQLT archive SQLT_installation_logs_archive.zip which is generated into same local directory. Typical cases of an error of this type are:
- Invalid Tablespace name was indicated
- Tablespace running out of space
- A SYS owned package is missing or its execute grants are missing: DBMS_METADATA and UTL_FILE are the most common ones
- UTL_FILE_DIR has a value but it does not include the path for traces (USER_DUMP_DEST)
In any case, once you locate the error it is just a matter of taking a corrective action and re-installing SQLT. But if you see a package body has errors but the error is not displayed in any of the log file (specially on the one with name like 130515065531_08_sqcpkg.log) then you may need to do this: unlock and reset pwd for SQLTXADMIN then try an alter package compile connected as SQLTXADMIN. Once you see the error then you can fix it.
Session disconnects abnormally
This kind of problem is a bit more complicated. If you see an ORA-07445 or ORA-03113 or “end-of-file on communication channel” then it means SQLT could not trap the error and you have to look for it inside the alert log. It also means that your problem is not derived from SQLT, but SQLT is simply a victim of it. You may find more information in your alert log, and you will see references to some traces. Look for those traces and review the upper part of those files. They should show a stack of calls and some keywords associated to your error. You can either research for those keywords on your own, or report to Oracle the errors you see in the alert log. Again, at this point the problem is not SQLT but something else in your server code that happens to affect SQLT. Since the skills to diagnose a server problem are not the same as those needed to diagnose a SQLT installation issue, be sure to document clearly what is the problem you see. This type of disconnect is a server problem, the former is a SQLT problem.
I do not have a typical list for this type since possibilities are many. You may find an ORA-00600 or something else. What I have seen recently are problems around the use of NATIVE for plsql_code_type. This change was introduced a few SQLT versions back and some customers have reported installation issues. If you see on your errors something that suggests PLSQL, then you may want to modify line 29 of the sqlt/install/sqcommon1.sql script, removing the “–” at the beginning of this line: DEF plsql_code_type = ‘INTERPRETED’;. In other words, un-comment this command. Then re-install SQLT. This action would reverse the use of plsql_code_type to less efficient INTERPRETED mode, but may workaround your plsql error.
Last resource
If you have don’t your best effort to locate the error and to fix the root cause, but nothing seems to work, then you have two more options:
- If SQLT was requested by someone else, please contact that requester (it could be Oracle Support or a business partner) and report the issue. This person may be able to help you directly; OR
- If you are the requester mentioned above, or there is no one else to go, then look in the sqlt/sqlt_instructions.html file for the primary and secondary contacts for this tool (documented starting on version 11.4.5.9 of the tool).
SQLT installs with no issues most of the times, but if it fails to install in a particular system, you are not on your own. Do your best to find the root cause, then ask for help if needed. Be prepared to provide any log file created in your local SQL*Plus directory PLUS the SQLT archived logs; and in cases of disconnects collect also the alert log and the traces referenced directly by the corresponding error on the alert.
