Archive for the ‘SQLT Repository’ Category
SQLTXPLAIN PL/SQL Public APIs to execute XTRACT from 3rd party tools
Many tools offer Public APIs, which expose some functionality to other tools. SQLTXPLAIN contains also some Public APIs. They are provided by package SQLTXADMIN.SQLT$E. I would say the most relevant one is XTRACT_SQL_PUT_FILES_IN_DIR. This blog post is about this Public API and how it can be used by other tools to execute a SQLT XTRACT from PL/SQL instead of SQL*Plus.
Imagine a tool that deals with SQL statements, and with the click of a button it invokes SQLTXTRACT on a SQL of interest, and after a few minutes, most files created by SQLTXTRACT suddenly show on an OS pre-defined directory. Implementing this SQLT functionality on an external tool is extremely easy as you will see below.
Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR inputs a SQL_ID and two other optional parameters: A tag to identify output files, and a directory name. Only SQL_ID parameter is mandatory, and the latter two are optional, but I recommend to pass values for all 3.
I used “Q1” as a tag to be included in all output files. And I used staging directory “FROG_DIR” at the database layer, which points to “/home/oracle/frog” at the OS layer.
On sample below, I show how to use this Public API for a particular SQL_ID “8u0n7w1jug5dg”. I call this API from SQL*Plus, but keep in mind that if I were to call it from within a tool’s PL/SQL library, the method would be the same.
Another consideration is that Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR may take several minutes to execute, so you may want to “queue” the request using a Task or a Job within the database. What is important here on this blog post is to explain and show how this Public API works.
SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR parameters:
Find below code snippet showing API Parameters. Notice this API is overloaded, so it may return the STATEMENT_ID or nothing. This STATEMENT_ID is the 5 digits number you see on each SQLT execution.
CREATE OR REPLACE PACKAGE &&tool_administer_schema..sqlt$e AUTHID CURRENT_USER AS
/* $Header: 215187.1 sqcpkge.pks 12.1.03 2013/10/10 carlos.sierra mauro.pagano $ */
/*************************************************************************************/
/* -------------------------
*
* public xtract_sql_put_files_in_dir
*
* executes sqlt xtract on a single sql then
* puts all generated files into an os directory,
* returning the sqlt statement id.
*
* ------------------------- */
FUNCTION xtract_sql_put_files_in_dir (
p_sql_id_or_hash_value IN VARCHAR2,
p_out_file_identifier IN VARCHAR2 DEFAULT NULL,
p_directory_name IN VARCHAR2 DEFAULT 'SQLT$STAGE' )
RETURN NUMBER;
/* -------------------------
*
* public xtract_sql_put_files_in_dir (overload)
*
* executes sqlt xtract on a single sql then
* puts all generated files into an os directory.
*
* ------------------------- */
PROCEDURE xtract_sql_put_files_in_dir (
p_sql_id_or_hash_value IN VARCHAR2,
p_out_file_identifier IN VARCHAR2 DEFAULT NULL,
p_directory_name IN VARCHAR2 DEFAULT 'SQLT$STAGE' );
Staging Directory
To implement Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR on your tool, you need first to create and test a staging directory where the API will write files. This directory needs to be accessible to the “oracle” account, so I show below how to create sample directory “frog” while connected to the OS as “oracle”.
Since the API uses UTL_FILE, it is important that “oracle” can write into it, so be sure you test this UTL_FILE write after you create the directory and before you test Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR.
Use code snippet provided below to test the UTL_FILE writing into this new staging OS directory.
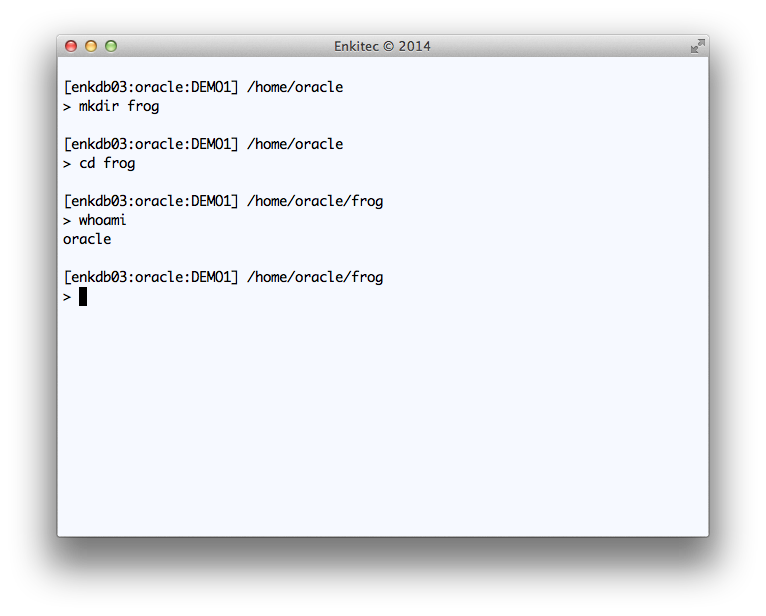
Creating “frog” OS directory connected to OS as “oracle”
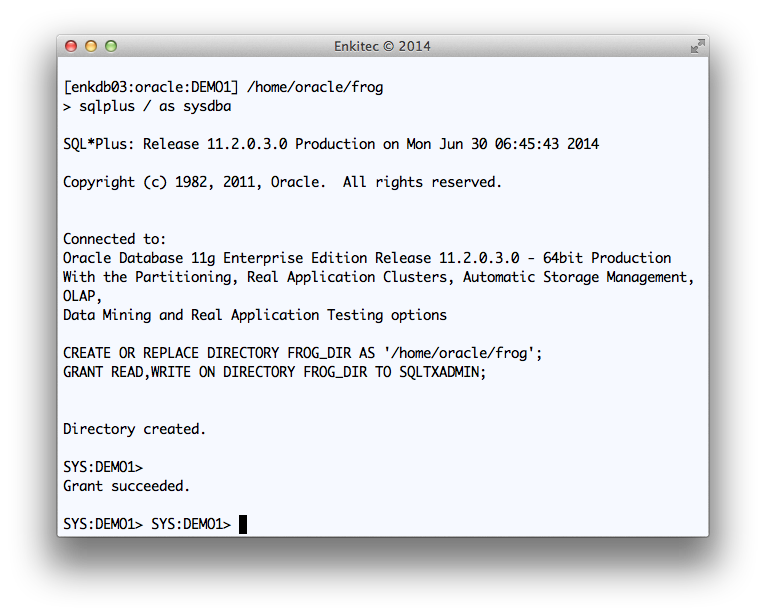
Creating FROG_DIR database directory and providing access to SQLTXADMIN
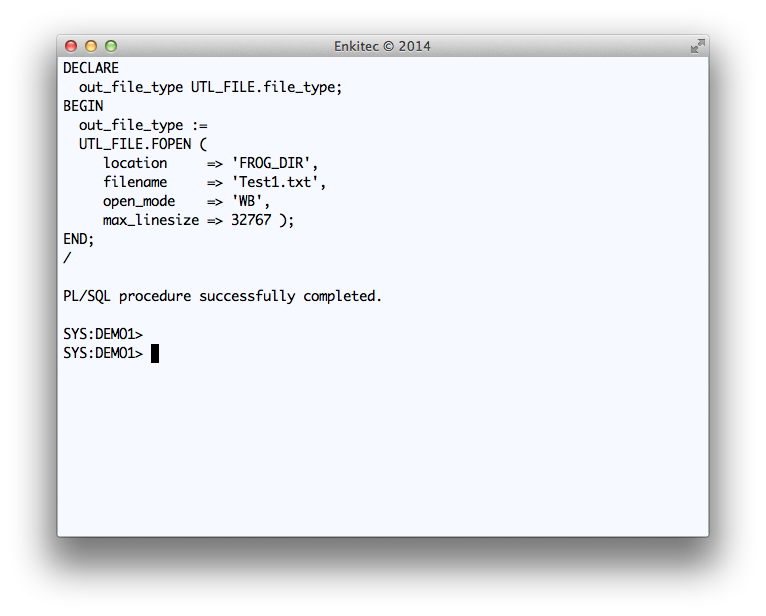
Testing a simple WRITE to FROG_DIR
DECLARE
out_file_type UTL_FILE.file_type;
BEGIN
out_file_type :=
UTL_FILE.FOPEN (
location => 'FROG_DIR',
filename => 'Test1.txt',
open_mode => 'WB',
max_linesize => 32767 );
END;
/
Executing SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR
On your tool, you can call this SQLT Public API from PL/SQL. You may want to use a Task or Job since the API may take several minutes to execute and you do not want the user to simply wait until SQLT completes.
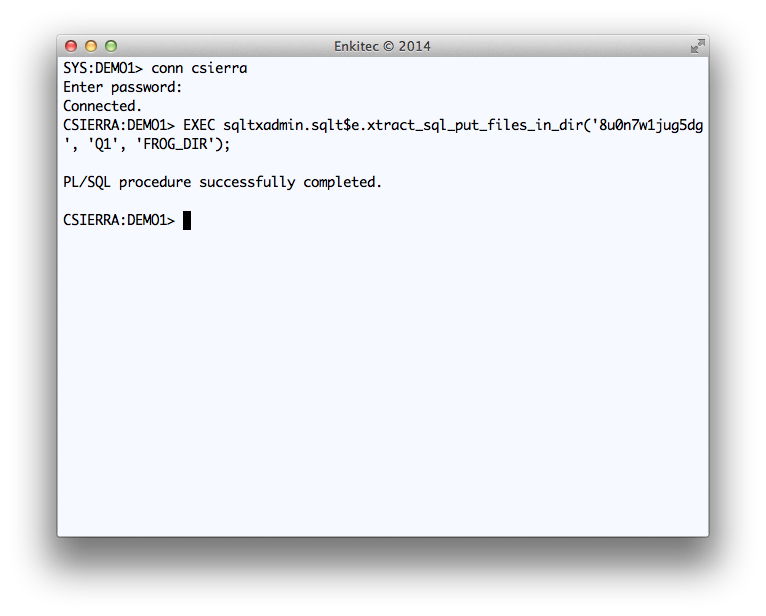
Execution of Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR
Reviewing the output of SQLT XTRACT for SQL_ID “8u0n7w1jug5dg”
Conclusion
Public API SQLTXADMIN.SQLT$E.XTRACT_SQL_PUT_FILES_IN_DIR is available for any 3rd party tool to use. If SQLT has been pre-installed on a system where your tool executes, then calling this API as shown above, will generate a set of SQLT files on a pre-defined staging OS directory.
If the system where you install your tool does not have SQLT pre-installed, your tool can direct its users to download and install SQLT out of My Oracle Support (MOS) under document 215187.1.
Once you generate all these SQLT XTRACT files into an OS staging directory, you may want to zip them, or make them visible to your tool user. If the latter, then show the “main” html report.
SQLT is an Oracle community tool hosted at Oracle MOS under 215187.1. This tool is not supported, but if you have a question or struggle while implementing this Public API, feel free to shoot me an email or post your question/concern on this blog.
About SQLT Repository
SQLTXPLAIN maintains a repository of metadata associated to a SQL statement being analyzed. A subset of this SQLT repository is automatically exported every time one of the main methods (like XTRACT) is used. A question sometimes I get is: what do you do with this SQLT repository? Well, in most cases: nothing. That is because most of the diagnostics we need are already included in the main report. But in some very particular cases we may want to dig into the SQLT repository. For example, in a recent case I wanted to understand some patterns about a particular wait event that happen to become “slower” after the application of an Exadata patch. Then, when IO Resource Manager IORM was configured from Basic to Auto, these waits became “fast” again. How to measure that? How to observe any trends and correlated to the times when the patch was applied and then when the IORM was adjusted? Fortunately SQLT had been used, and it captured ASH data out of AWR before it aged out. So I was able to use it in order to get to “see” these trends below.
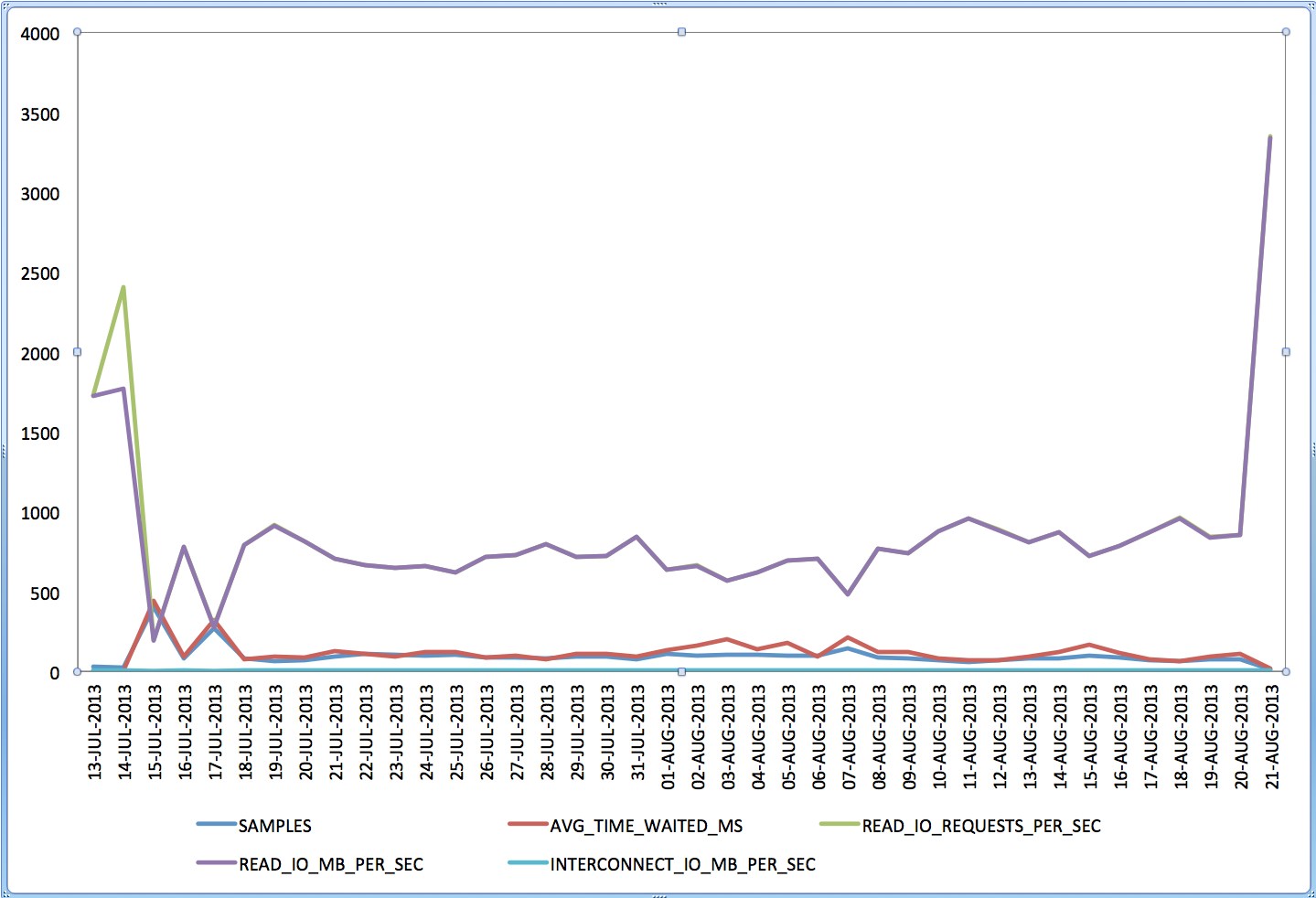
Now the question becomes: How do I produce this kind of graph? Well, with Excel it is easy, we just need to bring the piece of the SQLT repository that we want into Excel. For that, I first import the whole SQLT repository for a given sqlt_sNNNNN_*.zip file into my local SQLT repository. The command is spelled out in the sqlt_sNNNNN_readme.html as “import SQLT repository”, then I just use SQL Developer to export the output of a query into XLS (or CSV). In this case the SQL I used was the one below.
If you try to use the SQLT repository for some similar data analysis and you struggle with it, please let me know and I will help you out.
WITH awr_ash AS ( SELECT DISTINCT -- two or more statements can include same snaps sample_time, sql_plan_hash_value, sql_plan_line_id, wait_class, event, time_waited, ROUND(time_waited / 1e3) time_waited_ms, current_obj#, machine, delta_time, delta_read_io_requests, delta_write_io_requests, delta_read_io_bytes, delta_write_io_bytes, delta_interconnect_io_bytes, ROUND(delta_read_io_requests / (delta_time / 1e6)) read_io_requests_per_sec, ROUND(delta_write_io_requests / (delta_time / 1e6)) write_io_requests_per_sec, ROUND(delta_read_io_bytes / (delta_time / 1e6)) read_io_bytes_per_sec, ROUND(delta_write_io_bytes / (delta_time / 1e6)) write_io_bytes_per_sec, ROUND(delta_interconnect_io_bytes / (delta_time / 1e6)) interconnect_io_bytes_per_sec FROM sqlt$_dba_hist_active_sess_his WHERE statement_id IN (90959, 90960, 90962, 90963) AND session_state = 'WAITING' AND time_waited > 0 AND delta_time > 0 AND wait_class IS NOT NULL ), awr_ash_grp AS ( SELECT TRUNC(sample_time) sample_day, event, COUNT(*) samples, ROUND(AVG(time_waited_ms)) avg_time_waited_ms, ROUND(AVG(read_io_requests_per_sec)) read_io_requests_per_sec, ROUND(AVG(write_io_requests_per_sec)) write_io_requests_per_sec, ROUND(AVG(read_io_bytes_per_sec)) read_io_bytes_per_sec, ROUND(AVG(write_io_bytes_per_sec)) write_io_bytes_per_sec, ROUND(AVG(interconnect_io_bytes_per_sec)) interconnect_io_bytes_per_sec FROM awr_ash GROUP BY TRUNC(sample_time), event ), cell_smart_reads AS ( SELECT sample_day, TO_CHAR(sample_day, 'DD-MON-YYYY') sample_date, samples, avg_time_waited_ms, read_io_requests_per_sec, read_io_bytes_per_sec, ROUND(read_io_bytes_per_sec / (1024 * 1024)) read_io_mb_per_sec, interconnect_io_bytes_per_sec, ROUND(interconnect_io_bytes_per_sec / (1024 * 1024), 1) interconnect_io_mb_per_sec FROM awr_ash_grp WHERE event = 'cell smart table scan' ) SELECT sample_date, samples, avg_time_waited_ms, read_io_requests_per_sec, read_io_mb_per_sec, interconnect_io_mb_per_sec FROM cell_smart_reads ORDER BY sample_day;
