Archive for the ‘edb360’ Category
Introducing SQLdb360: merging eDB360 and SQLd360, while rising the bar to community engagement
Today, we are very happy to release SQLdb360, a new tool that merges together eDB360 and SQLd360, under a single package.
Tools eDB360 and SQLd360 can still be used independently, but now there is only one package to download and keep updated. All the new features and updates to both tools are now in that one package.
The biggest change that comes with SQLdb360 is the kind invitation to everyone interested to contribute to its development. This is why the new blended name and its release format.
We do encourage your help and ideas to continue building a free, open-source, and hopefully a YMMV great tool!
Over the years, a few community members requested new features, but they were ultimately slowed down by our speed of reaction to their requests. Well, no more!
Few consumers of these tools implemented cool changes they needed, sometimes sending us the changes (or pull requests) until a later time. This means good ideas were available to others after some time. Not anymore!
If there is something you’d like to have as part of SQLdb360 (aka SQLd360 and eDB360), just write and test the additional code, then send us the pull request! Next, we will review, validate, and merge your code changes to the main tool.
There are several advantages to this new approach:
- Carlos and Mauro won’t dictate the direction of the tool anymore: we will continue helping and contributing, but we won’t “own” it anymore (the community will!)
- Carlos and Mauro won’t slow down the development anymore: nobody is the bottleneck now!
- Carlos and Mauro wan’t run out of ideas anymore!!! The community has great ideas to share!!!
Due to the nature of this new collaborative effort, the way we now publish SQLdb360 is this:
- Instead of linking to the current master repository, the tool now implements “releases”. This, in order to snapshot stable versions that bundle several changes together (better than creating separate versions per merge into master).
- Links in our blogs are now getting updated, with references to the latest (and current) stable release of SQLdb360 (starting with v18.1).
Note: Version names sound awfully familiar to Oracle nomenclature, right? Well, we started using this numbering back in 2014!!!
Carlos & Mauro
eDB360 meets eAdam 3.0 – when two heads are better than one!

Version v1711 of eDB360 invites eAdam 3.0 to the party. What does it mean? We recently learned that eDB360 v1706 introduced the eDB360 repository, which materialized the content of 26 core DBA_HIST views into a staging repository made of heap tables. This in order to expedite the execution of eDB360 on a database with an enlarged AWR. New version v1711 expands the list from 26 views to a total of 219. And these 219 views include now DBA_HIST, DBA, GV$ and V$.
Expanding existing eDB360 repository 8.4x from 26 to 219 views is not what is key on version v1710. The real impact of the latest version of eDB360 is that now it benefits of eAdam 3.0, providing the same benefits of the 219 views of the eDB360 heap-tables repository, but using External Tables, which are easily transported from a source database to a target database. This simple fact opens many doors.
Using the eAdam 3.0 repository from eDB360, we can now extract the metadata from a production database, then restore it on a staging database where we can produce the eDB360 report for the source database. We could also use this new external repository for: finer-granularity data mining; capacity planning; sizing for potential hardware refresh; provisioning tools; to estimate candidate segments for partitioning or for offloading into Hadoop; etc.
With the new external-tables eAdam 3.0 repository, we could easily build a permanent larger heap-table permanent repository for multiple databases (multiple tenants), or for multiple time versions of the same database. Thus, now that eDB360 has met eAdam 3.0, the combination of these two enables multiple innovative future features (custom or to be packaged and shipped with eDB360).
eDB360 recap
eDB360 is a free tool that gives a 360-degree view of an Oracle database. It installs nothing on the database, and it runs on 10g to 12c Oracle databases. It is designed for Linux and UNIX, but runs well on Windows as well (you may want to install first UNIX Utilities UnxUtils and a zip program, else a few OS commands may not properly work on Windows). This repository-less version is the default way to use eDB360, and is the right method for most cases. But now, in addition to the default use, eDB360 can also make use of one of two repositories.
eDB360 takes time to execute (several hours). It is designed to time-out after 24 hours by default. First reason for long execution times is the intentional serial-processing method used, with sequential execution of query after query, while consuming little resources. Such serial execution, plus the fact that it is common to have the tool execute on large databases where the state of AWR is suboptimal, causes the execution to take long. We often discover that source AWR repositories lack expected partitioning, and in many cases they hold years of data instead of expected 8 to 31 days. Therefore, the nature of serial-execution combined with enlarged and suboptimal AWR repositories, usually cause eDB360 to execute for many hours more than expected. With 8 to 31 days of AWR data, and when such reasonable history is well partitioned, eDB360 usually executes in less than 6 hours.
To overcome the undesired extended execution times of eDB360, and besides the obvious (partition and purge AWR), the tool provides the capability to execute in multiple threads splitting its content by column. And now, in addition to the divide-and-conquer approach of column execution, eDB360 provides 2 repositories with different objectives in mind:
- eDB360 repository: Use this method to create a staging repository based on heap tables inside the source database. This method helps to expedite the execution of eDB360 by at least 10x. Repository heap-tables are created and consumed inside the same database.
- eAdam3 repository: Use this method to generate a repository based on external tables on the source database. Such external-tables repository can be moved easily to a remote target system, allowing to efficiently generate the eDB360 report there. This method helps to reduce computations in the source database, and enables potential data mining on the external repository without any resources impact on the source database. This method also helps to build other functions on top of the 219-tables repository.
Views included on both eDB360 and eAdam3 repositories:
- dba_2pc_neighbors
- dba_2pc_pending
- dba_all_tables
- dba_audit_mgmt_config_params
- dba_autotask_client
- dba_autotask_client_history
- dba_cons_columns
- dba_constraints
- dba_data_files
- dba_db_links
- dba_extents
- dba_external_tables
- dba_feature_usage_statistics
- dba_free_space
- dba_high_water_mark_statistics
- dba_hist_active_sess_history
- dba_hist_database_instance
- dba_hist_event_histogram
- dba_hist_ic_client_stats
- dba_hist_ic_device_stats
- dba_hist_interconnect_pings
- dba_hist_memory_resize_ops
- dba_hist_memory_target_advice
- dba_hist_osstat
- dba_hist_parameter
- dba_hist_pgastat
- dba_hist_resource_limit
- dba_hist_seg_stat
- dba_hist_service_name
- dba_hist_sga
- dba_hist_sgastat
- dba_hist_snapshot
- dba_hist_sql_plan
- dba_hist_sqlstat
- dba_hist_sqltext
- dba_hist_sys_time_model
- dba_hist_sysmetric_history
- dba_hist_sysmetric_summary
- dba_hist_sysstat
- dba_hist_system_event
- dba_hist_tbspc_space_usage
- dba_hist_wr_control
- dba_ind_columns
- dba_ind_partitions
- dba_ind_statistics
- dba_ind_subpartitions
- dba_indexes
- dba_jobs
- dba_jobs_running
- dba_lob_partitions
- dba_lob_subpartitions
- dba_lobs
- dba_obj_audit_opts
- dba_objects
- dba_pdbs
- dba_priv_audit_opts
- dba_procedures
- dba_profiles
- dba_recyclebin
- dba_registry
- dba_registry_hierarchy
- dba_registry_history
- dba_registry_sqlpatch
- dba_role_privs
- dba_roles
- dba_rsrc_consumer_group_privs
- dba_rsrc_consumer_groups
- dba_rsrc_group_mappings
- dba_rsrc_io_calibrate
- dba_rsrc_mapping_priority
- dba_rsrc_plan_directives
- dba_rsrc_plans
- dba_scheduler_job_log
- dba_scheduler_jobs
- dba_scheduler_windows
- dba_scheduler_wingroup_members
- dba_segments
- dba_sequences
- dba_source
- dba_sql_patches
- dba_sql_plan_baselines
- dba_sql_plan_dir_objects
- dba_sql_plan_directives
- dba_sql_profiles
- dba_stat_extensions
- dba_stmt_audit_opts
- dba_synonyms
- dba_sys_privs
- dba_tab_cols
- dba_tab_columns
- dba_tab_modifications
- dba_tab_partitions
- dba_tab_privs
- dba_tab_statistics
- dba_tab_subpartitions
- dba_tables
- dba_tablespace_groups
- dba_tablespaces
- dba_temp_files
- dba_triggers
- dba_ts_quotas
- dba_unused_col_tabs
- dba_users
- dba_views
- gv$active_session_history
- gv$archive_dest
- gv$archived_log
- gv$asm_disk_iostat
- gv$database
- gv$dataguard_status
- gv$event_name
- gv$eventmetric
- gv$instance
- gv$instance_recovery
- gv$latch
- gv$license
- gv$managed_standby
- gv$memory_current_resize_ops
- gv$memory_dynamic_components
- gv$memory_resize_ops
- gv$memory_target_advice
- gv$open_cursor
- gv$osstat
- gv$parameter
- gv$pga_target_advice
- gv$pgastat
- gv$pq_slave
- gv$pq_sysstat
- gv$process
- gv$process_memory
- gv$px_buffer_advice
- gv$px_process
- gv$px_process_sysstat
- gv$px_session
- gv$px_sesstat
- gv$resource_limit
- gv$result_cache_memory
- gv$result_cache_statistics
- gv$rsrc_cons_group_history
- gv$rsrc_consumer_group
- gv$rsrc_plan
- gv$rsrc_plan_history
- gv$rsrc_session_info
- gv$rsrcmgrmetric
- gv$rsrcmgrmetric_history
- gv$segstat
- gv$services
- gv$session
- gv$session_blockers
- gv$session_wait
- gv$sga
- gv$sga_target_advice
- gv$sgainfo
- gv$sgastat
- gv$sql
- gv$sql_monitor
- gv$sql_plan
- gv$sql_shared_cursor
- gv$sql_workarea_histogram
- gv$sysmetric
- gv$sysmetric_summary
- gv$sysstat
- gv$system_parameter2
- gv$system_wait_class
- gv$temp_extent_pool
- gv$undostat
- gv$waitclassmetric
- gv$waitstat
- v$archive_dest_status
- v$archived_log
- v$ash_info
- v$asm_attribute
- v$asm_client
- v$asm_disk
- v$asm_disk_stat
- v$asm_diskgroup
- v$asm_diskgroup_stat
- v$asm_file
- v$asm_template
- v$backup
- v$backup_set_details
- v$block_change_tracking
- v$cell_config
- v$cell_state
- v$controlfile
- v$database
- v$database_block_corruption
- v$datafile
- v$flashback_database_log
- v$flashback_database_stat
- v$instance
- v$io_outlier
- v$iostat_file
- v$kernel_io_outlier
- v$lgwrio_outlier
- v$log
- v$log_history
- v$logfile
- v$mystat
- v$nonlogged_block
- v$option
- v$parallel_degree_limit_mth
- v$parameter
- v$pdbs
- v$recovery_area_usage
- v$recovery_file_dest
- v$restore_point
- v$rman_backup_job_details
- v$rman_output
- v$segstat
- v$spparameter
- v$standby_log
- v$sys_time_model
- v$sysaux_occupants
- v$system_parameter2
- v$tablespace
- v$tempfile
- v$thread
- v$version
Instructions to use eDB360 and eAdam3 repositories
Both repositories are implemented under the edb360-master/repo subdirectory. Each has a readme file, which explains how to create the repository, consume it and drop it. The eAdam3 repository also includes instructions how to clone an external-table-based eAdam repository into a heap-table-based eDB360 repository.
Executing eDB360 on the eDB360 repository is faster than executing it on the eAdam3 repository, while avoiding new bug 25802477. This new Oracle database bug inflicts compressed external-tables like the ones used by the eAdam3 repository.
If you use eDB360 or eAdam3 repositories and have questions or concerns, do not hesitate to contact the author.
“ORA-00997: illegal use of LONG datatype” on a CTAS querying a view with a LONG column
Working on the new eDB360 repository I came across this “ORA-00997: illegal use of LONG datatype” while trying to CTAS on the following DBA views:
dba_constraints
dba_ind_partitions
dba_ind_subpartitions
dba_tab_cols
dba_tab_columns
dba_tab_partitions
dba_tab_subpartitions
dba_triggers
dba_views
All these views above include at least a LONG column, which raises the ORA-00997 while trying to do something like: CREATE TABLE edb360.dba#constraints AS SELECT * FROM dba_constraints.
I found several blogs explaining reason and some providing some hints, like using the TO_LOB function. Based on that I created a new stand-alone script that inputs 4 parameters and performs the CTAS I need. The 4 parameters are:
1: owner of source table/view
2: source table/view name
3: owner of target table
4: target table name
I am making this free script available for others to use at will.
-- How to solve ORA-00997: illegal use of LONG datatype while copying tables
-- paramaters
-- 1: owner of source table/view
-- 2: source table/view name
-- 3: owner of target table
-- 4: target table name
-- sample: @repo_edb360_create_one sys dba_constraints edb360 dba#constraints
DEF owner_source = '&1.';
DEF table_source = '&2.';
DEF owner_target = '&3.';
DEF table_target = '&4.';
DECLARE
l_list_ddl VARCHAR2(32767);
l_list_sel VARCHAR2(32767);
l_list_ins VARCHAR2(32767);
BEGIN
FOR i IN (SELECT column_name, data_type, data_length FROM dba_tab_columns WHERE owner = UPPER(TRIM('&&owner_source.')) and table_name = UPPER(TRIM('&&table_source.')) ORDER BY column_id)
LOOP
l_list_ddl := l_list_ddl||','||i.column_name||' '||REPLACE(i.data_type,'LONG','CLOB');
l_list_ins := l_list_ins||','||i.column_name;
IF i.data_type IN ('VARCHAR2', 'CHAR', 'RAW') THEN
l_list_ddl := l_list_ddl||'('||i.data_length||')';
END IF;
IF i.data_type = 'LONG' THEN
l_list_sel := l_list_sel||',TO_LOB('||i.column_name||')';
ELSE
l_list_sel := l_list_sel||','||i.column_name;
END IF;
END LOOP;
EXECUTE IMMEDIATE 'CREATE TABLE &&owner_target..&&table_target. ('||TRIM(',' FROM l_list_ddl)||') COMPRESS';
EXECUTE IMMEDIATE 'INSERT /*+ APPEND */ INTO &&owner_target..&&table_target. ('||TRIM(',' FROM l_list_ins)||') SELECT '||TRIM(',' FROM l_list_sel)||' FROM &&owner_source..&&table_source.';
EXECUTE IMMEDIATE 'COMMIT';
END;
/
eDB360 new features (March 2017)

As many of you know, eDB360 is a free tool that provides a 360-degree view of an Oracle database without any installation. A new version is available like once per month, but occasionally a large number of enhancements are implemented at once. This new release v1708 (March 25, 2017) includes several new features requested recently by some users of the tool, thus the need to blog about what is new:
- Reducing the scope of eDB360 is now possible without having to generate a custom configuration file. Prior to this version, if a user wanted to generate output for let’s say AWR reports only (section 7a), the tool needed a custom.sql file with line DEF edb360_sections = ‘7a’;. Then we would pass to edb360.sql as 2nd execution parameter the name of this custom configuration file (too cumbersome!). Starting on v1708, we can directly pass to edb360.sql the section that we desire (i.e. SQL> @edb360 T 7a). This 2nd parameter can either input the name of a custom configuration file (legacy functionality), but now it also accepts a column, a section, a list of columns or a list of sections; for example: 7a, 7, 7a-7b, 1-4 and 3 are all valid values.
- A couple of reports were added to section 3h: “SQL in logon storms” and “SQL executed row-by-row”. The former identifies those SQL statements that are seen frequently on very short-lived sessions (based on ASH), and the latter presents a list of SQL statements with large number of executions and small number of rows processed.
- eDB360 now extracts ASH from eAdam for top 16 SQL_ID (as per SQLd360 list) + top 12 SNAP_ID (as per AWR MAX from column 7a). What it means is that eDB360 includes now a tar file with raw ASH data for both: SQL statements of interest and for AWR periods of interest (both according to what eDB360 considers important). Using eAdam is easy, so when content of eDB360 does not include a very specific aggregation of ASH data that we need, or when we have to understand the sequence of some ASH samples for example, we can then restore this eAdam data on any Oracle database and data mine it.
- Some reports on section 2b show now totals at the bottom. That is to SUM some numeric values. Other reports may follow in future releases.
- RMAN section includes now a new report “Blocks with Corruption or Non-logged”.
- Added Load Profile (Per Sec, Per Txn and Count) as per DBA_HIST_SYSMETRIC_SUMMARY. This Load Profile resembles what we see on AWR at the top, but this is computed for the entire period of diagnostics (31 days by default). It shows max values, average, median and several percentiles. With this new report on section 1a, we can glance over it and discover in minutes some areas of further interest, for example: logons per second too high, just to mention one.
- There is a new section 4i with “Waits Count v.s. Average Latency for top 24 Wait Events”. With this set of 24 reports (one for each of the top wait events) we can observe if patterns on the number of counts relate to patterns on the latency for such wait event; for example we are able to see if an increase in the number of waits for db file sequential reads correlates to an increase of average latency for such wait event. We can also observe cases were latency for a wait event cannot be explained by load on current database, thus hinting an external influence.
- Fixed “ORA-01476: divisor is equal to zero” on planx at DBA_HIST_SQLSTAT.
- Added AWR DIFF reports for RAC and per instance. These are computed comparing MAX reports to MEDIAN reports, and they help to quickly identify large differences on load. These new AWR DIFF reports are regulated by configuration parameter edb360_conf_incl_addm_rpt (enabled by default). They exist on 11R2 and higher.
- Added the ASH Analytics Active report for 12c. This new ASH report is regulated by configuration parameter edb360_conf_incl_ash_analy_rpt (enabled by default). This applies to 12c and higher.
- The name of the database is now part of the main filename. Some users requested to include this database name as part of the main zip file since they are using eDB360 periodically on several databases. This new feature is regulated by configuration parameter edb360_conf_incl_dbname_file (disabled by default).
- At completion, main eDB360 zip file can now by automatically moved to a location other than the standard SQL*Plus working directory. All output files are still generated on the local SQL*Plus directory from where the script edb360.sql is executed (i.e. edb360-master directory), but at the completion of the execution the consolidated output zip file is now moved to a location specified by a new parameter. This new feature is regulated by configuration parameter edb360_move_directory (disabled by default).
- Added new report on “Database and Schema Triggers” under column 3h. This new report can be used to see potential LOGON or other global triggers. For triggers on specific tables, refer to SQLd360 which is automatically included on eDB360 for top SQL.
- All queries executed by eDB360 to generate its output were modified. New format is q'[query]’. Reason for this change is to improve readability of the code.
Always download and use the latest version of this tool. For questions or feedback email me. And I hope you get to enjoy eDB360 as much as I do!
eDB360 includes now an optional staging repository
eDB360 has always worked under the premise “no installation required”, and still is the case today – it is part of its fundamental essence: give me a 360-degree view of my Oracle database with no installation whatsoever. With that in mind, this free tool helps sites that have gone to the cloud, as well as those with “on-premises” databases; and in both cases not installing anything certainly expedites diagnostics collections. With eDB360, you simply connect to SQL*Plus with an account that can select from the catalog, execute then a set of scripts behind eDB360 and bingo!, you get to understand what is going on with your database just by navigating the html output. With such functionality, we can remotely diagnose a database, and even elaborate on the full health-check of it. After all, that is how we successfully use it every day!, saving us hundreds of hours of metadata gathering and cross-reference analysis.
Starting with release v1706, eDB360 also supports an optional staging repository of the 26 AWR views listed below. Why? the answer is simple: improved performance! This can be quite significant on large databases with hundreds of active sessions, with frequent snapshots, or with a long history on AWR. We have seen cases where years of data are “stuck” on AWR, specially in older releases of the database. Of course cleaning up the outdated AWR history (and corresponding statistics) is highly recommended, but in the meantime trying to execute edb360 on such databases may lead to long execution hours and frustration, taking sometimes days for what should take only a few hours.
- dba_hist_active_sess_history
- dba_hist_database_instance
- dba_hist_event_histogram
- dba_hist_ic_client_stats
- dba_hist_ic_device_stats
- dba_hist_interconnect_pings
- dba_hist_memory_resize_ops
- dba_hist_memory_target_advice
- dba_hist_osstat
- dba_hist_parameter
- dba_hist_pgastat
- dba_hist_resource_limit
- dba_hist_service_name
- dba_hist_sga
- dba_hist_sgastat
- dba_hist_sql_plan
- dba_hist_sqlstat
- dba_hist_sqltext
- dba_hist_sys_time_model
- dba_hist_sysmetric_history
- dba_hist_sysmetric_summary
- dba_hist_sysstat
- dba_hist_system_event
- dba_hist_tbspc_space_usage
- dba_hist_wr_control
- dba_hist_snapshot
Thus, if you are contemplating executing eDB360 on a large database, and provided pre-check script edb360-master/sql/awr_ash_pre_check.sql shows that eDB360 might take over 24 hours, then while you clean up your AWR repository you can use the eDB360 staging repository as a workaround to speedup eDB360 execution. The use of this optional staging repository is very simple, just look inside the edb360-master/repo directory for instructions. And as always, shoot me an email or comment here if there were any questions.
Smart Scans efficiency chart for Oracle Engineered Systems
If you manage an Oracle Engineered System you may wonder how well your Smart Scans are performing. Are you taking full advantage of Exadata Optimizations? If so, how do you measure them?
Uwe Hesse explains well some important statistics on Exadata. For some time now, eDB360 includes a report on Smart Scan efficiency, which is nothing but a Google Chart on top of relevant statistics.
Sample chart below is from a data warehouse DW application. It shows in blue that bytes eligible for offloading are around 95%, which denote a large amount of desired full scans. We see in red that between 80 and 95% of the expected I/O did not hit the network, i.e. it was saved (incorrectly referred as IO Saved since what is saved is the network traffic). And in yellow we see between 30 and 45% of the IO was entirely avoided due to Storage Indexes. So, with 80-95% of the expected data not going through the network and 30-45% of IO entirely eliminated, I could conclude that Exadata Optimizations are well applied on this DW.

If you have SQL*Plus access to an Engineered System, and want to produce a chart like this, simply download and execute free tool eDB360. This tool installs nothing on your database!
How to configure eDB360?
eDB360 has two execution parameters. The first one specifies if the database is licensed to use the Tuning or Diagnostics packs (or none). The second parameter is optional, and if entered it specifies the name of a custom configuration file that allows to change the behavior of eDB360. With this optional configuration file you can make changes such as: reduce the scope of the output to maybe a single column, a section, or even a range of sections. You can also change the time window from the default (last 31 days) to a larger window (if your AWR retention period allows) or smaller window. You can also specify a particular range of dates, or include additional report formats such as text, csv or xml.
If you are an experienced user of eDB360, you may want then to familiarize yourself with the configuration file sql/edb360_00_config.sql (listed below) and the sample custom configuration file provided (sql/custom_config_01.sql). Then you may want to assembly your own configuration file as a subset of the DEF values from sql/edb360_00_config.sql, and provide the name of your custom configuration script as the second execution parameter for eDB360. Your configuration file should reside under edb360-master/sql and the filename is case sensitive.
-- edb360 configuration file. for those cases where you must change edb360 functionality /*************************** ok to modify (if really needed) ****************************/ -- section to report. null means all (default) -- report column, or section, or range of columns or range of sections i.e. 3, 3-4, 3a, 3a-4c, 3-4c, 3c-4 DEF edb360_sections = ''; -- edb360 trace DEF sql_trace_level = '1'; -- history days (default 31) DEF edb360_conf_days = '31'; -- range of dates below superceed history days when values are other than YYYY-MM-DD DEF edb360_conf_date_from = 'YYYY-MM-DD'; DEF edb360_conf_date_to = 'YYYY-MM-DD'; -- working hours are defined between these two HH24MM values (i.e. 7:30AM and 7:30PM) DEF edb360_conf_work_time_from = '0730'; DEF edb360_conf_work_time_to = '1930'; -- working days are defined between 1 (Sunday) and 7 (Saturday) (default Mon-Fri) DEF edb360_conf_work_day_from = '2'; DEF edb360_conf_work_day_to = '6'; -- maximum time in hours to allow edb360 to execute (default 24 hrs) DEF edb360_conf_max_hours = '24'; -- include GV$ACTIVE_SESSION_HISTORY (default N) DEF edb360_conf_incl_ash_mem = 'N'; -- include GV$SQL_MONITOR (default N) DEF edb360_conf_incl_sql_mon = 'N'; -- include GV$SYSSTAT (default Y) DEF edb360_conf_incl_stat_mem = 'Y'; -- include GV$PX and GV$PQ (default Y) DEF edb360_conf_incl_px_mem = 'Y'; -- include DBA_SEGMENTS on queries with no filter on segment_name (default Y) -- note: some releases of Oracle produce suboptimal plans when no segment_name is passed DEF edb360_conf_incl_segments = 'Y'; -- include DBMS_METADATA calls (default Y) -- note: some releases of Oracle take very long to generate metadata DEF edb360_conf_incl_metadata = 'Y'; /**************************** not recommended to modify *********************************/ -- excluding report types reduce usability while providing marginal performance gain DEF edb360_conf_incl_html = 'Y'; DEF edb360_conf_incl_xml = 'N'; DEF edb360_conf_incl_text = 'N'; DEF edb360_conf_incl_csv = 'N'; DEF edb360_conf_incl_line = 'Y'; DEF edb360_conf_incl_pie = 'Y'; -- excluding awr reports substantially reduces usability with minimal performance gain DEF edb360_conf_incl_awr_rpt = 'Y'; DEF edb360_conf_incl_addm_rpt = 'Y'; DEF edb360_conf_incl_ash_rpt = 'Y'; DEF edb360_conf_incl_tkprof = 'Y'; -- top sql to execute further diagnostics (range 0-128) DEF edb360_conf_top_sql = '48'; DEF edb360_conf_top_cur = '4'; DEF edb360_conf_top_sig = '4'; DEF edb360_conf_planx_top = '48'; DEF edb360_conf_sqlmon_top = '0'; DEF edb360_conf_sqlash_top = '0'; DEF edb360_conf_sqlhc_top = '0'; DEF edb360_conf_sqld360_top = '16'; DEF edb360_conf_sqld360_top_tc = '0'; /************************************ modifications *************************************/ -- If you need to modify any parameter create a new custom configuration file with a -- subset of the DEF above, and place on same edb360-master/sql directory; then when -- you execute edb360.sql, pass on second parameter the name of your configuration file
edb360 taking a long time
In most cases edb360 takes less than 1hr to execute. But I often hear of cases where it takes a lot longer than that. In a corner case it was taking several days and it had to be killed.
So the question is WHY edb360 takes that long?
Well, edb360 executes thousands of SQL statements sequentially (intentionally). Many of these queries read data from AWR and in particular from ASH. So, lets say your ASH historical table has 2B rows, and on top of that you have not gathered statistics on AWR tables in years, thus CBO under-estimates cardinality and tends to use index access and nested loops. In such extreme cases you may end up with suboptimal execution plans that expect to return a few rows, but actually read a couple of billion rows using index access operations and nested loops. A query like this may take hours to complete!
As of version v1515, edb360 has a shortcut algorithm that ends an execution after 8 hours. So you may get an incomplete output, but it ends normally and the partial output can actually be used. This is not a solution but a workaround for those long executions.
How to troubleshoot edb360 taking long?
Steps:
1. Review files 00002_edb360_dbname_log.txt, 00003_edb360_dbname_log2.txt, 00004_edb360_dbname_log3.txt and 00005_edb360_dbname_tkprof_sort.txt. First log shows the state of the statistics for AWR Tables. If stats are old then gather them fresh with script edb360/sql/gather_stats_wr_sys.sql
2. If number of rows on WRH$_ACTIVE_SESSION_HISTORY as per 00002_edb360_dbname_log.txt is several millions, then you may not be purging data periodically. There are some known bugs and some blog posts on this regard. Review MOS 387914.1 and proceed accordingly. Execute query below to validate ASH age:
SELECT TRUNC(sample_time, 'MM'), COUNT(*) FROM dba_hist_active_sess_history GROUP BY TRUNC(sample_time, 'MM') ORDER BY TRUNC(sample_time, 'MM') /
3. If edb360 version (first line on its readme) is older than 1 month, download and use latest version: https://github.com/carlos-sierra/edb360/archive/master.zip (link is also provided on the right-hand side of this blog under downloads).
4. Consider suppressing text and or csv reports. Each for an estimated gain of about 20%. Keep in mind that when suppressing reports, you start loosing some functionality. To suppress lets say text and csv reports, place the following two commands at the end of script edb360/sql/edb360_00_config.sql
DEF edb360_conf_incl_text = ‘N’;
DEF edb360_conf_incl_csv = ‘N’;
5. If after going through steps 1-4 above, edb360 still takes longer than a few hours, feel free to email author carlos.sierra.usa@gmail.com and provide 4 files from step 1.
What is new on edb360 v1510?
Every release of edb360 includes some “new goodies”. Latest version v1510 reduces the number of execution parameters from 2 to just 1. It also incorporates a new configuration file which is mostly static, but it can be user-modified for special cases. And new sections below are all now part of edb360. Enjoy!


Discovering if a System level Parameter has changed its value (and when it happened)
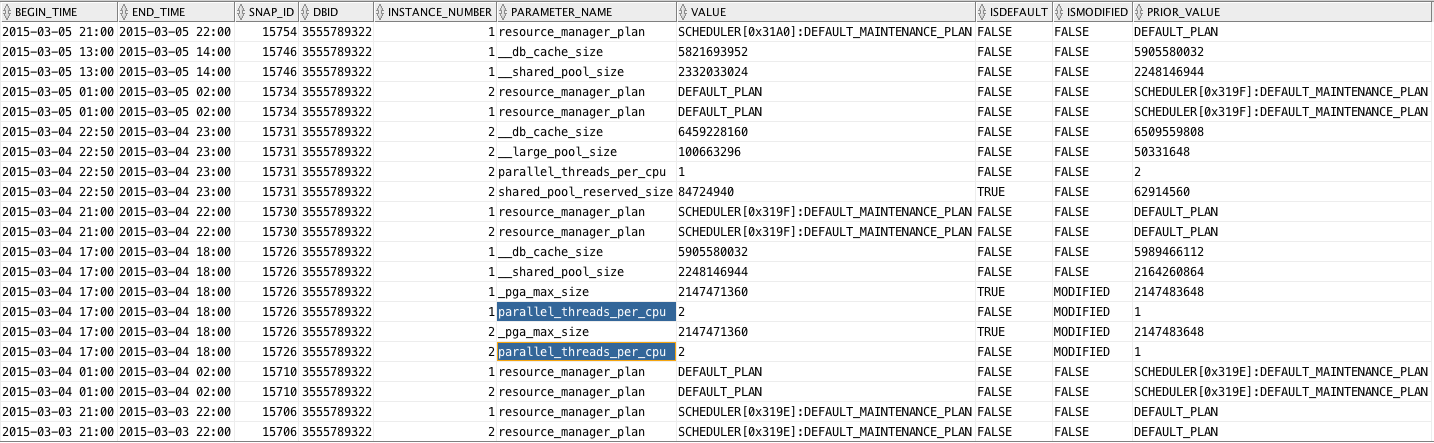
Quite often I learn of a system where “nobody changed anything” and suddenly the system is experiencing some strange behavior. Then after diligent investigation it turns out someone changed a little parameter at the System level, but somehow disregarded mentioning it since he/she thought it had no connection to the unexpected behavior. As we all know, System parameters are big knobs that we don’t change lightly, still we often see “unknown” changes like the one described.
Script below produces a list of changes to System parameter values, indicating when a parameter was changed and from which value into which value. It does not filter out cache re-sizing operations, or resource manager plan changes. Both would be easy to exclude, but I’d rather see those global changes listed as well.
Note: This script below should only be executed if your site has a license for the Oracle Diagnostics pack (or Tuning pack), since it reads from AWR.
WITH
all_parameters AS (
SELECT snap_id,
dbid,
instance_number,
parameter_name,
value,
isdefault,
ismodified,
lag(value) OVER (PARTITION BY dbid, instance_number, parameter_hash ORDER BY snap_id) prior_value
FROM dba_hist_parameter
)
SELECT TO_CHAR(s.begin_interval_time, 'YYYY-MM-DD HH24:MI') begin_time,
TO_CHAR(s.end_interval_time, 'YYYY-MM-DD HH24:MI') end_time,
p.snap_id,
p.dbid,
p.instance_number,
p.parameter_name,
p.value,
p.isdefault,
p.ismodified,
p.prior_value
FROM all_parameters p,
dba_hist_snapshot s
WHERE p.value != p.prior_value
AND s.snap_id = p.snap_id
AND s.dbid = p.dbid
AND s.instance_number = p.instance_number
ORDER BY
s.begin_interval_time DESC,
p.dbid,
p.instance_number,
p.parameter_name
/
Sample output follows, where we can see a parameter affecting Degree of Parallelism was changed. This is just to illustrate its use. Enjoy this new free script! It is now part of edb360.