Posts Tagged ‘SQLTXPLAIN’
Has my Plan changed or not?
We have learned from Kerry Osborne’s recent post on SQL Gone Bad – But Plan Not Changed?, and a prior post from Randolf Geist on PLAN_HASH_VALUE – How equal (and stable?) are your execution plans – part 1, that having the same Plan Hash Value (PHV) it is not guarantee that we actually have the same Execution Plan if you were to consider Access and Filter Predicates for Plan Operations. So, what does it mean? It means that if you have inconsistent performance out of the same Execution Plan (same PHV) it is not enough to just check if you have or not the same PHV. You need to be aware of the Predicates as well. Of course there are other possible explanations for having inconsistent performance out of the same PHV, like skewed data combined with the use of binds, but that is another story.
Same Plan but different PHV
The opposite to “Same PHV but different Plan” is also possible. So, after we understood we can have the same PHV but not quite the same Plan if we include in the compare the Predicates, the question became: Can we also have cases having the same Plan (including Predicates) but get a different PHV? And the answer is YES.
Discard the keyword STORAGE, which we can consider not strong enough to determine a Plan Operation is different. Of course this is questionable, but as of today the PHV is blind to the STORAGE keyword, so a Plan with or without this keyword would render the same PHV.
What about system-generated names like ‘SYS_TEMP%’, ‘index$_join$_%’ and ‘VW_ST%’? In all these 3 cases the PHV will be different but the Plan is actually the same, with the exception of the system-generated names. So, if you just look at the PHV and see that is different then it is also possible that actually you have the same Plan.
What if in the case of having the same index name, the set of columns or their order is different? In these cases you may look at the PHV and see the same value, and indeed it is the same Plan, but if the columns on a referenced index have changed, is it really the same Plan? In my opinion it is not! You could be spinning on an issue where you have same Plan, different Performance, but an Index changed its columns.
SQLT to the rescue
Since we have the two cases: “Same PHV but different Plan” and “Same Plan but different PHV”, reviewing and ruling out these two possible cases on a complex Execution Plan can be cumbersome and time consuming. That is WHY SQLT incorporated the concept of SQLT Plan Hash Value (SQLT_PHV) since version 11.4.0.5 (from May 20, 2010). First came SQLT_PHV1, then SQLT_PHV2 (on SQLT 11.4.2.4 on February 18, 2011). So we have now PHV, SQLT_PHV1 and SQLT_PHV2, as you can see below.

As you can see in Table foot note: SQLT_PHV1 considers id, parent_id, operation, options, index_columns and object_name. SQLT PHV2 includes also access and filter predicates. So when comparing Plans the values of PHV, SQLT_PHV1 and SQLT_PHV2 can give you a better idea if your Plan is actually the same or not. SQLT COMPARE also uses the 3 values to determine if your Plan is the same or not, and in cases like the PHV is the same but a Predicate on a Plan Operation is different, it highlights in red the specific Plan Operation that has a different Predicate. Pretty cool right? I guess I will have to blog about SQLT COMPARE some time soon then…
Oh, be also aware that AWR does not store Plan Predicates, so if your Plan only exists on AWR you may be blind to these Predicates, but if the EXPLAIN PLAN FOR renders the same Plan as seen in lines 4 and 5 above, then you can see the predicates for 657302870 out the “XPL” Plan instead of “AWR”. A little trick that becomes handy…
Conclusion
When it comes to Execution Plans and their Plan Hash Value, it is possible that two Plans with same PHV are actually different if you consider the Predicates, and also possible you get a different PHV even if the Plan is the same if your Plan has system-generated names. So, during your analysis just looking at the PHV to determine if two Plans are the same or not is not enough. If you are already using SQLT, pay attention to the “Execution Plans” section, and to the SQLT PHV1 and PHV2 columns.
Oracle Queries are taking different Plans
I recently saw a post with this title “Oracle Queries are taking different Plans” and since there was a lot of guessing I suggested to use SQLTXPLAIN and find there the root cause. For some reason or another the thread is still open after 20 days, and the guessing continues. Since the problem of “finding the root cause of a change on an execution plan” is old and still common, I decided to talk about it here.
In Oracle, execution plans do change for one SQL over time, that is a fundamental function of the Cost-based Optimizer (CBO). Not only is normal, but expected and desired in most circumstances. What is not desired, is when a SQL that had a good performing plan suddenly changes its plan to one that we consider sub-optimal in terms of performance. This should be the concern and focus. So WHY the CBO suddenly generates such a plan? The possible reasons are many but I enlist here the most common ones I can think of:
- Schema object statistics changes
- Small sample sizes when gathering CBO schema statistics (mostly on 10g)
- Lack of statistics in some columns referenced by predicates
- Inconsistent values of bind variables referenced by SQL
- System wide changes like CBO parameters or system statistics
- Index modifications including new and dropped indexes
- Invalid or invisible indexes
- Large SQL text with many predicates where several plans with similar cost are possible
- Inconsistent ramp-up process of Adaptive Cursor Sharing (ACS)
- SQL Profiles generated by the SQL Tuning Advisor (STA)
- An index changing its blevel (for example from blevel 2 to 3)
- Volatile values in some columns (for example value “Pending” exists in table column for a short time)
- Asynchronous gathering of stats on volatile data instead of gathering right between load and consumption
The list above is not comprehensive. It only includes what came to my mind while writing it, so I may have forgotten several cases. And of course there are always some corner cases like special conditions activating uncommon heuristics, or simply hitting a CBO bug.
Guessing WHY a plan has changed is very time consuming and requires multiple queries to the metadata on the database. Since most of the metadata we are interested on is dynamic by nature, we base our guess work on an ever changing environment. Of course the root cause become elusive and we may give up for some time, or jump to false conclusions.
This is where SQLTXPLAIN (MOS 215187.1) or its younger and lighter sister SQLHC (MOS 1366133.1) come to the rescue. These free tools, specially SQLTXPLAIN (SQLT), capture the static and dynamic environment around the one SQL we want to analyze.
By having a consistent view of all elements affecting the execution plan, it becomes much easier to find the root cause of a plan change. And since SQLT also includes current and past details about parameters, statistics and bind variable values, we can even correlate those values to prior execution plans. So I encourage you to try SQLTXPLAIN on a SQL next time you are confronted by the old question: “WHY Oracle Queries are taking different Plans?”.
I am aware SQLTXPLAIN is intimidating. Its output is exuberant, but the point is that it includes what we need to find the root cause of most if not all SQL Tuning cases where a plan has changed.
I have presented this SQLT tool in several conferences during the past year or so. I think it is appropriate now to put together a 3 days workshop to master this tool… Just an idea at this time.
How to diagnose a SQLTXPLAIN installation failure
SQLTXPLAIN is easy to install. Yes, unless you hit a rock! So, if you are trying to install SQLT and you do not see the message that reads “SQCREATE completed. Installation completed successfully.” then something went bad. First, you have to identify if the reason was captured by SQLT or not. In other words, if it was captured by SQLT you will see in your screen that your session ended normally. If it was not trapped by SQLT you will see an error like ORA-07445 or ORA-03113 and a statement that says something like “end-of-file on communication channel”. In such case SQLT could not trap the error.
Session ends normally
If you do not see an “end-of-file on communication channel” and your session were you were installing SQLT seems to have exited normally (but without displaying “SQCREATE completed. Installation completed successfully.”) , then look at your current SQL*Plus directory (“HOS ls” OR “HOS dir”)and look for a log file “YYMMDDHH24MISS_NN_%.log”. This file should contain your error. In some cases you have to look also at the most recent file(s) inside the SQLT archive SQLT_installation_logs_archive.zip which is generated into same local directory. Typical cases of an error of this type are:
- Invalid Tablespace name was indicated
- Tablespace running out of space
- A SYS owned package is missing or its execute grants are missing: DBMS_METADATA and UTL_FILE are the most common ones
- UTL_FILE_DIR has a value but it does not include the path for traces (USER_DUMP_DEST)
In any case, once you locate the error it is just a matter of taking a corrective action and re-installing SQLT. But if you see a package body has errors but the error is not displayed in any of the log file (specially on the one with name like 130515065531_08_sqcpkg.log) then you may need to do this: unlock and reset pwd for SQLTXADMIN then try an alter package compile connected as SQLTXADMIN. Once you see the error then you can fix it.
Session disconnects abnormally
This kind of problem is a bit more complicated. If you see an ORA-07445 or ORA-03113 or “end-of-file on communication channel” then it means SQLT could not trap the error and you have to look for it inside the alert log. It also means that your problem is not derived from SQLT, but SQLT is simply a victim of it. You may find more information in your alert log, and you will see references to some traces. Look for those traces and review the upper part of those files. They should show a stack of calls and some keywords associated to your error. You can either research for those keywords on your own, or report to Oracle the errors you see in the alert log. Again, at this point the problem is not SQLT but something else in your server code that happens to affect SQLT. Since the skills to diagnose a server problem are not the same as those needed to diagnose a SQLT installation issue, be sure to document clearly what is the problem you see. This type of disconnect is a server problem, the former is a SQLT problem.
I do not have a typical list for this type since possibilities are many. You may find an ORA-00600 or something else. What I have seen recently are problems around the use of NATIVE for plsql_code_type. This change was introduced a few SQLT versions back and some customers have reported installation issues. If you see on your errors something that suggests PLSQL, then you may want to modify line 29 of the sqlt/install/sqcommon1.sql script, removing the “–” at the beginning of this line: DEF plsql_code_type = ‘INTERPRETED’;. In other words, un-comment this command. Then re-install SQLT. This action would reverse the use of plsql_code_type to less efficient INTERPRETED mode, but may workaround your plsql error.
Last resource
If you have don’t your best effort to locate the error and to fix the root cause, but nothing seems to work, then you have two more options:
- If SQLT was requested by someone else, please contact that requester (it could be Oracle Support or a business partner) and report the issue. This person may be able to help you directly; OR
- If you are the requester mentioned above, or there is no one else to go, then look in the sqlt/sqlt_instructions.html file for the primary and secondary contacts for this tool (documented starting on version 11.4.5.9 of the tool).
SQLT installs with no issues most of the times, but if it fails to install in a particular system, you are not on your own. Do your best to find the root cause, then ask for help if needed. Be prepared to provide any log file created in your local SQL*Plus directory PLUS the SQLT archived logs; and in cases of disconnects collect also the alert log and the traces referenced directly by the corresponding error on the alert.
Great Lakes Oracle User Group 2013 Conference
I delivered my two sessions at the Great Lakes Oracle Users Group today. It was a great experience! I had the honor to fill to capacity both sessions, and both were scheduled in the largest room out of 5 concurrent tracks! I estimate that in each session I had more than 50% of the total audience. It is very rewarding been able to share some knowledge with such a great crowd. I was asked if I would do a half -day pre-conference workshop next year. I would certainly do if I can.
Anyways, with the conference behind, I am sharing here both presentations. For the one in Adaptive Cursor Sharing, if you want to perform the labs we did today, please post your request here and I will find a way to share those demo scripts.
- SQL Tuning made much easier with SQLTXPLAIN (SQLT)
- Using Adaptive Cursor Sharing (ACS) to produce multiple Optimal Plans
Scripts are now uploaded into acs_demo. Download this “doc” file and change its type to “zip” before opening it.
Migrating an Execution Plan using SQL Plan Management
SQL Plan Management (SPM) has been available since the first release of 11g. As you know SPM is the new technology that provides Plan Stability with some extra Plan Control and Management features. Maria Colgan has done an excellent job documented the “SPM functionality” pretty well in 4 of her popular blog postings:
- Creating SQL plan baselines
- SPM Aware Optimizer
- Evolving SQL Plan Baselines
- User Interfaces and Other Features
A question that I often get is: How do I move this good plan from system A into system B? To me, this translates into: How do I migrate an Execution Plan? And if source and target systems are 11g, the answer is: Use SQL Plan Management (SPM).
Migrating a Plan using SPM
Assuming both – source and target systems are on 11g then I suggest one of the two approaches below. If the source is 10g and target is 11g, then the 2nd approach below would work. In both cases the objective is to create a SQL Plan Baseline (SPB) into the target system out of a known plan from the source system.
Option 1: Create SPB on source then migrate SPB into target
Steps:
- Create SQL Plan Baseline (SPB) in Source
- From Memory; or
- From AWR (requires Diagnostics Pack license)
- Package & Export SPB from Source
- Import & Restore SPB into Target
Pros: Simple
Cons: Generates a SPB in Source system
Option 2: Create SQL Tuning Set (STS) on source, migrate STS into target, promote STS into SPB in target
Steps:
- Create SQL Tuning Set (STS) in Source (requires Tuning Pack license)
- From Memory; or
- From AWR (requires Diagnostics Pack license)
- Package & Export STS from Source
- Import & Restore STS into Target
- Create SPB from STS in Target
Pros: No SPB is created in Source system
Cons: Requires license for SQL Tuning Pack
How SQLTXPLAIN (SQLT) can help?
SQLT has been generating for quite some time a STS for each Plan Hash Value (PHV) of the SQL being analyzed. This STS for each PHV created on the source system is also stored inside the SQLT repository and included in the export of this SQLT repository. By doing this every time, options 1 and 2 above are simplified. If we want to promote a Plan into a SPB in source system we only have to execute an API that takes the Plan from the STS and creates the SPB. The dynamic readme included with SQLT has the exact command. And if we want to create a SPB on a target system having a SQLT from a source system, we have to restore the SQLT repository into the target system, then restore the STS out of the SQLT repository, and last create the SPB out of the STS. All these steps are clearly documented in the SQLT dynamic readme, including exact commands. There is one caveat although: you need SQLT in source and restore its repository in target…
Stand-alone scripts to Migrate a Plan using SPM
Options 1 and 2 above list the steps to take a plan from a source system and implement with it a SPB into a target system. The questions is: How exactly do I perform each of the steps? Yes, there are APIs for each step, but some are a bit difficult to use. That is WHY I have created a set of scripts that pretty much facilitate each of the steps. No magic here, only some time savings. If you want to use these scripts, look for SQLT directory sqlt/utl/spm, which will be available with SQLT 11.4.5.8 on May 10, 2013. If you need these scripts before May 10, then please send me an email or post a comment here.
WHY SQLT XTRACT produces two EVENT 10053 traces?
If you use SQLT XTRACT often, you may have noticed that in some cases the sqlt_sNNNNN_*.zip file contains two 10053 traces instead of one. The question is WHY?
Take for example this:
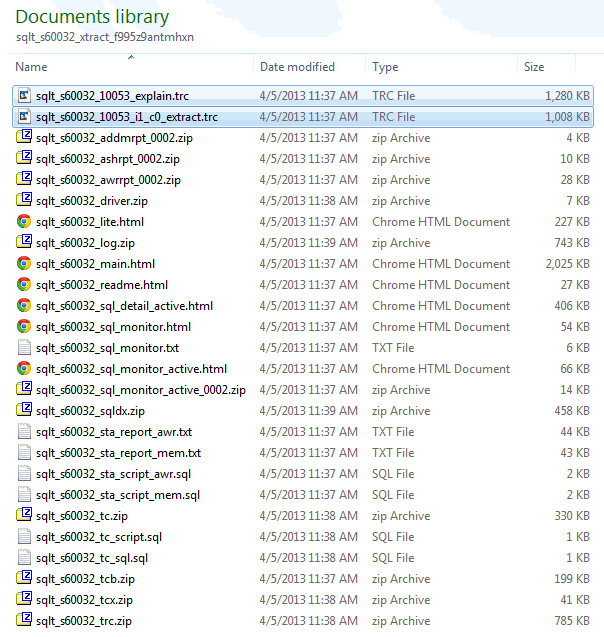
The first file reads “explain” and it is generated by enabling EVENT 10053 during an EXPLAIN PLAN FOR command on the SQL Text associated to the SQL_ID passed to SQLT XTRACT. So this 10053 may not be accurate if the SQL has binds and bind peeking is enabled.
The second file reads “i1_c0_extract’. The “i1” part means instance 1 and the “c0” means child cursor zero. This 10053 is generated by API SYS.DBMS_SQLDIAG.DUMP_TRACE which is available on 11.2 and higher.
When I see both files I usually focus on the one from the new API, since the “explain” may show a different plan than the one actually executed. In any case, look first at the Plans Summary section of SQLT main report and pay attention to the plan hash values. Then on your 10053 search for Plan Table and compare the hash value with the one from SQLT main report.
All session of “SQL Tuning Workshop I” are now full
Regarding internal “SQL Tuning Workshop I” 3 new sessions (Orlando, Toronto and Colorado Springs): All 3 sessions are now full.
SQL Tuning Workshop I (updated schedule of sessions)
I opened 3 sessions of the internal SQL Tuning Workshop I.
- June 11-14, Orlando, FL
- July 9-13, Toronto, Canada
- July 30-August 3, Colorado Springs, CO
This intermediate to advanced class includes these topics:
- Explaining the Explain Plan
- Statistics Foundations
- CBO Fundamentals I
- Statistics Best Practices
- CBO Fundamentals II
- Extended Statistics
- Dynamic Sampling
- Event 10053 Tracing the CBO
- Event 10046 Tracing the Execution
- SQLT Foundations
- SQLT Intermediate
- Real-life Case Studies
I still have some seats available for Orlando and Colorado Springs. For registration please follow instructions on internal link.
SQLTXPLAIN (SQLT) 11.4.4.5 is now available
SQLT XTRSBY new method
If you have a poorly-performing SQL statement on a read-only standby Data Guard database, now you can analyze it with SQLT. Just need to install SQLT on Primary, create a database link into the read-only and use new method SQLT XTRSBY passing SQL_ID and db link name. Read sqlt/sqlt_instructions.html for more details.
In addition, there are two stand-alone scripts (with no SQLT dependencies) that you can use directly on any read-only database. They are sqlt/utl/roxtract.sql and sqlt/utl/roxecute.sql. They mimic SQLT XTRACT and XECUTE but in a smaller scale. Notice that you can also use these two stand-alone scripts safely on any production environment since they do not execute any DDL and they perform queries only (no inserts, updates or deletes). What do you get from them? You get the basics: execution plans; peeked binds; CBO statistics for Tables, Table Columns, Indexes and Index Columns; SQL Monitor Active report; 10053 trace; 10046 trace and TKPROF on roxecute.sql.
If using SQLT XTRSBY on a Data Guard Primary database, you may also want to use roxtract.sql on the read-only standby database. Combined you will get more about your SQL. XTRSBY focuses on GV$* from standby plus DBA* from Primary. Script roxtract.sql only looks at standby.
As always, download latest version of SQLT from MOS 215187.1.
SQLT 11.4.4.5 changes:
Fixes:
- Removed annoying message on main “sqlt$a: *** t:plan_operation%: ORA-01403: no data found”.
- Test Case (TC) script q.sql now takes values of NULL on binds instead of continue searching for not NULL values. It also handles string “NULL” as NULL on dba_hist_sqlbind.
Enhancements:
- SQLT is now Data Guard aware. There is a new method SQLT XTRSBY which is executed on Primary and extracts from stand-by almost everything XTRACT does. Please refer to instructions before using this new method.
- In addition to new SQLT XTRSBY which runs in Data Guard Primary, there are two new scripts sqlt/utl/roxtract.sql and sqlt/utl/roxecute.sql which are super lite versions of SQLT XTRACT and XECUTE. The new read-only (RO) scripts can be used on any read-only database since they do not install anything and do not update anything. They provide a quick and safe view of the environment around one SQL statement.
- New instrumentation on SQLT XTRACT, XECUTE, XTRXEC, XTRSBY and XPLAIN. All these methods produce now a TKPROF for the actual execution of the tool. The new TKPROF is located in the log zip file. It helps to diagnose SQLT taking longer than expected.
- Skip MDSYS objects from metadata script. Since MDSYS is part of the data dictionary, it makes sense to skip it from Metadata as we do with similar schemas.
- Column remap on SQLT TC now considers map by QUALIFIED_COL_NAME when name is other than SYS%. This helps to match more columns when we are restoring CBO schema statistics while remapping to new TC user.
- Metadata includes now PL/SQL library which executed the SQL being analyzed. This is useful to actually see the piece of program that invoked the SQL being analyzed.
Free Webinar: Using SQLTXPLAIN to diagnose SQL statements performing poorly
SQLTXPLAIN (SQLT) is a free tool to diagnose SQL statements performing poorly. If you have used it you know its installation and use is simple (understanding the output may still be overwhelming). But if you have never used it, you may feel intimidated by this tool. I will be doing a 1hr Webinar in how to install SQLT and how to use its main methods: XTRACT, XECUTE, XTRXEC, XTRSBY and XPLAIN. I will allocate 45 minutes for presentation and demo, followed by 15 minutes for a Q&A session. This Webinar is free but its capacity is limited, so if you want to attend please register early. It will be on May 15 at 11am (UTC-05:00) Eastern Time (US & Canada).
