Archive for the ‘SQL Plan Management’ Category
Query to get SQL_ID from DBA_SQL_PLAN_BASELINES
Doing a SQL Plan Baseline fleet cleanup, I wanted to get the SQL_ID give a SQL Plan Baseline. Long ago I wrote a PL/SQL function that inputs some SQL Text and outputs its SQL_ID . Then, I could use such function, passing the SQL Text from the SQL Plan Baseline (this is on 12c), and getting back the SQL_ID I need!
I tested this query below on 12.1.0.2, and it gives me exactly what I wanted: Input a SQL Plan Baseline, and output its SQL_ID. And all from a simple SQL query. Enjoy it! 🙂
/* from https://carlos-sierra.net/2013/09/12/function-to-compute-sql_id-out-of-sql_text/ */ /* based on http://www.slaviks-blog.com/2010/03/30/oracle-sql_id-and-hash-value/ */ WITH FUNCTION compute_sql_id (sql_text IN CLOB) RETURN VARCHAR2 IS BASE_32 CONSTANT VARCHAR2(32) := '0123456789abcdfghjkmnpqrstuvwxyz'; l_raw_128 RAW(128); l_hex_32 VARCHAR2(32); l_low_16 VARCHAR(16); l_q3 VARCHAR2(8); l_q4 VARCHAR2(8); l_low_16_m VARCHAR(16); l_number NUMBER; l_idx INTEGER; l_sql_id VARCHAR2(13); BEGIN l_raw_128 := /* use md5 algorithm on sql_text and produce 128 bit hash */ SYS.DBMS_CRYPTO.hash(TRIM(CHR(0) FROM sql_text)||CHR(0), SYS.DBMS_CRYPTO.hash_md5); l_hex_32 := RAWTOHEX(l_raw_128); /* 32 hex characters */ l_low_16 := SUBSTR(l_hex_32, 17, 16); /* we only need lower 16 */ l_q3 := SUBSTR(l_low_16, 1, 8); /* 3rd quarter (8 hex characters) */ l_q4 := SUBSTR(l_low_16, 9, 8); /* 4th quarter (8 hex characters) */ /* need to reverse order of each of the 4 pairs of hex characters */ l_q3 := SUBSTR(l_q3, 7, 2)||SUBSTR(l_q3, 5, 2)||SUBSTR(l_q3, 3, 2)||SUBSTR(l_q3, 1, 2); l_q4 := SUBSTR(l_q4, 7, 2)||SUBSTR(l_q4, 5, 2)||SUBSTR(l_q4, 3, 2)||SUBSTR(l_q4, 1, 2); /* assembly back lower 16 after reversing order on each quarter */ l_low_16_m := l_q3||l_q4; /* convert to number */ SELECT TO_NUMBER(l_low_16_m, 'xxxxxxxxxxxxxxxx') INTO l_number FROM DUAL; /* 13 pieces base-32 (5 bits each) make 65 bits. we do have 64 bits */ FOR i IN 1 .. 13 LOOP l_idx := TRUNC(l_number / POWER(32, (13 - i))); /* index on BASE_32 */ l_sql_id := l_sql_id||SUBSTR(BASE_32, (l_idx + 1), 1); /* stitch 13 characters */ l_number := l_number - (l_idx * POWER(32, (13 - i))); /* for next piece */ END LOOP; RETURN l_sql_id; END compute_sql_id; SELECT compute_sql_id(sql_text) sql_id, signature FROM dba_sql_plan_baselines /
Scripts to deal with SQL Plan Baselines, SQL Profiles and SQL Patches
To mitigate SQL performance issues, I do make use of SQL Plan Baselines, SQL Profiles and SQL Patches, on a daily basis. Our environments are single-instance 12.1.0.2 CDBs, with over 2,000 PDBs. Our goal is Execution Plan Stability and consistent performance, over CBO plan flexibility. The CBO does a good job, considering the complexity imposed by current applications design. Nevertheless, some SQL require some help in order to enhance their plan stability.
I have written and shared a set of scripts that simply make the use of a bunch of APIs a lot easier, with better documented actions, and fully consistent within the organization. I have shared with the community these scripts in the past, and I keep them updated as per needs change. All these “CS” scripts are available under the download section on the right column.
Current version of the CS scripts is more like a toolset. You treat them as a whole. All of them call some other script that exists within the cs_internal subdirectory, then I usually navigate to the parent sql directory, and connect into SQL*Plus from there. All these scripts can be easily cloned and/or customized to your specific needs. They are available as “free to use” and “as is”. There is no requirement to keep their heading intact, so you can reverse-engineer them and make them your own if you want. Just keep in mind that I maintain, enhance, and extend this CS toolset every single day; so what you get today is a subset of what you will get tomorrow. If you think an enhancement you need (or a fix) is beneficial to the larger community (and to you), please let me know.
SQL Plan Baselines scripts

With the set of SQL Plan Baselines scripts, you can: 1) create a baseline based on a cursor or a plan stored into AWR; 2) enable and disable baselines; 3) drop baselines; 4) store them into a local staging table; 5) restore them from their local staging table; 6) promote as “fixed” or demote from “fixed”; 7) “zap” them if you have installed “El Zapper” (iod_spm).
Note: “El Zapper” is a PL/SQL package that extends the functionality of SQL Plan Management by automagically creating SQL Plan Baselines based on proven performance of a SQL statement over time, while considering a large number of executions, and a variety of historical plans. Please do not confuse “El Zapper” with auto-evolve of SPM. They are based on two very distinct premises. “El Zapper” also monitors the performance of active SQL Plan Baselines, and during an observation window it may disable a SQL Plan Baseline, if such plan no longer performs as “promised” (according to some thresholds). Most applications do not need “El Zapper”, since the use of SQL Plan Management should be more of an exception than a rule.
SQL Profiles scripts

With the set of SQL Profiles scripts, you can: 1) create a profile based on the outline of a cursor, or from a plan stored into AWR; 2) enable and disable profiles; 3) drop profiles; 4) store them into a local staging table; 5) restore them from their local staging table; 6) transfer them from one location to another (very similar to coe_xfr_sql_profile.sql, but on a more modular way).
Note: Regarding the transfer of a SQL Profile, the concept is simple: 1) on source location generate two plain text scripts, one that contains the SQL text, and a second that includes the Execution Plan (outline); 2) execute these two scripts on a target location, in order to create a SQL Profile there. The beauty of this method is not only that you can easily move Execution Plans between locations, but that you can actually create a SQL Profile getting the SQL Text from SQL_ID “A”, and the Execution Plan from SQL_ID “B”, allowing you to do things like: removing CBO Hints, or using a plan from a similar SQL but not quite the same (e.g. I can tweak a stand-alone cloned version of a SQL statement, and once I get the plan that I need, I associate the SQL Text from the original SQL, with the desired Execution Plan out of the stand-alone customized version of the SQL, after that I create a SQL Plan Baseline and drop the staging SQL Profile).
SQL Patches scripts

With the set of SQL Patches scripts, you can: 1) create a SQL patch based on one or more CBO Hints you provide (e.g.: GATHER_PLAN_STATISTICS MONITOR FIRST_ROWS(1) OPT_PARAM(‘_fix_control’ ‘5922070:OFF’) NO_BIND_AWARE); 2) enable and disable SQL patches; 3) drop SQL patches; 4) store them into a local staging table; 5) restore them from their local staging table.
Note: I use SQL Patches a lot, specially to embed CBO Hints that generate some desirable diagnostics details (and not so much to change plans), such as the ones provided by GATHER_PLAN_STATISTICS and MONITOR. In some cases, after I use the pathfinder tool written by Mauro Pagano, I have to disable a CBO patch (funny thing: I use a SQL Patch to disable a CBO Patch!). I also use a SQL Patch if I need to enable Adaptive Cursor Sharing (ACS) for one SQL (we disabled ACS for one major application). Bear in mind that SQL Plan Baselines, SQL Profiles and SQL Patches happily co-exist, so you can use them together, but I do prefer to use SQL Plan Baselines alone, whenever possible.
Adapting and adopting SQL Plan Management (SPM)
Introduction
This post is about: “Adapting and adopting SQL Plan Management (SPM) to achieve execution plan stability for sub-second queries on a high-rate OLTP mission-critical application”. In our case, such an application is implemented on top of several Oracle 12c multi tenant databases, where a consistent average execution time is more valuable than flexible execution plans. We successfully achieved plan stability implementing a simple algorithm using PL/SQL calling DBMS_SPM public APIs.
Chart below depicts a typical case where the average performance of a large set of business-critical SQL statements suddenly degraded from sub-millisecond to 15 or 20ms, then beccome more stable around 3ms. Wide spikes are a typical trademark of an Execution Plan for one or more SQL statements flipping for some time. In order to produce a more consistent latency we needed to improve plan stability, and of course the preferred tool to achieve that on an Oracle database is SQL Plan Management.

Algorithm
We tested and ruled out adaptive SQL Plan Management, which is an excellent 12c new feature. But, due to the dynamics of this application, where transactional data shifts so fast, allowing this “adaptive SPM” feature to evaluate auto-captured plans using bind variable values captured a few hours earlier, rendered unfortunately false positives. These false positives “evolved” as execution plans that were numerically optimal for values captured (at the time the candidate plan was captured), but performed poorly when executed on “current” values a few hours later. Nevertheless, this 12c “adaptive SPM” new feature is worth exploring for other applications.
 We adapted SPM so it would only generate SQL Plan Baselines on SQL that executes often, and that is critical for the business. The algorithm has some complexity such as candidate evaluation and SQL categorization; and besides SPB creation it also includes plan demotion and plan promotion. We have successfully implemented it in some PDBs and we are currently doing a rollout to entire CDBs. The algorithm is depicted on diagram on the left, and more details are included in corresponding presentation slides listed on the right-hand bar. I plan to talk about this topic on an international Oracle Users Group in 2018.
We adapted SPM so it would only generate SQL Plan Baselines on SQL that executes often, and that is critical for the business. The algorithm has some complexity such as candidate evaluation and SQL categorization; and besides SPB creation it also includes plan demotion and plan promotion. We have successfully implemented it in some PDBs and we are currently doing a rollout to entire CDBs. The algorithm is depicted on diagram on the left, and more details are included in corresponding presentation slides listed on the right-hand bar. I plan to talk about this topic on an international Oracle Users Group in 2018.
This algorithm is scripted into a sample PL/SQL package, which you can find on a subdirectory on my shared scripts. If you consider using this sample script for an application of your own, be sure you make it yours before attempting to use it. In other words: fully understand it first, then proceed to customize it accordingly and test it thoroughly.
Results
Chart below shows how average performance of business-critical SQL became more stable after implementing algorithm to adapt and adopt SPM on a pilot PDB. Not all went fine although: we had some outliers that required some tuning to the algorithm. Among challenges we faced: volatile data (creating a SPB when table was almost empty, then using it when table was larger); skewed values (create a SPB for non-popular value, then using it on a popular value); proper use of multiple optimal plans due to Adaptive Cursor Sharing (ACS); rejected candidates due to conservative initial restrictions on algorithm (performance per execution, number of executions, age of cursor, etc.)

Conclusion
If your OLTP application contains business critical SQL that executes at a high-rate, and where a spike on latency risks affecting SLAs, you may want to consider implementing SQL Plan Management. Consider then both: “adaptive SPM” if it satisfies your requirements, else build a PL/SQL library that can implement more complex logic for candidates evaluation and for SPBs maintenance. I do believe SPM works great, specially when you enhance its out-of-the-box functionality to satisfy your specific needs.
Creating a SQL Plan Baseline from Cursor Cache or AWR
A DBA deals with performance issues often, and having a SQL suddenly performing poorly is common. What do we do? We proceed to “pin” an execution plan, then investigate root cause (the latter is true if time to next fire permits).
DBMS_SPM provides some APIs to create a SQL Plan Baseline (SPB) from the Cursor Cache, or from a SQL Tuning Set (STS), but not from the Automatic Workload Repository (AWR). For the latter, you need a two-steps approach: create a STS from AWR, then load a SPB from the STS. Fine, except when your next fire is waiting for you, or when deciding which is the “best” plan is not trivial.
Take for example chart below, which depicts multiple execution plans with different performance for one SQL statement. The SQL statement is actually quite simple, and data is not significantly skewed. On this particular application, usually one-size-fits-all (meaning one-and-only-one plan) works well for most values passed on variable place holders. Then, which plan would you choose?
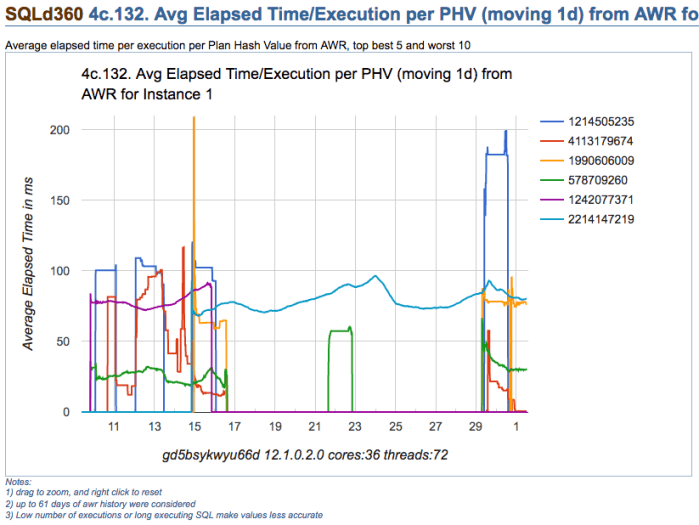
Note: please get all scripts using the download column on the right
Looking at summary of known Execution Plans’ performance below (as reported by planx.sql), we can see the same 6 Execution Plans.
1st Plan on list shows an average execution time of 2.897ms according to AWR, and 0.896ms according to Cursor Cache; and number of recorded executions for this Plan are 2,502 and 2,178 respectively. We see this Plan contains one Nested Loop, and if we look at historical performance we notice this Plan takes less than 109ms 95% of the time, less than 115ms 97% of the time, and less then 134ms 99% of the time. We also see that worst recorded AWR period, had this SQL performing in under 150ms (on average for that one period).
We also notice that last plan on list performs one execution in 120.847ms on average (as per AWR) and 181.113ms according to Cursor Cache (on average as well). Then, “pinning” 1st plan on list seems like a good choice, but not too different than all but last plan, specially when we consider both: average performance and historical performance according to percentiles reported.
PLANS PERFORMANCE
~~~~~~~~~~~~~~~~~
Plan ET Avg ET Avg CPU Avg CPU Avg BG Avg BG Avg Executions Executions ET 100th ET 99th ET 97th ET 95th CPU 100th CPU 99th CPU 97th CPU 95th
Hash Value AWR (ms) MEM (ms) AWR (ms) MEM (ms) AWR MEM AWR MEM MIN Cost MAX Cost NL HJ MJ Pctl (ms) Pctl (ms) Pctl (ms) Pctl (ms) Pctl (ms) Pctl (ms) Pctl (ms) Pctl (ms)
----------- ----------- ----------- ----------- ----------- ------------ ------------ ------------ ------------ ---------- ---------- --- --- --- ----------- ----------- ----------- ----------- ----------- ----------- ----------- -----------
4113179674 2.897 0.896 2.715 0.714 96 5 2,502 2,178 8 738 1 0 0 149.841 133.135 114.305 108.411 147.809 133.007 113.042 107.390
578709260 29.576 32.704 28.865 31.685 1,583 1,436 6,150 1,843 67 875 1 0 0 154.560 84.264 65.409 57.311 148.648 75.209 62.957 56.305
1990606009 74.399 79.054 73.163 77.186 1,117 1,192 172 214 905 1,108 0 1 0 208.648 208.648 95.877 95.351 205.768 205.768 94.117 93.814
1242077371 77.961 77.182 1,772 8,780 949 1,040 0 1 0 102.966 98.206 91.163 89.272 100.147 97.239 90.165 88.412
2214147219 79.650 82.413 78.242 80.817 1,999 2,143 42,360 24,862 906 1,242 0 1 0 122.535 101.293 98.442 95.737 119.240 99.118 95.266 93.156
1214505235 120.847 181.113 105.485 162.783 506 1,355 48 12 114 718 1 0 0 285.950 285.950 285.950 285.950 193.954 193.954 193.954 193.954
Plans performance summary above is displayed in a matter of seconds by planx.sql, sqlperf.sql and by a new script spb_create.sql. This output helps make a quick decision about which Execution Plan is better for “pinning”, meaning: to create a SPB on it.
Sometimes such decision is not that trivial, as we can see on sample below. Which plan is better? I would go with 2nd on list. Why? performance-wise this plan is more stable. It does a Hash Join, so I am expecting to see a Plan with full scans, but if I can get consistent executions under 0.4s (according to percentiles), I would be tempted to “pin” this 2nd Plan instead of 1st one. And I would stay away from 3rd and 5th. So maybe I would create a SPB with 3 plans instead of just one, and include on this SPB 1st, 2nd and 4th on the list.
PLANS PERFORMANCE
~~~~~~~~~~~~~~~~~
Plan ET Avg ET Avg CPU Avg CPU Avg BG Avg BG Avg Executions Executions ET 100th ET 99th ET 97th ET 95th CPU 100th CPU 99th CPU 97th CPU 95th
Hash Value AWR (ms) MEM (ms) AWR (ms) MEM (ms) AWR MEM AWR MEM MIN Cost MAX Cost NL HJ MJ Pctl (ms) Pctl (ms) Pctl (ms) Pctl (ms) Pctl (ms) Pctl (ms) Pctl (ms) Pctl (ms)
----------- ----------- ----------- ----------- ----------- ------------ ------------ ------------ ------------ ---------- ---------- --- --- --- ----------- ----------- ----------- ----------- ----------- ----------- ----------- -----------
1917891576 0.467 0.334 0.330 0.172 119 33 554,914,504 57,748,249 6 1,188 2 0 0 6,732.017 10.592 1.628 1.572 1,420.864 1.557 1.482 1.261
99953997 1.162 2.427 0.655 0.492 83 55 58,890,160 2,225,247 12 2,311 0 1 0 395.819 235.474 108.142 34.909 56.008 22.329 12.926 3.069
3559532534 1.175 1,741.041 0.858 91.486 359 46 21,739,877 392 4 20 1 0 0 89,523.768 4,014.301 554.740 298.545 21,635.611 216.456 54.050 30.130
3650324870 2.028 20.788 1.409 2.257 251 199 24,038,404 143,819 11 5,417 0 1 0 726.964 254.245 75.322 20.817 113.259 21.211 13.591 8.486
3019880278 43.465 43.029 20,217 13,349 5,693 5,693 0 1 0 43.465 43.465 43.465 43.465 43.029 43.029 43.029 43.029
About new script spb_create.sql
Update: Scripts to deal with SQL Plan Baselines, SQL Profiles and SQL Patches
This new script is a life-saver for us, since our response time for an alert is usually measured in minutes, with a resolution (and sometimes a root cause analysis) expected in less than one hour from the time the incident is raised.
This script is quite simple:
- it provides a list of known Execution Plans including current (Cursor Cache) and historical (AWR) performance as displayed in two samples above, then
- asks on which Plan Hash Values (PHVs) you want to create a SPB on. It allows you to enter up to 3 PHVs; last
- asks if you want these plans to be set as FIXED
After you respond to ACCEPT parameters, then a SPB for your SQL is created and displayed. It does not matter if the Plan exists on Cursor Cache and/or on AWR, it finds the Plan and creates the SPB for you. Then: finding known Execution Plans, deciding which one is a better choice (or maybe more than one), and creating a SPB, all can be done very rapidly.
If you still prefer to use SQL Profiles and not SPBs for whatever reason, script coe_xfr_sql_profile.sql is still around and updated. On these 12c days, and soon 18c and beyond, I’d much rather use SQL Plan Management and create SPBs although!
Anyways, enjoy these free scripts and become a faster hero “pinning” good plans. Then don’t forget to do diligent root cause analysis afterwards. I use SQLd360 by Mauro Pagano for deep understanding of what is going on with my SQL statements.
Soon, I will post about a cool free tool that automates the implementation of SQL Plan Management on a high-rate OLTP where stability is more important than flexibility (frequently changing Execution Plans). Stay tuned!
Note: please get all scripts using the download column on the right
SQL Monitoring without MONITOR Hint
I recently got this question:
<<<Is there a way that I can generate SQL MONITORING report for a particular SQL_ID ( This SQL is generated from application code so I can’t add “MONITOR” hint) from command prompt ? If yes can you please help me through this ?>>>
Since this question is of general interest, I’d rather respond here:
As you know, SQL Monitoring starts automatically on a SQL that executes a PX plan, or when its Serial execution has consumed over 5 seconds on CPU or I/O.
If you want to force SQL Monitoring on a SQL statement, without modifying the SQL text itself, I suggest you create a SQL Patch for it. But before you do, please be aware that SQL Monitoring requires the Oracle Tuning Pack.
How to turn on SQL Monitoring for a SQL that executes Serial, takes less than 5 seconds, and without modifying the application that issues such SQL
Use SQL Patch with the MONITOR Hint. An easy way to do that is by using the free sqlpch.sql script provided as part of the cscripts (see right-hand side of this blog under Downloads).
To use sqlpch.sql script, pass as parameter #1 your SQL_ID and for parameter #2 pass “GATHER_PLAN_STATISTICS MONITOR” (without the double quotes).
This sqlpch.sql script will create a SQL Patch for your SQL, which will produce SQL Monitoring (and the collection of A-Rows) for every execution of your SQL.
Be aware there is some overhead involved, so after you are done with your analysis drop the SQL Patch.
Script sqlpch.sql shows the name of the SQL Patch it creates (look at its spool file), and it gives you the command to drop such SQL Patch.
For the actual analysis and diagnostics of your SQL (after you have executed it with SQL Patch in place) use free tool SQLd360.
And for more details about sqlpch.sql and other uses of this script please refer to this entry on my blog.
Skipping ACS ramp-up using a SQL Patch
As I prepare for one of my sessions at ODTUG Kscope14 I came across the typical situation of having a SQL for which I wanted to produce multiple optimal execution Plans on an 11g environment. As you may know, with Adaptive Cursor Sharing (ACS) this is possible and automatic, but the problem is that sometimes the ACS ramp-up process causes some suboptimal Execution Plans. If you want to skip this ACS ramp-up process, lets say for a SQL that is part of a business-critical transaction and which is known to have unstable Plans, then you may want to create a SQL Patch with the BIND_AWARE Hint. Maria Colgan explained this method on this blog post. What I present here is a script I use, so I can easily implement SQL Patches for some SQL where I just need to inject one or two CBO Hints, like this BIND_AWARE. I use SQL Profiles or SQL Plan Management when I need to provide CBO Hints that affect access paths or join order, but if I just need something like skipping ACS ramp-up or a Hint to produce a SQL Monitor report, then I’d rather use SQL Patch.
Script below asks for SQL_ID and for a short list of CBO Hints to include. By default it includes these 3: “GATHER_PLAN_STATISTICS MONITOR BIND_AWARE”. Execute this script connecting as SYS.
----------------------------------------------------------------------------------------
--
-- File name: sqlpch.sql
--
-- Purpose: Create Diagnostics SQL Patch for one SQL_ID
--
-- Author: Carlos Sierra
--
-- Version: 2013/12/28
--
-- Usage: This script inputs two parameters. Parameter 1 the SQL_ID and Parameter 2
-- the set of Hints for the SQL Patch (default to GATHER_PLAN_STATISTICS
-- MONITOR BIND_AWARE).
--
-- Example: @sqlpch.sql f995z9antmhxn BIND_AWARE
--
-- Notes: Developed and tested on 11.2.0.3 and 12.0.1.0
--
---------------------------------------------------------------------------------------
SPO sqlpch.txt;
DEF def_hint_text = 'GATHER_PLAN_STATISTICS MONITOR BIND_AWARE';
SET DEF ON TERM OFF ECHO ON FEED OFF VER OFF HEA ON LIN 2000 PAGES 100 LONG 8000000 LONGC 800000 TRIMS ON TI OFF TIMI OFF SERVEROUT ON SIZE 1000000 NUMF "" SQLP SQL>;
SET SERVEROUT ON SIZE UNL;
COL hint_text NEW_V hint_text FOR A300;
SET TERM ON ECHO OFF;
PRO
PRO Parameter 1:
PRO SQL_ID (required)
PRO
DEF sql_id_1 = '&1';
PRO
PRO Parameter 2:
PRO HINT_TEXT (default: &&def_hint_text.)
PRO
DEF hint_text_2 = '&2';
PRO
PRO Values passed:
PRO ~~~~~~~~~~~~~
PRO SQL_ID : "&&sql_id_1."
PRO HINT_TEXT: "&&hint_text_2." (default: "&&def_hint_text.")
PRO
SET TERM OFF ECHO ON;
SELECT TRIM(NVL(REPLACE('&&hint_text_2.', '"', ''''''), '&&def_hint_text.')) hint_text FROM dual;
WHENEVER SQLERROR EXIT SQL.SQLCODE;
-- trim sql_id parameter
COL sql_id NEW_V sql_id FOR A30;
SELECT TRIM('&&sql_id_1.') sql_id FROM DUAL;
VAR sql_text CLOB;
VAR sql_text2 CLOB;
EXEC :sql_text := NULL;
EXEC :sql_text2 := NULL;
-- get sql_text from memory
DECLARE
l_sql_text VARCHAR2(32767);
BEGIN -- 10g see bug 5017909
FOR i IN (SELECT DISTINCT piece, sql_text
FROM gv$sqltext_with_newlines
WHERE sql_id = TRIM('&&sql_id.')
ORDER BY 1, 2)
LOOP
IF :sql_text IS NULL THEN
DBMS_LOB.CREATETEMPORARY(:sql_text, TRUE);
DBMS_LOB.OPEN(:sql_text, DBMS_LOB.LOB_READWRITE);
END IF;
l_sql_text := REPLACE(i.sql_text, CHR(00), ' '); -- removes NUL characters
DBMS_LOB.WRITEAPPEND(:sql_text, LENGTH(l_sql_text), l_sql_text);
END LOOP;
-- if found in memory then sql_text is not null
IF :sql_text IS NOT NULL THEN
DBMS_LOB.CLOSE(:sql_text);
END IF;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('getting sql_text from memory: '||SQLERRM);
:sql_text := NULL;
END;
/
SELECT :sql_text FROM DUAL;
-- get sql_text from awr
DECLARE
l_sql_text VARCHAR2(32767);
l_clob_size NUMBER;
l_offset NUMBER;
BEGIN
IF :sql_text IS NULL OR NVL(DBMS_LOB.GETLENGTH(:sql_text), 0) = 0 THEN
SELECT sql_text
INTO :sql_text2
FROM dba_hist_sqltext
WHERE sql_id = TRIM('&&sql_id.')
AND sql_text IS NOT NULL
AND ROWNUM = 1;
END IF;
-- if found in awr then sql_text2 is not null
IF :sql_text2 IS NOT NULL THEN
l_clob_size := NVL(DBMS_LOB.GETLENGTH(:sql_text2), 0);
l_offset := 1;
DBMS_LOB.CREATETEMPORARY(:sql_text, TRUE);
DBMS_LOB.OPEN(:sql_text, DBMS_LOB.LOB_READWRITE);
-- store in clob as 64 character pieces
WHILE l_offset < l_clob_size
LOOP
IF l_clob_size - l_offset > 64 THEN
l_sql_text := REPLACE(DBMS_LOB.SUBSTR(:sql_text2, 64, l_offset), CHR(00), ' ');
ELSE -- last piece
l_sql_text := REPLACE(DBMS_LOB.SUBSTR(:sql_text2, l_clob_size - l_offset + 1, l_offset), CHR(00), ' ');
END IF;
DBMS_LOB.WRITEAPPEND(:sql_text, LENGTH(l_sql_text), l_sql_text);
l_offset := l_offset + 64;
END LOOP;
DBMS_LOB.CLOSE(:sql_text);
END IF;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('getting sql_text from awr: '||SQLERRM);
:sql_text := NULL;
END;
/
SELECT :sql_text2 FROM DUAL;
SELECT :sql_text FROM DUAL;
-- validate sql_text
BEGIN
IF :sql_text IS NULL THEN
RAISE_APPLICATION_ERROR(-20100, 'SQL_TEXT for SQL_ID &&sql_id. was not found in memory (gv$sqltext_with_newlines) or AWR (dba_hist_sqltext).');
END IF;
END;
/
PRO generate SQL Patch for SQL "&&sql_id." with CBO Hints "&&hint_text."
SELECT loaded_versions, invalidations, address, hash_value
FROM v$sqlarea WHERE sql_id = '&&sql_id.' ORDER BY 1;
SELECT child_number, plan_hash_value, executions, is_shareable
FROM v$sql WHERE sql_id = '&&sql_id.' ORDER BY 1, 2;
-- drop prior SQL Patch
WHENEVER SQLERROR CONTINUE;
PRO ignore errors
EXEC DBMS_SQLDIAG.DROP_SQL_PATCH(name => 'sqlpch_&&sql_id.');
WHENEVER SQLERROR EXIT SQL.SQLCODE;
-- create SQL Patch
PRO you have to connect as SYS
BEGIN
SYS.DBMS_SQLDIAG_INTERNAL.I_CREATE_PATCH (
sql_text => :sql_text,
hint_text => '&&hint_text.',
name => 'sqlpch_&&sql_id.',
category => 'DEFAULT',
description => '/*+ &&hint_text. */'
);
END;
/
-- flush cursor from shared_pool
PRO *** before flush ***
SELECT inst_id, loaded_versions, invalidations, address, hash_value
FROM gv$sqlarea WHERE sql_id = '&&sql_id.' ORDER BY 1;
SELECT inst_id, child_number, plan_hash_value, executions, is_shareable
FROM gv$sql WHERE sql_id = '&&sql_id.' ORDER BY 1, 2;
PRO *** flushing &&sql_id. ***
BEGIN
FOR i IN (SELECT address, hash_value
FROM gv$sqlarea WHERE sql_id = '&&sql_id.')
LOOP
DBMS_OUTPUT.PUT_LINE(i.address||','||i.hash_value);
BEGIN
SYS.DBMS_SHARED_POOL.PURGE (
name => i.address||','||i.hash_value,
flag => 'C'
);
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE(SQLERRM);
END;
END LOOP;
END;
/
PRO *** after flush ***
SELECT inst_id, loaded_versions, invalidations, address, hash_value
FROM gv$sqlarea WHERE sql_id = '&&sql_id.' ORDER BY 1;
SELECT inst_id, child_number, plan_hash_value, executions, is_shareable
FROM gv$sql WHERE sql_id = '&&sql_id.' ORDER BY 1, 2;
WHENEVER SQLERROR CONTINUE;
SET DEF ON TERM ON ECHO OFF FEED 6 VER ON HEA ON LIN 80 PAGES 14 LONG 80 LONGC 80 TRIMS OFF TI OFF TIMI OFF SERVEROUT OFF NUMF "" SQLP SQL>;
SET SERVEROUT OFF;
PRO
PRO SQL Patch "sqlpch_&&sql_id." will be used on next parse.
PRO To drop SQL Patch on this SQL:
PRO EXEC DBMS_SQLDIAG.DROP_SQL_PATCH(name => 'sqlpch_&&sql_id.');
PRO
UNDEFINE 1 2 sql_id_1 sql_id hint_text_2 hint_text
CL COL
PRO
PRO sqlpch completed.
SPO OFF;
Why using SQLTXPLAIN
Every so often I see on a distribution list a posting that starts like this: “I upgraded my application from database release X to release Y and now many queries are performing poorly, can you tell why?”
As everyone else on a distribution list, my first impulse is to make an educated guess permeated by a prior set of experiences. The intentions are always good, but the process is painful and time consuming. Many of us have seen this kind of question, and many of us have good hunches. Still I think our eagerness to help blinds us a bit. The right thing to do is to step back and analyze the facts, and I mean all the diagnostics supporting the observation.
What is needed to diagnose a SQL Tuning issue?
The list is large, but I will enumerate some of the most important pieces:
- SQL Text
- Version of the database (before and after upgrade)
- Database parameters (before and after)
- State of the CBO Statistics (before and after)
- Changes on Histograms
- Basics about the architecture (CPUs, memory, etc.)
- Values of binds if SQL has them
- Indexes compare, including state (visible?, usable?)
- Execution Plan (before and after)
- Plan stability? (Stored Outlines, Profiles, SQL Plan Management)
- Performance history as per evidence on AWR or StatsPack
- Trace from Event 10053 to understand the CBO
- Trace from Event 10046 level 8 or 12 to review Waits
- Active Session History (ASH) if 10046 is not available
I could keep adding bullets to the list, but I think you get the point: There are simply too many things to check! And each takes some time to collect. More important, the state of the system changes overtime, so you may need to re-collect the same diagnostics more than once.
SQLTXPLAIN to the rescue
SQLT or SQLTXPLAIN, has been available on MetaLink (now MOS) under note 215187.1 for over a decade. In short, SQLT collects all the diagnostics listed above and a lot more. That is WHY Oracle Support uses it every day. It simply saves a lot of time! So, I always encourage fellow Oracle users to make use of the FREE tool and expedite their own SQL Tuning analysis. When time permits, I do volunteer to help on an analysis. So, if you get to read this, and you want to help yourself while using SQLT but feel intimidated by this little monster, please give it a try and contact me for assistance. If I can help, I will, if I cannot, I will let you know.
Conclusion
It is fun to guess WHY a SQL is not performing as expected, and trying different guesses is educational but very time consuming. If you want to actually find root causes before trying to fix your SQL, you may want to collect relevant diagnostics. SQLT is there to help, and if installing this tool is not something you can do in a short term, consider then SQL Health-Check SQLHC.
SQL using Literals instead of Binds. Are all Literals evil?
Every so often I see systems where there is a good amount of SQL that uses Literals instead of Binds, and executes enough times to create a large number of Cursors. Is this a red flag? As many questions regarding performance, I would say the right answer is: it all depends.
Of course we want to use Binds instead of Literals in order to reduce the frequency of Hard Parses, and in turn reduce CPU consumption and space utilization in the Shared Pool. Does it mean we want to replace all Literals with Binds? Do we declare war on Literals? In my opinion, the answer is simply: NO.
If a SQL has a Predicate on a date column, or a key column, then I would expect the Number of Distinct Values (NDV) for such column to be high, and in some cases as high as the number of rows in the Table (unique values for example). In the other hand, if the Predicate is in one of those columns that denotes a code, like Process Type or Status, and the NDV is small, then I’d rather keep the Literal in place. Specially if the data in such column is skewed and I have (or plan to have) Histograms on it.
What do I propose?
- If the SQL is executed sporadically, then it does not matter (Literals or Binds).
- If the SQL executes frequently, and the Predicate in question is on a Column where the Number of Distinct Values (NDV) is high, then use a Bind instead of a Literal (for this Predicate).
- If the SQL executes frequently, and the Predicate in question is on a Column where the NDV is low, then use a Literal (for this Predicate). This assumes the NDV for these Literals is also small.
- Regardless if using a Literal or a Bind for a particular Predicate: If the data in a Column referenced by a Predicate is heavily skewed, gather Statistics with Histograms on this Column.
Follow-up question: When the NDV is high or low? The answer is also: it all depends. I personally prefer to see Literals if the NDV for this Column (and this Literal) is less than 10 (or so).
Why having Binds and Literals on same SQL is better than having all Binds?
If we have good set of CBO Statistics, and we have Histograms on skewed data, and we are using bind peeking, and we are on 11g, and Adaptive Cursor Sharing (ACS) is enabled, and we plan using SQL Plan Management (SPM), then we are for a treat:
With all the “ands” above, by using Binds on predicates with high NDV and Literals in those with low NDV, then we will end up having a small number of different SQL_IDs for what we consider “the same SQL”. Each incarnation of this SQL could potentially have its own set of optimal Execution Plans created by ACS and the CBO (by making use of Histograms on the data and Selectivity Profiles on ACS). Then, with the aid of SPM we could provide stability to those multiple optimal Execution Plans for each version of the SQL. That means that SQL Q1 with Literal L1 could have a different set of optimal plans than Q1 with Literals L2.
Conclusion
Replacing some Literals with Binds but not all Literals sounds like a lot of work, but actually the extra work may be worth the effort. In my opinion, the end result is better if we replace most, but not all (as per proposal above). WHY? Even when ACS does a good job at finding multiple optimal plans for a SQL by using the selectivity of the predicates; by allowing a small number of cursors for the same SQL given the use of Literals in columns with low NDV, we are basically reducing the times we would have to execute a SQL with a sub-optimal plan due to current ACS ramp-up process. This extra granularity provided by a small number of incarnations of the “otherwise same SQL” could be crucial for tuning complex SQL or corner cases.
Exadata Optimizations and SQLTXPLAIN Courses
I will be delivering a couple of courses soon. One in January and the second in February. I will keep posting upcoming Training and Conferences on a new link at the right margin of this blog.
Exadata Optimizations Jan 13-14
This 2-days “Exadata Optimizations” course is for Developers and DBAs new to Exadata and in need to ramp-up quickly. As the name implies, its focus is on Exadata Optimizations. We talk about Smart Scans, Storage Indexes, Smart Flash Cache, Hybrid Columnar Compression (HCC) and Parallel Execution (PX). This course is hands-on, with a fair amount of demos and labs.
SQLTXPLAIN (SQLT) Feb 20-21
This “SQL Tuning with SQLTXPLAIN” 2-days course shows how to use SQLT to actually do SQL Tuning. We go over the ying-yang of the CBO, meaning: Plan Flexibility versus Plan Stability. We use SQLT for labs and we also go over some real-life SQL Tuning cases. If you are currently using SQLT, you are welcome to bring a SQLT Report to class and we could review it there.
Conclusion
New year, new resolutions. I will be investing part of my time sharing knowledge through formal courses and conferences. These days it is hard to find the time and budget to keep our knowledge on the edge, but again and again I see that many of our daily struggles could be mitigated by some concise technical training. So I encourage you to add some training to your list of resolutions for this new year; or at the very least, to get and read some fresh books.
Happy New Year 2014!
SQL Tuning with SQLTXPLAIN 2-days Workshop
SQLTXPLAIN is a SQL Tuning tool widely used by the Oracle community. Available through My Oracle Support (MOS) under document 215187.1, this free tool is available for download and use to anyone with MOS access. It has helped thousands of times to expedite the resolution of SQL Tuning issues, and many Oracle DBAs and Developers benefit of its use on a daily basis.
Stelios Charalambides has done an excellent job writing a book on this topic. In his book Stelios covers many aspects about SQLTXPLAIN and some related topics. I highly recommend to get a copy of this book if you want to learn more about SQLTXPLAIN. It is available at Amazon and many other retailers.
The new 2-days SQLTXPLAIN Workshop offered by Enkitec (an Oracle Platinum business partner and my employer) is a completely new course that interleaves “how to use effectively SQLTXPLAIN” with important and related SQL Tuning Topics such as Plan Flexibility and Plan Stability. This hands-on workshop offers participants the unique opportunity to fully understand the contents of SQLTXPLAIN and its vast output through an interactive session. About half the time is dedicated to short guided labs, while the other half uses presentations and demos. This workshop is packed with lots of content. It was a real challenge packaging so much info in only two days, but I am very pleased with the result. It became a 2-days intensive knowledge transfer hands-on workshop on SQLTXPLAIN and SQL Tuning!
The first session of this workshop is scheduled for November 7-8 in Dallas, Texas. I expect this pilot session to fill out fast. Other sessions and onsite ones will be offered during 2014. I hope to meet many of you face to face on November 7!
