Poor’s man script to summarize reasons WHY cursors are not shared
Having a large number of child cursors can affect parsing performance as hinted by Abel Macias on his blog post about Diagnosis of a High Version Count (HVC). On his post, Abel also refers to a note on MOS which includes a script that dives into the reasons WHY our cursors are not getting shared. Then, for deep-dives in this area, I strongly suggest to read his post and use the referenced script provided at MOS.
Besides longer parse times, and potential library cache contention, manifested by some waits (such as on mutex), there is another side effect that may bite us: CBO may produce a different plan when a SQL statement is hard-parsed while creating a new child cursor. This latter side effect can be critical for transactional applications with SLA depending on very short latencies of some queries.
This post is about a poor’s man script, that with no installation whatsoever, it lists an aggregated summary of the reasons why our cursors are not shared, including child cursor counts and distinct SQL_IDs counts for each reason (see sample output below). I had to write such script since in our environments we cannot simply run diagnostics scripts that create objects in the database, such as the one provided by MOS.
CURSORS SQL_IDS REASON_NOT_SHARED
---------- ---------- -----------------------------
226916 7826 ROLL_INVALID_MISMATCH
29387 105 BIND_EQUIV_FAILURE
21794 4027 HASH_MATCH_FAILED
11588 2134 OPTIMIZER_MISMATCH
11027 413 BIND_LENGTH_UPGRADEABLE
11008 384 BIND_MISMATCH
10125 2697 USE_FEEDBACK_STATS
4540 109 OPTIMIZER_MODE_MISMATCH
1652 72 PURGED_CURSOR
1245 81 BIND_UACS_DIFF
1062 316 LANGUAGE_MISMATCH
771 103 LOAD_OPTIMIZER_STATS
500 52 STATS_ROW_MISMATCH
238 86 MV_QUERY_GEN_MISMATCH
94 3 MULTI_PX_MISMATCH
28 4 AUTH_CHECK_MISMATCH
23 1 INSUFF_PRIVS
Once I get to see some reasons for not sharing, some responsible for a large number of child cursors (and distinct SQL_IDs), then I can search on MOS as Abel suggested. Ideally, if you are interested in plan stability, you may want to reduce the times the CBO is tasked to create a new child cursor (and potentially a new Execution Plan).
In output sample above, top in our list is ROLL_INVALID_MISMATCH, causing 226,916 child cursors in as many as 7,826 SQL statements. This particular reason for not sharing cursors is due to a persistent gathering of schema object statistics with the explicit request to invalidate cursors. Since we want to promote plan stability, we would need to suspend such aggressive gathering of CBO statistics and validate reason ROLL_INVALID_MISMATCH is reduced.
Anyways, free script used is below. Enjoy it!
*** edited *** a new version of the script is now available (below). Thanks to stewashton for his input.
-- sql_shared_cursor.sql SET HEA OFF LIN 300 NEWP NONE PAGES 0 FEED OFF ECHO OFF VER OFF TRIMS ON TRIM ON TI OFF TIMI OFF SQLBL ON BLO . RECSEP OFF; SPO all_reasons.sql SELECT CASE WHEN ROWNUM = 1 THEN '( ' ELSE ', ' END||column_name FROM dba_tab_columns WHERE table_name = 'V_$SQL_SHARED_CURSOR' AND owner = 'SYS' AND data_type = 'VARCHAR2' AND data_length = 1 / SPO OFF; GET all_reasons.sql I ) I ) I WHERE value = 'Y' I GROUP BY reason_not_shared I ORDER BY cursors DESC, sql_ids DESC, reason_not_shared 0 ( value FOR reason_not_shared IN 0 FROM v$sql_shared_cursor UNPIVOT 0 SELECT COUNT(*) cursors, COUNT(DISTINCT sql_id) sql_ids, reason_not_shared L SET HEA ON NEWP 1 PAGES 30 PRO please wait / !rm all_reasons.sql
Script to identify index rebuild candidates on 12c
Some time back I blogged about an easy way to estimate the size of an index. It turns out there is an API that also uses the plan_table under the hood in order to estimate what would be the size of an index if it were rebuilt. Such API is DBMS_SPACE.CREATE_INDEX_COST.
Script below uses DBMS_SPACE.CREATE_INDEX_COST, and when executed on 12c connected into a PDB, it outputs a list of indexes with enlarged space, which if rebuilt they would shrink at least 25% their current size. This script depends on the accuracy of the CBO statistics.
Once you are comfortable with the output, you may even consider automating its execution using OEM. I will post in a few days a way to do that using DBMS_SQL. In the meantime, here I share the stand-alone version.
----------------------------------------------------------------------------------------
--
-- File name: indexes_2b_shrunk.sql
--
-- Purpose: List of candidate indexes to be shrunk (rebuild online)
--
-- Author: Carlos Sierra
--
-- Version: 2017/07/12
--
-- Usage: Execute on PDB
--
-- Example: @indexes_2b_shrunk.sql
--
-- Notes: Execute connected into a PDB.
-- Consider then:
-- ALTER INDEX [schema.]index REBUILD ONLINE;
--
---------------------------------------------------------------------------------------
-- select only those indexes with an estimated space saving percent greater than 25%
VAR savings_percent NUMBER;
EXEC :savings_percent := 25;
-- select only indexes with current size (as per cbo stats) greater then 1MB
VAR minimum_size_mb NUMBER;
EXEC :minimum_size_mb := 1;
SET SERVEROUT ON ECHO OFF FEED OFF VER OFF TAB OFF LINES 300;
COL report_date NEW_V report_date;
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD"T"HH24:MI:SS') report_date FROM DUAL;
SPO /tmp/indexes_2b_shrunk_&&report_date..txt;
DECLARE
l_used_bytes NUMBER;
l_alloc_bytes NUMBER;
l_percent NUMBER;
BEGIN
DBMS_OUTPUT.PUT_LINE('PDB: '||SYS_CONTEXT('USERENV', 'CON_NAME'));
DBMS_OUTPUT.PUT_LINE('---');
DBMS_OUTPUT.PUT_LINE(
RPAD('OWNER.INDEX_NAME', 35)||' '||
LPAD('SAVING %', 10)||' '||
LPAD('CURRENT SIZE', 20)||' '||
LPAD('ESTIMATED SIZE', 20));
DBMS_OUTPUT.PUT_LINE(
RPAD('-', 35, '-')||' '||
LPAD('-', 10, '-')||' '||
LPAD('-', 20, '-')||' '||
LPAD('-', 20, '-'));
FOR i IN (SELECT x.owner, x.index_name, SUM(s.leaf_blocks) * TO_NUMBER(p.value) index_size,
REPLACE(DBMS_METADATA.GET_DDL('INDEX',x.index_name,x.owner),CHR(10),CHR(32)) ddl
FROM dba_ind_statistics s, dba_indexes x, dba_users u, v$parameter p
WHERE u.oracle_maintained = 'N'
AND x.owner = u.username
AND x.tablespace_name NOT IN ('SYSTEM','SYSAUX')
AND x.index_type LIKE '%NORMAL%'
AND x.table_type = 'TABLE'
AND x.status = 'VALID'
AND x.temporary = 'N'
AND x.dropped = 'NO'
AND x.visibility = 'VISIBLE'
AND x.segment_created = 'YES'
AND x.orphaned_entries = 'NO'
AND p.name = 'db_block_size'
AND s.owner = x.owner
AND s.index_name = x.index_name
GROUP BY
x.owner, x.index_name, p.value
HAVING
SUM(s.leaf_blocks) * TO_NUMBER(p.value) > :minimum_size_mb * POWER(2,20)
ORDER BY
index_size DESC)
LOOP
DBMS_SPACE.CREATE_INDEX_COST(i.ddl,l_used_bytes,l_alloc_bytes);
IF i.index_size * (100 - :savings_percent) / 100 > l_alloc_bytes THEN
l_percent := 100 * (i.index_size - l_alloc_bytes) / i.index_size;
DBMS_OUTPUT.PUT_LINE(
RPAD(i.owner||'.'||i.index_name, 35)||' '||
LPAD(TO_CHAR(ROUND(l_percent, 1), '990.0')||' % ', 10)||' '||
LPAD(TO_CHAR(ROUND(i.index_size / POWER(2,20), 1), '999,999,990.0')||' MB', 20)||' '||
LPAD(TO_CHAR(ROUND(l_alloc_bytes / POWER(2,20), 1), '999,999,990.0')||' MB', 20));
END IF;
END LOOP;
END;
/
SPO OFF;
And if you want to try the DBMS_SPACE.CREATE_INDEX_COST API by itself, you can also grab the estimated size of the index after calling this API, using query below. But the API already returns that value!
SELECT TO_NUMBER(EXTRACTVALUE(VALUE(d), '/info')) index_size
FROM XMLTABLE('/*/info'
PASSING (SELECT XMLTYPE(other_xml)
FROM plan_table
WHERE other_xml LIKE '%index_size%')) d
WHERE EXTRACTVALUE(VALUE(d), '/info/@type') = 'index_size'
/
One Maintenance Window for all PDBs… Really?
Using the default Maintenance Window for automatic tasks such as statistics gathering and space advisor is just fine… except when the number of PDBs is large (in our case over 100 PDBs in one DB). And starting resource-intensive tasks regulated by the Maintenance Window cause CPU to spike when all PDBs start their weekday window at 10PM…
Why should I care that my CPU spikes at 100% when all 100+ PDBs start their Maintenance Window at 10PM? At that time I should be sleeping, right? Well, if your shop is a quasi 24×7, then such spikes can be noticeable to your users, and possibly affect SLAs.
The solution is to stagger the start time of the Maintenance Window for all your PDBs. For example, start one PDB at 10 PM and another at 10:30 and so on. If you want to start them all within a 4 hours interval, and if you have 100 PDBs, that means you can start 25 per hour. You may also want to reduce the window duration for each PDB from default of 4 hours to let’s say 1 hour. So you could start all within 4 hours, and have the last one close its window one hour later, thus the total time for all Maintenance Windows could be 5 hours, and you would had flattened the CPU spike.
In our case, since we are a 24×7 shop, and since in some cases one of the Tasks executed during the Maintenance Window invalidates a cursor that renders a new Execution Plan (waking at times the on-call DBA), then we decided to start our Maintenance Windows at 8 AM PST (15:00 UTC), and stagger all PDBs to start their window within 4 hours (between 15 and 19 UTC), then have each a duration of 1hr maximum. On weekends we can start at the same time, but allow all PDBs to start their window within 5 hours and with a maximum duration of 2hr. So on weekends we can open the first Maintenance Window at 8 AM PST, and the last one at 1 PM, while allowing each PDB to take up to 2hrs. This is not the ideal solution, but it is much better than opening the gate for 100+ PDBs all at the same time.
The fun part is how to apply such change to all databases in all regions, where basically on each server the databases on it would have a Maintenance Window that starts at different times for each of the PDBs. We ended up with script below, which takes some variables to specify start time, lapse of time where PDBs can start their Maintenance Window, and duration of it per PDB. This script is written in such a way that it can be executed using OEM targeting all databases. Feel free to use it in case you are dealing with PDBs and see CPU spikes caused by Maintenance Window and such spikes affect user experience.
</pre>
----------------------------------------------------------------------------------------
--
-- File name: pdb_windows.sql
--
-- Purpose: Sets staggered maintenance windows for all PDBs in order to avoid CPU
-- spikes caused by all PDBs starting their maintenance window at the same
-- time
--
-- Author: Carlos Sierra
--
-- Version: 2017/07/12
--
-- Usage: Execute as SYS on CDB
--
-- Example: @pdb_windows.sql
--
-- Notes:
-- Stagger PDBs maintenance windows to start at different times in order to
-- reduce CPU spikes, for example: all PDBs start their maintenance window
-- between 8AM PST and 10AM PST (2 hours), and each window lasts 4 hour,
-- so all maintenance tasks are executed between 8AM and 2PM PST.
-- Notice that in such example, 1st window opens at 8AM and last one opens
-- at 10AM. First closes at 12NOON and last at 2PM
-- Be aware that default cursor invalidation may happen a few hours (3 or 4)
-- after a maintenance window closes. Then, since most PDBs process their
-- tasks fast, actual cursor invalidation may happen between 11AM and 1PM.
--
---------------------------------------------------------------------------------------
SET LINES 300 SERVEROUTPUT ON
COL report_date NEW_V report_date;
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD"T"HH24-MI-SS') report_date FROM DUAL;
SPO /tmp/pdb_window_&&report_date..txt;
-- hour of the day (military format) when first maintenance window for a PDB may open during week days
-- i.e. if dbtimezone is UCT and we want to open 1st at 8AM PST we set to 15
VAR weekday_start_hh24 NUMBER;
EXEC :weekday_start_hh24 := 15;
-- for how many hours we want to open maintenance windows for PDBs during week days
-- i.e. if we want to open windows during a 2 hours interval we set to 2
VAR weekday_hours NUMBER;
EXEC :weekday_hours := 2;
-- how long we want the maintenance window to last for each PDB during week days
-- i.e. if we want each PDB to have a window of 4 hours then we set to 4
VAR weekday_duration NUMBER;
EXEC :weekday_duration := 4;
-- hour of the day (military format) when first maintenance window for a PDB may open during weekends
-- i.e. if dbtimezone is UCT and we want to open 1st at 8AM PST we set to 15
VAR weekend_start_hh24 NUMBER;
EXEC :weekend_start_hh24 := 15;
-- for how many hours we want to open maintenance windows for PDBs during weekends
-- i.e. if we want to open windows for 2 hours interval we set to 2
VAR weekend_hours NUMBER;
EXEC :weekend_hours := 2;
-- how long we want the maintenance window to last for each PDB during weekends
-- i.e. if we want each PDB to have a window of 8 hours then we set to 8
VAR weekend_duration NUMBER;
EXEC :weekend_duration := 8;
-- PL/SQL block to be executed on each PDB
VAR v_cursor CLOB;
BEGIN
:v_cursor := q'[
DECLARE
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
DBMS_SCHEDULER.SET_SCHEDULER_ATTRIBUTE('DEFAULT_TIMEZONE','+00:00');
DBMS_SCHEDULER.DISABLE('MONDAY_WINDOW', TRUE);
DBMS_SCHEDULER.SET_ATTRIBUTE('MONDAY_WINDOW', 'repeat_interval', 'freq=daily; byday=MON; byhour='||:b_weekdays_hh24||'; byminute='||:b_weekdays_mi||'; bysecond='||:b_weekdays_ss);
DBMS_SCHEDULER.SET_ATTRIBUTE('MONDAY_WINDOW', 'duration', TO_DSINTERVAL('+000 '||LPAD(:b_weekday_duration, 2, '0')||':00:00'));
DBMS_SCHEDULER.SET_ATTRIBUTE_NULL('MONDAY_WINDOW', 'resource_plan');
DBMS_SCHEDULER.ENABLE('MONDAY_WINDOW');
DBMS_SCHEDULER.DISABLE('TUESDAY_WINDOW', TRUE);
DBMS_SCHEDULER.SET_ATTRIBUTE('TUESDAY_WINDOW', 'repeat_interval', 'freq=daily; byday=TUE; byhour='||:b_weekdays_hh24||'; byminute='||:b_weekdays_mi||'; bysecond='||:b_weekdays_ss);
DBMS_SCHEDULER.SET_ATTRIBUTE('TUESDAY_WINDOW', 'duration', TO_DSINTERVAL('+000 '||LPAD(:b_weekday_duration, 2, '0')||':00:00'));
DBMS_SCHEDULER.SET_ATTRIBUTE_NULL('TUESDAY_WINDOW', 'resource_plan');
DBMS_SCHEDULER.ENABLE('TUESDAY_WINDOW');
DBMS_SCHEDULER.DISABLE('WEDNESDAY_WINDOW', TRUE);
DBMS_SCHEDULER.SET_ATTRIBUTE('WEDNESDAY_WINDOW', 'repeat_interval', 'freq=daily; byday=WED; byhour='||:b_weekdays_hh24||'; byminute='||:b_weekdays_mi||'; bysecond='||:b_weekdays_ss);
DBMS_SCHEDULER.SET_ATTRIBUTE('WEDNESDAY_WINDOW', 'duration', TO_DSINTERVAL('+000 '||LPAD(:b_weekday_duration, 2, '0')||':00:00'));
DBMS_SCHEDULER.SET_ATTRIBUTE_NULL('WEDNESDAY_WINDOW', 'resource_plan');
DBMS_SCHEDULER.ENABLE('WEDNESDAY_WINDOW');
DBMS_SCHEDULER.DISABLE('THURSDAY_WINDOW', TRUE);
DBMS_SCHEDULER.SET_ATTRIBUTE('THURSDAY_WINDOW', 'repeat_interval', 'freq=daily; byday=THU; byhour='||:b_weekdays_hh24||'; byminute='||:b_weekdays_mi||'; bysecond='||:b_weekdays_ss);
DBMS_SCHEDULER.SET_ATTRIBUTE('THURSDAY_WINDOW', 'duration', TO_DSINTERVAL('+000 '||LPAD(:b_weekday_duration, 2, '0')||':00:00'));
DBMS_SCHEDULER.SET_ATTRIBUTE_NULL('THURSDAY_WINDOW', 'resource_plan');
DBMS_SCHEDULER.ENABLE('THURSDAY_WINDOW');
DBMS_SCHEDULER.DISABLE('FRIDAY_WINDOW', TRUE);
DBMS_SCHEDULER.SET_ATTRIBUTE('FRIDAY_WINDOW', 'repeat_interval', 'freq=daily; byday=FRI; byhour='||:b_weekdays_hh24||'; byminute='||:b_weekdays_mi||'; bysecond='||:b_weekdays_ss);
DBMS_SCHEDULER.SET_ATTRIBUTE('FRIDAY_WINDOW', 'duration', TO_DSINTERVAL('+000 '||LPAD(:b_weekday_duration, 2, '0')||':00:00'));
DBMS_SCHEDULER.SET_ATTRIBUTE_NULL('FRIDAY_WINDOW', 'resource_plan');
DBMS_SCHEDULER.ENABLE('FRIDAY_WINDOW');
DBMS_SCHEDULER.DISABLE('SATURDAY_WINDOW', TRUE);
DBMS_SCHEDULER.SET_ATTRIBUTE('SATURDAY_WINDOW', 'repeat_interval', 'freq=daily; byday=SAT; byhour='||:b_weekends_hh24||'; byminute='||:b_weekends_mi||'; bysecond='||:b_weekends_ss);
DBMS_SCHEDULER.SET_ATTRIBUTE('SATURDAY_WINDOW', 'duration', TO_DSINTERVAL('+000 '||LPAD(:b_weekend_duration, 2, '0')||':00:00'));
DBMS_SCHEDULER.SET_ATTRIBUTE_NULL('SATURDAY_WINDOW', 'resource_plan');
DBMS_SCHEDULER.ENABLE('SATURDAY_WINDOW');
DBMS_SCHEDULER.DISABLE('SUNDAY_WINDOW', TRUE);
DBMS_SCHEDULER.SET_ATTRIBUTE('SUNDAY_WINDOW', 'repeat_interval', 'freq=daily; byday=SUN; byhour='||:b_weekends_hh24||'; byminute='||:b_weekends_mi||'; bysecond='||:b_weekends_ss);
DBMS_SCHEDULER.SET_ATTRIBUTE('SUNDAY_WINDOW', 'duration', TO_DSINTERVAL('+000 '||LPAD(:b_weekend_duration, 2, '0')||':00:00'));
DBMS_SCHEDULER.SET_ATTRIBUTE_NULL('SUNDAY_WINDOW', 'resource_plan');
DBMS_SCHEDULER.ENABLE('SUNDAY_WINDOW');
-- Weeknight window - for compatibility only - KEEP IT DISABLED
DBMS_SCHEDULER.DISABLE('WEEKNIGHT_WINDOW', TRUE);
DBMS_SCHEDULER.SET_ATTRIBUTE('WEEKNIGHT_WINDOW', 'repeat_interval', 'freq=daily; byday=MON,TUE,WED,THU,FRI; byhour='||:b_weekdays_hh24||'; byminute='||:b_weekdays_mi||'; bysecond='||:b_weekdays_ss);
DBMS_SCHEDULER.SET_ATTRIBUTE('WEEKNIGHT_WINDOW', 'duration', TO_DSINTERVAL('+000 '||LPAD(:b_weekday_duration, 2, '0')||':00:00'));
--DBMS_SCHEDULER.ENABLE('WEEKNIGHT_WINDOW'); KEEP IT DISABLED - Weeknight window - for compatibility only
-- Weekend window - for compatibility only - KEEP IT DISABLED
DBMS_SCHEDULER.DISABLE('WEEKEND_WINDOW', TRUE);
DBMS_SCHEDULER.SET_ATTRIBUTE('WEEKEND_WINDOW', 'repeat_interval', 'freq=daily; byday=SAT,SUN; byhour='||:b_weekends_hh24||'; byminute='||:b_weekends_mi||'; bysecond='||:b_weekends_ss);
DBMS_SCHEDULER.SET_ATTRIBUTE('WEEKEND_WINDOW', 'duration', TO_DSINTERVAL('+000 '||LPAD(:b_weekend_duration, 2, '0')||':00:00'));
--DBMS_SCHEDULER.ENABLE('WEEKEND_WINDOW'); KEEP IT DISABLED - Weekend window - for compatibility only
COMMIT;
END;
]';
END;
/
PRINT v_cursor;
DECLARE
l_cursor_id INTEGER;
l_rows_processed INTEGER;
BEGIN
l_cursor_id := DBMS_SQL.OPEN_CURSOR;
FOR i IN (WITH
pdbs AS ( -- list of PDBs ordered by CON_ID with enumerator as rank_num
SELECT con_id, name, RANK () OVER (ORDER BY con_id) rank_num FROM v$containers WHERE con_id <> 2
),
slot AS ( -- PDBs count
SELECT MAX(rank_num) count FROM pdbs
),
start_time AS (
SELECT con_id, name,
(TRUNC(SYSDATE) + (:weekday_start_hh24 / 24) + ((pdbs.rank_num - 1) * :weekday_hours / (slot.count - 1) / 24)) weekdays,
(TRUNC(SYSDATE) + (:weekend_start_hh24 / 24) + ((pdbs.rank_num - 1) * :weekend_hours / (slot.count - 1) / 24)) weekends
FROM pdbs, slot
WHERE slot.count > 1
)
SELECT con_id, name,
TO_CHAR(weekdays, 'HH24') weekdays_hh24, TO_CHAR(weekdays, 'MI') weekdays_mi, TO_CHAR(weekdays, 'SS') weekdays_ss,
TO_CHAR(weekends, 'HH24') weekends_hh24, TO_CHAR(weekends, 'MI') weekends_mi, TO_CHAR(weekends, 'SS') weekends_ss
FROM start_time
ORDER BY
con_id)
LOOP
DBMS_OUTPUT.PUT_LINE('PDB:'||i.name||' weekdays:'||i.weekdays_hh24||':'||i.weekdays_mi||':'||i.weekdays_ss||' duration:'||:weekday_duration||'h weekends:'||i.weekends_hh24||':'||i.weekends_mi||':'||i.weekends_ss||' duration:'||:weekend_duration||'h');
DBMS_SQL.PARSE(c => l_cursor_id, statement => :v_cursor, language_flag => DBMS_SQL.NATIVE, container => i.name);
DBMS_SQL.BIND_VARIABLE(c => l_cursor_id, name => 'b_weekdays_hh24', value => i.weekdays_hh24);
DBMS_SQL.BIND_VARIABLE(c => l_cursor_id, name => 'b_weekdays_mi', value => i.weekdays_mi);
DBMS_SQL.BIND_VARIABLE(c => l_cursor_id, name => 'b_weekdays_ss', value => i.weekdays_ss);
DBMS_SQL.BIND_VARIABLE(c => l_cursor_id, name => 'b_weekday_duration', value => :weekday_duration);
DBMS_SQL.BIND_VARIABLE(c => l_cursor_id, name => 'b_weekends_hh24', value => i.weekends_hh24);
DBMS_SQL.BIND_VARIABLE(c => l_cursor_id, name => 'b_weekends_mi', value => i.weekends_mi);
DBMS_SQL.BIND_VARIABLE(c => l_cursor_id, name => 'b_weekends_ss', value => i.weekends_ss);
DBMS_SQL.BIND_VARIABLE(c => l_cursor_id, name => 'b_weekend_duration', value => :weekend_duration);
l_rows_processed := DBMS_SQL.EXECUTE(c => l_cursor_id);
END LOOP;
DBMS_SQL.CLOSE_CURSOR(c => l_cursor_id);
END;
/
SPO OFF;
<pre>
How to execute some SQL in all Pluggable Databases (PDBs)
If you are on 12c (and you should) and your database is truly multitenant, you may be in need to execute some SQL in all PDBs. OEM is awesome when it comes to executing a Job in a set of databases, and if such Job is a SQL Script then you can write it to do the same SQL in each PDB out of the set, as long as it is not a Standby. I have seen SQL Scripts doing that, making use of dynamic SQL and generating “ALTER SESSION SET CONTAINER = xxx” commands, spooled to a text file and executing such text file trusting its content. This approach works fine but is not very clean, and opens the door to some issues about the spooled file. I won’t get into the details, but one is security…
In order to avoid using a spool file with dynamic SQL, and having the parent script trust that such dynamic script is indeed available and legit, what I am proposing here is the use of oldie DBMS_SQL, and still do dynamic SQL but self contained. Look at sample code below, this script simply enables those tasks out of the Auto Task set provided by Oracle. Of course this script below assumes that someone has disabled one or more of the three tasks in some PDBs… or maybe in all of them, and that some Databases out of the farm may have the same issue… So if in this example we just want to enable all 3 tasks in all PDBs for all databases in farm, then we could schedule sample script as an OEM Job, and execute it every once in a while.
Anyways, enjoy the sample script and consider using it for other purposes. Nothing new, but just a simple and clean case of using DBMS_SQL on multitenant, while avoiding having to execute a script generated by another script and all the headaches that such action may cause when something goes wrong.
COL report_date NEW_V report_date;
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD"T"HH24-MI-SS') report_date FROM DUAL;
SPO /tmp/change_all_pdbs_&&report_date..txt;
VAR v_cursor CLOB;
BEGIN
:v_cursor := q'[
DECLARE
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
DBMS_OUTPUT.PUT_LINE('ENABLE DBMS_AUTO_TASK_ADMIN');
DBMS_AUTO_TASK_ADMIN.ENABLE;
FOR i IN (SELECT client_name, operation_name
FROM dba_autotask_operation
WHERE status = 'DISABLED'
ORDER BY 1, 2)
LOOP
DBMS_OUTPUT.PUT_LINE('ENABLE CLIENT_NAME:'||i.client_name||' OPERATION:'||i.operation_name);
DBMS_AUTO_TASK_ADMIN.ENABLE
( client_name => i.client_name
, operation => NULL
, window_name => NULL
);
END LOOP;
COMMIT;
END;
]';
END;
/
PRINT v_cursor;
SET SERVEROUTPUT ON
DECLARE
l_cursor_id INTEGER;
l_rows_processed INTEGER;
BEGIN
l_cursor_id := DBMS_SQL.OPEN_CURSOR;
FOR i IN (SELECT name
FROM v$containers
WHERE con_id > 2
AND open_mode = 'READ WRITE'
ORDER BY 1)
LOOP
DBMS_OUTPUT.PUT_LINE('PDB:'||i.name);
DBMS_SQL.PARSE
( c => l_cursor_id
, statement => :v_cursor
, language_flag => DBMS_SQL.NATIVE
, container => i.name
);
l_rows_processed := DBMS_SQL.EXECUTE(c => l_cursor_id);
END LOOP;
DBMS_SQL.CLOSE_CURSOR(c => l_cursor_id);
END;
/
SPO OFF;
eDB360 meets eAdam 3.0 – when two heads are better than one!

Version v1711 of eDB360 invites eAdam 3.0 to the party. What does it mean? We recently learned that eDB360 v1706 introduced the eDB360 repository, which materialized the content of 26 core DBA_HIST views into a staging repository made of heap tables. This in order to expedite the execution of eDB360 on a database with an enlarged AWR. New version v1711 expands the list from 26 views to a total of 219. And these 219 views include now DBA_HIST, DBA, GV$ and V$.
Expanding existing eDB360 repository 8.4x from 26 to 219 views is not what is key on version v1710. The real impact of the latest version of eDB360 is that now it benefits of eAdam 3.0, providing the same benefits of the 219 views of the eDB360 heap-tables repository, but using External Tables, which are easily transported from a source database to a target database. This simple fact opens many doors.
Using the eAdam 3.0 repository from eDB360, we can now extract the metadata from a production database, then restore it on a staging database where we can produce the eDB360 report for the source database. We could also use this new external repository for: finer-granularity data mining; capacity planning; sizing for potential hardware refresh; provisioning tools; to estimate candidate segments for partitioning or for offloading into Hadoop; etc.
With the new external-tables eAdam 3.0 repository, we could easily build a permanent larger heap-table permanent repository for multiple databases (multiple tenants), or for multiple time versions of the same database. Thus, now that eDB360 has met eAdam 3.0, the combination of these two enables multiple innovative future features (custom or to be packaged and shipped with eDB360).
eDB360 recap
eDB360 is a free tool that gives a 360-degree view of an Oracle database. It installs nothing on the database, and it runs on 10g to 12c Oracle databases. It is designed for Linux and UNIX, but runs well on Windows as well (you may want to install first UNIX Utilities UnxUtils and a zip program, else a few OS commands may not properly work on Windows). This repository-less version is the default way to use eDB360, and is the right method for most cases. But now, in addition to the default use, eDB360 can also make use of one of two repositories.
eDB360 takes time to execute (several hours). It is designed to time-out after 24 hours by default. First reason for long execution times is the intentional serial-processing method used, with sequential execution of query after query, while consuming little resources. Such serial execution, plus the fact that it is common to have the tool execute on large databases where the state of AWR is suboptimal, causes the execution to take long. We often discover that source AWR repositories lack expected partitioning, and in many cases they hold years of data instead of expected 8 to 31 days. Therefore, the nature of serial-execution combined with enlarged and suboptimal AWR repositories, usually cause eDB360 to execute for many hours more than expected. With 8 to 31 days of AWR data, and when such reasonable history is well partitioned, eDB360 usually executes in less than 6 hours.
To overcome the undesired extended execution times of eDB360, and besides the obvious (partition and purge AWR), the tool provides the capability to execute in multiple threads splitting its content by column. And now, in addition to the divide-and-conquer approach of column execution, eDB360 provides 2 repositories with different objectives in mind:
- eDB360 repository: Use this method to create a staging repository based on heap tables inside the source database. This method helps to expedite the execution of eDB360 by at least 10x. Repository heap-tables are created and consumed inside the same database.
- eAdam3 repository: Use this method to generate a repository based on external tables on the source database. Such external-tables repository can be moved easily to a remote target system, allowing to efficiently generate the eDB360 report there. This method helps to reduce computations in the source database, and enables potential data mining on the external repository without any resources impact on the source database. This method also helps to build other functions on top of the 219-tables repository.
Views included on both eDB360 and eAdam3 repositories:
- dba_2pc_neighbors
- dba_2pc_pending
- dba_all_tables
- dba_audit_mgmt_config_params
- dba_autotask_client
- dba_autotask_client_history
- dba_cons_columns
- dba_constraints
- dba_data_files
- dba_db_links
- dba_extents
- dba_external_tables
- dba_feature_usage_statistics
- dba_free_space
- dba_high_water_mark_statistics
- dba_hist_active_sess_history
- dba_hist_database_instance
- dba_hist_event_histogram
- dba_hist_ic_client_stats
- dba_hist_ic_device_stats
- dba_hist_interconnect_pings
- dba_hist_memory_resize_ops
- dba_hist_memory_target_advice
- dba_hist_osstat
- dba_hist_parameter
- dba_hist_pgastat
- dba_hist_resource_limit
- dba_hist_seg_stat
- dba_hist_service_name
- dba_hist_sga
- dba_hist_sgastat
- dba_hist_snapshot
- dba_hist_sql_plan
- dba_hist_sqlstat
- dba_hist_sqltext
- dba_hist_sys_time_model
- dba_hist_sysmetric_history
- dba_hist_sysmetric_summary
- dba_hist_sysstat
- dba_hist_system_event
- dba_hist_tbspc_space_usage
- dba_hist_wr_control
- dba_ind_columns
- dba_ind_partitions
- dba_ind_statistics
- dba_ind_subpartitions
- dba_indexes
- dba_jobs
- dba_jobs_running
- dba_lob_partitions
- dba_lob_subpartitions
- dba_lobs
- dba_obj_audit_opts
- dba_objects
- dba_pdbs
- dba_priv_audit_opts
- dba_procedures
- dba_profiles
- dba_recyclebin
- dba_registry
- dba_registry_hierarchy
- dba_registry_history
- dba_registry_sqlpatch
- dba_role_privs
- dba_roles
- dba_rsrc_consumer_group_privs
- dba_rsrc_consumer_groups
- dba_rsrc_group_mappings
- dba_rsrc_io_calibrate
- dba_rsrc_mapping_priority
- dba_rsrc_plan_directives
- dba_rsrc_plans
- dba_scheduler_job_log
- dba_scheduler_jobs
- dba_scheduler_windows
- dba_scheduler_wingroup_members
- dba_segments
- dba_sequences
- dba_source
- dba_sql_patches
- dba_sql_plan_baselines
- dba_sql_plan_dir_objects
- dba_sql_plan_directives
- dba_sql_profiles
- dba_stat_extensions
- dba_stmt_audit_opts
- dba_synonyms
- dba_sys_privs
- dba_tab_cols
- dba_tab_columns
- dba_tab_modifications
- dba_tab_partitions
- dba_tab_privs
- dba_tab_statistics
- dba_tab_subpartitions
- dba_tables
- dba_tablespace_groups
- dba_tablespaces
- dba_temp_files
- dba_triggers
- dba_ts_quotas
- dba_unused_col_tabs
- dba_users
- dba_views
- gv$active_session_history
- gv$archive_dest
- gv$archived_log
- gv$asm_disk_iostat
- gv$database
- gv$dataguard_status
- gv$event_name
- gv$eventmetric
- gv$instance
- gv$instance_recovery
- gv$latch
- gv$license
- gv$managed_standby
- gv$memory_current_resize_ops
- gv$memory_dynamic_components
- gv$memory_resize_ops
- gv$memory_target_advice
- gv$open_cursor
- gv$osstat
- gv$parameter
- gv$pga_target_advice
- gv$pgastat
- gv$pq_slave
- gv$pq_sysstat
- gv$process
- gv$process_memory
- gv$px_buffer_advice
- gv$px_process
- gv$px_process_sysstat
- gv$px_session
- gv$px_sesstat
- gv$resource_limit
- gv$result_cache_memory
- gv$result_cache_statistics
- gv$rsrc_cons_group_history
- gv$rsrc_consumer_group
- gv$rsrc_plan
- gv$rsrc_plan_history
- gv$rsrc_session_info
- gv$rsrcmgrmetric
- gv$rsrcmgrmetric_history
- gv$segstat
- gv$services
- gv$session
- gv$session_blockers
- gv$session_wait
- gv$sga
- gv$sga_target_advice
- gv$sgainfo
- gv$sgastat
- gv$sql
- gv$sql_monitor
- gv$sql_plan
- gv$sql_shared_cursor
- gv$sql_workarea_histogram
- gv$sysmetric
- gv$sysmetric_summary
- gv$sysstat
- gv$system_parameter2
- gv$system_wait_class
- gv$temp_extent_pool
- gv$undostat
- gv$waitclassmetric
- gv$waitstat
- v$archive_dest_status
- v$archived_log
- v$ash_info
- v$asm_attribute
- v$asm_client
- v$asm_disk
- v$asm_disk_stat
- v$asm_diskgroup
- v$asm_diskgroup_stat
- v$asm_file
- v$asm_template
- v$backup
- v$backup_set_details
- v$block_change_tracking
- v$cell_config
- v$cell_state
- v$controlfile
- v$database
- v$database_block_corruption
- v$datafile
- v$flashback_database_log
- v$flashback_database_stat
- v$instance
- v$io_outlier
- v$iostat_file
- v$kernel_io_outlier
- v$lgwrio_outlier
- v$log
- v$log_history
- v$logfile
- v$mystat
- v$nonlogged_block
- v$option
- v$parallel_degree_limit_mth
- v$parameter
- v$pdbs
- v$recovery_area_usage
- v$recovery_file_dest
- v$restore_point
- v$rman_backup_job_details
- v$rman_output
- v$segstat
- v$spparameter
- v$standby_log
- v$sys_time_model
- v$sysaux_occupants
- v$system_parameter2
- v$tablespace
- v$tempfile
- v$thread
- v$version
Instructions to use eDB360 and eAdam3 repositories
Both repositories are implemented under the edb360-master/repo subdirectory. Each has a readme file, which explains how to create the repository, consume it and drop it. The eAdam3 repository also includes instructions how to clone an external-table-based eAdam repository into a heap-table-based eDB360 repository.
Executing eDB360 on the eDB360 repository is faster than executing it on the eAdam3 repository, while avoiding new bug 25802477. This new Oracle database bug inflicts compressed external-tables like the ones used by the eAdam3 repository.
If you use eDB360 or eAdam3 repositories and have questions or concerns, do not hesitate to contact the author.
“ORA-00997: illegal use of LONG datatype” on a CTAS querying a view with a LONG column
Working on the new eDB360 repository I came across this “ORA-00997: illegal use of LONG datatype” while trying to CTAS on the following DBA views:
dba_constraints
dba_ind_partitions
dba_ind_subpartitions
dba_tab_cols
dba_tab_columns
dba_tab_partitions
dba_tab_subpartitions
dba_triggers
dba_views
All these views above include at least a LONG column, which raises the ORA-00997 while trying to do something like: CREATE TABLE edb360.dba#constraints AS SELECT * FROM dba_constraints.
I found several blogs explaining reason and some providing some hints, like using the TO_LOB function. Based on that I created a new stand-alone script that inputs 4 parameters and performs the CTAS I need. The 4 parameters are:
1: owner of source table/view
2: source table/view name
3: owner of target table
4: target table name
I am making this free script available for others to use at will.
-- How to solve ORA-00997: illegal use of LONG datatype while copying tables
-- paramaters
-- 1: owner of source table/view
-- 2: source table/view name
-- 3: owner of target table
-- 4: target table name
-- sample: @repo_edb360_create_one sys dba_constraints edb360 dba#constraints
DEF owner_source = '&1.';
DEF table_source = '&2.';
DEF owner_target = '&3.';
DEF table_target = '&4.';
DECLARE
l_list_ddl VARCHAR2(32767);
l_list_sel VARCHAR2(32767);
l_list_ins VARCHAR2(32767);
BEGIN
FOR i IN (SELECT column_name, data_type, data_length FROM dba_tab_columns WHERE owner = UPPER(TRIM('&&owner_source.')) and table_name = UPPER(TRIM('&&table_source.')) ORDER BY column_id)
LOOP
l_list_ddl := l_list_ddl||','||i.column_name||' '||REPLACE(i.data_type,'LONG','CLOB');
l_list_ins := l_list_ins||','||i.column_name;
IF i.data_type IN ('VARCHAR2', 'CHAR', 'RAW') THEN
l_list_ddl := l_list_ddl||'('||i.data_length||')';
END IF;
IF i.data_type = 'LONG' THEN
l_list_sel := l_list_sel||',TO_LOB('||i.column_name||')';
ELSE
l_list_sel := l_list_sel||','||i.column_name;
END IF;
END LOOP;
EXECUTE IMMEDIATE 'CREATE TABLE &&owner_target..&&table_target. ('||TRIM(',' FROM l_list_ddl)||') COMPRESS';
EXECUTE IMMEDIATE 'INSERT /*+ APPEND */ INTO &&owner_target..&&table_target. ('||TRIM(',' FROM l_list_ins)||') SELECT '||TRIM(',' FROM l_list_sel)||' FROM &&owner_source..&&table_source.';
EXECUTE IMMEDIATE 'COMMIT';
END;
/
eDB360 new features (March 2017)

As many of you know, eDB360 is a free tool that provides a 360-degree view of an Oracle database without any installation. A new version is available like once per month, but occasionally a large number of enhancements are implemented at once. This new release v1708 (March 25, 2017) includes several new features requested recently by some users of the tool, thus the need to blog about what is new:
- Reducing the scope of eDB360 is now possible without having to generate a custom configuration file. Prior to this version, if a user wanted to generate output for let’s say AWR reports only (section 7a), the tool needed a custom.sql file with line DEF edb360_sections = ‘7a’;. Then we would pass to edb360.sql as 2nd execution parameter the name of this custom configuration file (too cumbersome!). Starting on v1708, we can directly pass to edb360.sql the section that we desire (i.e. SQL> @edb360 T 7a). This 2nd parameter can either input the name of a custom configuration file (legacy functionality), but now it also accepts a column, a section, a list of columns or a list of sections; for example: 7a, 7, 7a-7b, 1-4 and 3 are all valid values.
- A couple of reports were added to section 3h: “SQL in logon storms” and “SQL executed row-by-row”. The former identifies those SQL statements that are seen frequently on very short-lived sessions (based on ASH), and the latter presents a list of SQL statements with large number of executions and small number of rows processed.
- eDB360 now extracts ASH from eAdam for top 16 SQL_ID (as per SQLd360 list) + top 12 SNAP_ID (as per AWR MAX from column 7a). What it means is that eDB360 includes now a tar file with raw ASH data for both: SQL statements of interest and for AWR periods of interest (both according to what eDB360 considers important). Using eAdam is easy, so when content of eDB360 does not include a very specific aggregation of ASH data that we need, or when we have to understand the sequence of some ASH samples for example, we can then restore this eAdam data on any Oracle database and data mine it.
- Some reports on section 2b show now totals at the bottom. That is to SUM some numeric values. Other reports may follow in future releases.
- RMAN section includes now a new report “Blocks with Corruption or Non-logged”.
- Added Load Profile (Per Sec, Per Txn and Count) as per DBA_HIST_SYSMETRIC_SUMMARY. This Load Profile resembles what we see on AWR at the top, but this is computed for the entire period of diagnostics (31 days by default). It shows max values, average, median and several percentiles. With this new report on section 1a, we can glance over it and discover in minutes some areas of further interest, for example: logons per second too high, just to mention one.
- There is a new section 4i with “Waits Count v.s. Average Latency for top 24 Wait Events”. With this set of 24 reports (one for each of the top wait events) we can observe if patterns on the number of counts relate to patterns on the latency for such wait event; for example we are able to see if an increase in the number of waits for db file sequential reads correlates to an increase of average latency for such wait event. We can also observe cases were latency for a wait event cannot be explained by load on current database, thus hinting an external influence.
- Fixed “ORA-01476: divisor is equal to zero” on planx at DBA_HIST_SQLSTAT.
- Added AWR DIFF reports for RAC and per instance. These are computed comparing MAX reports to MEDIAN reports, and they help to quickly identify large differences on load. These new AWR DIFF reports are regulated by configuration parameter edb360_conf_incl_addm_rpt (enabled by default). They exist on 11R2 and higher.
- Added the ASH Analytics Active report for 12c. This new ASH report is regulated by configuration parameter edb360_conf_incl_ash_analy_rpt (enabled by default). This applies to 12c and higher.
- The name of the database is now part of the main filename. Some users requested to include this database name as part of the main zip file since they are using eDB360 periodically on several databases. This new feature is regulated by configuration parameter edb360_conf_incl_dbname_file (disabled by default).
- At completion, main eDB360 zip file can now by automatically moved to a location other than the standard SQL*Plus working directory. All output files are still generated on the local SQL*Plus directory from where the script edb360.sql is executed (i.e. edb360-master directory), but at the completion of the execution the consolidated output zip file is now moved to a location specified by a new parameter. This new feature is regulated by configuration parameter edb360_move_directory (disabled by default).
- Added new report on “Database and Schema Triggers” under column 3h. This new report can be used to see potential LOGON or other global triggers. For triggers on specific tables, refer to SQLd360 which is automatically included on eDB360 for top SQL.
- All queries executed by eDB360 to generate its output were modified. New format is q'[query]’. Reason for this change is to improve readability of the code.
Always download and use the latest version of this tool. For questions or feedback email me. And I hope you get to enjoy eDB360 as much as I do!
eDB360 includes now an optional staging repository
eDB360 has always worked under the premise “no installation required”, and still is the case today – it is part of its fundamental essence: give me a 360-degree view of my Oracle database with no installation whatsoever. With that in mind, this free tool helps sites that have gone to the cloud, as well as those with “on-premises” databases; and in both cases not installing anything certainly expedites diagnostics collections. With eDB360, you simply connect to SQL*Plus with an account that can select from the catalog, execute then a set of scripts behind eDB360 and bingo!, you get to understand what is going on with your database just by navigating the html output. With such functionality, we can remotely diagnose a database, and even elaborate on the full health-check of it. After all, that is how we successfully use it every day!, saving us hundreds of hours of metadata gathering and cross-reference analysis.
Starting with release v1706, eDB360 also supports an optional staging repository of the 26 AWR views listed below. Why? the answer is simple: improved performance! This can be quite significant on large databases with hundreds of active sessions, with frequent snapshots, or with a long history on AWR. We have seen cases where years of data are “stuck” on AWR, specially in older releases of the database. Of course cleaning up the outdated AWR history (and corresponding statistics) is highly recommended, but in the meantime trying to execute edb360 on such databases may lead to long execution hours and frustration, taking sometimes days for what should take only a few hours.
- dba_hist_active_sess_history
- dba_hist_database_instance
- dba_hist_event_histogram
- dba_hist_ic_client_stats
- dba_hist_ic_device_stats
- dba_hist_interconnect_pings
- dba_hist_memory_resize_ops
- dba_hist_memory_target_advice
- dba_hist_osstat
- dba_hist_parameter
- dba_hist_pgastat
- dba_hist_resource_limit
- dba_hist_service_name
- dba_hist_sga
- dba_hist_sgastat
- dba_hist_sql_plan
- dba_hist_sqlstat
- dba_hist_sqltext
- dba_hist_sys_time_model
- dba_hist_sysmetric_history
- dba_hist_sysmetric_summary
- dba_hist_sysstat
- dba_hist_system_event
- dba_hist_tbspc_space_usage
- dba_hist_wr_control
- dba_hist_snapshot
Thus, if you are contemplating executing eDB360 on a large database, and provided pre-check script edb360-master/sql/awr_ash_pre_check.sql shows that eDB360 might take over 24 hours, then while you clean up your AWR repository you can use the eDB360 staging repository as a workaround to speedup eDB360 execution. The use of this optional staging repository is very simple, just look inside the edb360-master/repo directory for instructions. And as always, shoot me an email or comment here if there were any questions.
eDB360 takes long to execute!
eDB360 provides a lot of insight about an Oracle database. It executes thousands of SQL statements querying GV$ and DBA views from the Oracle’s data dictionary. It was designed to impose very little load on the system where it executes, thus it consumes only one session and avoids parallel execution. On a system where the state of historical metrics is “normal”, eDB360 may take one or two hours to execute. In the other hand, when the volume of historical metrics is abnormally “large”, then eDB360 may execute for many hours up to default threshold of 24, then quit. No worries here, it can be restarted pretty much where it left…
If you are considering executing eDB360 on one of your databases, before you do please execute first a light-weight “pre-check”, which is basically a small script that reports on the state of Active Session History (ASH) stored into the Automatic Workload Repository (AWR). Bare in mind that ASH and AWR are part of the Oracle Diagnostics Pack, so consider such “pre-check” only if you have a license for such Oracle Pack for the target database.
AWR ASH Pre-Check
You can execute stand-alone the awr_ash_pre_check.sql script available as free software in GitHub within edb360-master or cscripts-master. If downloading eDB360, you can find awr_ash_pre_check.sql under the edb360-master/sql directory, and if you download the cscripts set, then you can find awr_ash_pre_check.sql under cscripts-master/sql.
This pre-check script reports on the following potential concerns:
- Retention period of AHR, frequency of Snapshots, AWR Baselines, and similar.
- Age of CBO Statistics on the main table behind DBA_HIST_ACTIVE_SESS_HISTORY (WRH$_ACTIVE_SESSION_HISTORY) and its partitions.
- State of CBO Statistics for WRH$_ACTIVE_SESSION_HISTORY segments: Are the statistics Locked? Are they Stale?
- Size of WRH$_ACTIVE_SESSION_HISTORY segments, with range of Snapshots per segment (partition). Are they outside the desired retention window?
- Creation date and last DDL date for WRH$_ACTIVE_SESSION_HISTORY segments. So expected partition splitting can be verified.
Take for example result below. It shows that current ASH repository contains 320.6 days of history, even when in this case only 30 were requested (displayed on an upper part of report not shown here). We also see ASH is 16.4 GBs in size, where normally 1-2 GBs are plenty. We can conclude last partition split (or simply last DDL) is 289.7 days old, where normally only a few days-old are expected. This pre-check sample results on a ballpark estimate of 127 hours to execute eDB360. In other words, if we had one month of history (as current AWR configuration requests) instead of 320.6 days of history, then ASH repository would be less than 10% its current size and eDB360 would be estimated to execute in about 13 hours instead of 127. Keep in mind this “pre-check” provides a ballpark estimate, so an actual execution of eDB360 would take more or less the estimated time.
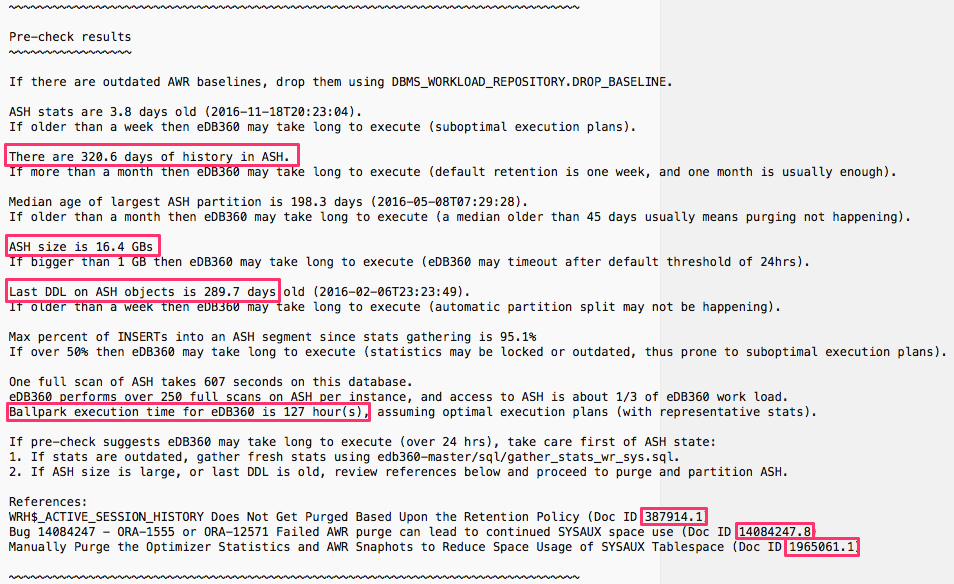
What to do if eDB36o is estimated to run for several days like in sample above? What I recommend is to fix ASH first. This process requires to read and digest at least 3 My Oracle Support (MOS) notes below, but it is not as bad as it sounds. You want to follow this path anyways, so any diagnostics tool that relies on ASH from AWR would benefit of the much needed cleanup.
- WRH$_ACTIVE_SESSION_HISTORY Does Not Get Purged Based Upon the Retention Policy (Doc ID 387914.1)
- Bug 14084247 – ORA-1555 or ORA-12571 Failed AWR purge can lead to continued SYSAUX space use (Doc ID 14084247.8)
- Manually Purge the Optimizer Statistics and AWR Snaphots to Reduce Space Usage of SYSAUX Tablespace (Doc ID 1965061.1)
Diagnosing eDB360 taking long
Let’s say you executed an older version of eDB360 and it took long (newer versions starting on v1620 perform an automatic pre-check, and if execution is estimated to last more than 8 hours, then it pauses and ask for confirmation before executing). If you executed an older version of eDB360, or simply your execution took longer than expected, review next the following files included on the directory from where you executed eDB360 (edb360-master), or stored within the edb360_*.zip file generated by eDB360 as it executed.
- awr_ash_pre_check_<database_name>.txt
- verify_stats_wr_sys_<database_name>.txt
- 00002_edb360_<NNNNNN>_log.txt
- 00003_edb360_<NNNNNN>_log2.txt
- 00004_edb360_<NNNNNN>_log3.txt
- 00005_edb360_157536_tkprof_sort.txt
If you find one of the SQL statements from eDB360 is taking more than a few minutes to execute, suspect first outdated CBO statistics on the Data Dictionary objects behind such query. Or if volume of data accessed by such query from eDB360 is large, suspect AWR data not getting purged. In either case take action accordingly.
If you cannot make sense of the information provided by these diagnostics files above, then contact eDB360 author at carlos.sierra.usa@gmail.com.
Keep in mind that execution time for eDB360 really depends on the state of several metrics stored in AWR, where ASH is the most relevant piece but not the only one. Think outdated statistics and outdated metrics!
