Archive for the ‘SQLTXPLAIN (SQLT)’ Category
Non-intrusive SQL Trace instrumentation on legacy PL/SQL code
Problem
Legacy PL/SQL code with intermittent performance degradation.
To improve the performance of this code, the first step is to diagnose it. But this code has no instrumentation whatsoever, it is in Production, and rolling any code into Production usually requires rigorous testing. So, whatever method we implement has to be light-weight and as safe as possible.
Using Oradebug is not a viable solution mainly for two reasons: It misses the “head” of the transaction, so we may not get to know the SQL taking longer; and second, internal procedures from finding about the issue, reporting it, then acting on it may take from several minutes to hours.
Solution
- Identify which PL/SQL libraries are known to be problematic in terms of intermittent performance degradation.
- At the beginning of each callable PL/SQL Procedure or Function, add a call to DBMS_APPLICATION_INFO.SET_MODULE to set some appropriate MODULE and ACTION, for example “R252, LOAD”. Call this API also at the end, to NULL out these two parameters. This code change is very small and safe. It introduces practically no overhead. It simply labels every SQL executed by the PL/SQL library with some MODULE and ACTION that uniquely identify the code of concern.
- Activate SQL Trace on the module/action that needs to be traced, by calling DBMS_MONITOR.SERV_MOD_ACT_TRACE_ENABLE, passing parameters SERVICE, MODULE and ACTION. With this API request a SQL Trace to be generated with WAITs and BINDs (binds are optional but desirable). Once these traces are no longer needed (reviewed by someone), turn SQL Trace off using API DBMS_MONITOR.SERV_MOD_ACT_TRACE_DISABLE.
- Once the SQL Trace is produced, generate a TKPROF on it. You may want to include parameter “sort=exeela fchela”. This way you get the slower SQL at the top of the TKPROF report.
- With SQL Trace and TKPROF, identify the slower SQL and use SQL Monitor and/or SQL XTRACT to get more granular diagnostics (you need to identify SQL_ID). On any given PL/SQL library, it is common that 1~5 SQL statements consume > 80% of the Elapsed Time. Focus on these large consumers.
Conclusion
Producing a SQL Trace with EVENT 10046 level 8 or 12 is very useful to properly diagnose the code on a PL/SQL library which performs poorly. A follow-up on the slower SQL with SQL Monitor and/or SQLT XTRACT is in order. The method presented above is very easy and safe to implement.
Counting rows fast
A friend of mine asked me last night basically this: “How is that SQLTXPLAIN counts rows?”. In particular, he was referring to the use of the SAMPLE clause of the SELECT statement. Look at this SQLT’s log piece:
SQL_ID a9x1kc4ymyhkz -------------------- SELECT /*+ FULL(t) PARALLEL */ COUNT(*) * 1e4 FROM "XYPZ"."INSTRUMENT" SAMPLE (.01) t SQL_ID 025v6k1032t69 -------------------- SELECT /*+ FULL(t) PARALLEL */ COUNT(*) * 1e5 FROM "XYPZ"."POSITION_COMPOSITION" SAMPLE (.001) t SQL_ID 8rby3340xpd9k -------------------- SELECT /*+ FULL(t) PARALLEL */ COUNT(*) * 1e5 FROM "XYPZ"."POSITION_EVENT" SAMPLE (.001) t
WHY is it that SQLT has to count rows?
SQLT has to count rows so it can report side by side DBA_TABLES.NUM_ROWS and COUNT(*) from each Table. This is an easy way to see if your statistics are way off, and this mechanism exists on SQLT well before DBA_TAB_MODIFICATIONS came to existence. Actually, SQLT uses both methods to health-check how stale are your Table statistics.
The conundrum here is: “I use SQLT because I want to diagnose a performance issue on a QUERY on top of large Tables, but I do not want SQLT to take a long time just to produce a COUNT(*) of my Tables…”.
Fast versus Precise
In Performance tuning, there is always a trade-off. You want X but you sacrifice B. Counting rows is no different. Do you want it faster? Then you sacrifice precision. The SAMPLE clause of the SELECT statement allows you to do exactly that (syntax below):
SAMPLE [ BLOCK ] ( sample_percent ) [ SEED ( seed_value ) ]
So, if you specify a 10% sample size then you have to multiply the COUNT(*) by 10. If you sample 1% you multiply the COUNT(*) by 100. In large Tables if you sample, lets say 0.1%, your multiplier becomes 1,000, which is the same than 1e3 (10**3 or 10^3 depending where you went to school). Sample size can be as small as 0.000,001 and as large as 100 (but without including 100 itself). It represents probabilities more than an actual sample size.
The optional BLOCK clause simple says: use sample blocks instead of rows. And the optional SEED clause tries to provide some consistency in the result of the count when you use the same value for two executions of the exact same count. This SEED clause takes a value between 0 and 4,294,967,295.
How SQLT counts rows?
SQLT has over 40 tool parameters. One of them is count_star_threshold with a seeded value of 10,000.
SQLT includes a small algorithm (below) that determines the size of the SAMPLE according to the estimated size of the Table itself, by looking at its statistics as per DBA_TABLES.NUM_ROWS. No statistics? then skip the sample and do a normal full scan. If the Table is expected to be smaller then the count_star_threshold, then do a full scan. So is up to 10x this threshold. After that, use a sample size proportionally inverse to the Table size. The bigger the Table the smaller the Sample.
SQLT also forces a full Table scan and invokes Parallel Execution (PX) as a method to expedite the count. This count can be really fast on Exadata systems as you can imagine.
/* -------------------------
*
* private perform_count_star
*
* called by: sqlt$i.common_calls and sqlt$i.remote_xtract
*
* ------------------------- */
PROCEDURE perform_count_star (p_statement_id IN NUMBER)
IS
l_sql VARCHAR2(32767);
l_number NUMBER;
l_count NUMBER;
BEGIN
write_log('=> perform_count_star');
IF sqlt$a.get_param_n('count_star_threshold') = 0 THEN
write_log('skip "count_star" as per corresponding parameter');
ELSE
FOR i IN (SELECT owner, table_name, num_rows, source
FROM &&tool_administer_schema..sqlt$_dba_all_tables_v
WHERE statement_id = p_statement_id
ORDER BY
owner, table_name)
LOOP
IF i.num_rows IS NULL THEN
l_sql := 'SELECT /*+ FULL(t) PARALLEL */ COUNT(*)
FROM "'||i.owner||'"."'||i.table_name||'" t WHERE ROWNUM <= :number';
l_number := sqlt$a.get_param_n('count_star_threshold');
ELSIF i.num_rows < sqlt$a.get_param_n('count_star_threshold') THEN
l_sql := 'SELECT /*+ FULL(t) PARALLEL */ COUNT(*)
FROM "'||i.owner||'"."'||i.table_name||'" t WHERE ROWNUM <= :number';
l_number := sqlt$a.get_param_n('count_star_threshold') * 10;
ELSIF i.num_rows < (sqlt$a.get_param_n('count_star_threshold') * 1e1) THEN
l_sql := 'SELECT /*+ FULL(t) PARALLEL */ COUNT(*) * 1e1
FROM "'||i.owner||'"."'||i.table_name||'" SAMPLE (:number) t';
l_number := 1e1;
ELSIF i.num_rows < (sqlt$a.get_param_n('count_star_threshold') * 1e2) THEN
l_sql := 'SELECT /*+ FULL(t) PARALLEL */ COUNT(*) * 1e2
FROM "'||i.owner||'"."'||i.table_name||'" SAMPLE (:number) t';
l_number := 1e0;
ELSIF i.num_rows < (sqlt$a.get_param_n('count_star_threshold') * 1e3) THEN
l_sql := 'SELECT /*+ FULL(t) PARALLEL */ COUNT(*) * 1e3
FROM "'||i.owner||'"."'||i.table_name||'" SAMPLE (:number) t';
l_number := 1/1e1;
ELSIF i.num_rows < (sqlt$a.get_param_n('count_star_threshold') * 1e4) THEN
l_sql := 'SELECT /*+ FULL(t) PARALLEL */ COUNT(*) * 1e4
FROM "'||i.owner||'"."'||i.table_name||'" SAMPLE (:number) t';
l_number := 1/1e2;
ELSIF i.num_rows < (sqlt$a.get_param_n('count_star_threshold') * 1e5) THEN
l_sql := 'SELECT /*+ FULL(t) PARALLEL */ COUNT(*) * 1e5
FROM "'||i.owner||'"."'||i.table_name||'" SAMPLE (:number) t';
l_number := 1/1e3;
ELSIF i.num_rows < (sqlt$a.get_param_n('count_star_threshold') * 1e6) THEN
l_sql := 'SELECT /*+ FULL(t) PARALLEL */ COUNT(*) * 1e6
FROM "'||i.owner||'"."'||i.table_name||'" SAMPLE (:number) t';
l_number := 1/1e4;
ELSIF i.num_rows < (sqlt$a.get_param_n('count_star_threshold') * 1e7) THEN
l_sql := 'SELECT /*+ FULL(t) PARALLEL */ COUNT(*) * 1e7
FROM "'||i.owner||'"."'||i.table_name||'" SAMPLE (:number) t';
l_number := 1/1e5;
ELSE
l_sql := 'SELECT /*+ FULL(t) PARALLEL */ COUNT(*) * 1e8
FROM "'||i.owner||'"."'||i.table_name||'" SAMPLE (:number) t';
l_number := 1/1e6;
END IF;
l_sql := REPLACE(l_sql, ':number', l_number);
write_log('num_rows='||i.num_rows||' sql='||l_sql);
l_count := NULL;
BEGIN
EXECUTE IMMEDIATE l_sql INTO l_count;
write_log(l_count||' rows counted');
EXCEPTION
WHEN OTHERS THEN
write_log('** '||SQLERRM);
write_log(l_sql||' failed with error above. Process continues.');
END;
IF l_count IS NOT NULL THEN
IF i.source = 'DBA_TABLES' THEN
UPDATE &&tool_repository_schema..sqlt$_dba_tables
SET count_star = l_count
WHERE statement_id = p_statement_id
AND owner = i.owner
AND table_name = i.table_name;
ELSIF i.source = 'DBA_OBJECT_TABLES' THEN
UPDATE &&tool_repository_schema..sqlt$_dba_object_tables
SET count_star = l_count
WHERE statement_id = p_statement_id
AND owner = i.owner
AND table_name = i.table_name;
END IF;
END IF;
END LOOP;
COMMIT;
END IF;
write_log('<= perform_count_star');
END perform_count_star;
Conclusion
Counting rows is like counting beans, you can count one at a time, or you can take some shortcuts. If you are willing to sacrifice some precision for the sake of gaining performance, consider then using the SAMPLE clause of the SELECT statement.
Carlos Sierra’s shared Scripts and Presentations
I recently delivered 3 sessions at the East Coast Oracle Users Group (ECO). During these sessions I offered to share the actual Presentations and some of the Scripts I used during the 3rd session. I plan to keep updating and expanding both scripts and presentations. They also show now on the right side of this page. Feel free to use, share and recycle any of my scripts and presentations.
Speaking about SQLT XPLORE – The SQLT hidden child
Next week I will be participating at the East Coast Oracle Users Group ECO. If you are not familiar with this Oracle Users Group you may want to check it out. It gathers close to 300 Oracle users, and every year it gets bigger and better. The environment is friendly, and I would say even cozy. There are 6 simultaneous tracks packed into 2 full days. Sometimes it is hard to decide which session to attend, but fortunately the diversity of topics usually reduces the choice to one or two (unless you are like me, and want to learn, and learn, and learn…)
Anyways, the schedule is here so you can check what is all about. If you decide to attend this year (next week), you can still register today and get a small discount using code SPEAKERVIP.
I will be speaking about two topics. One is about Adaptive Cursor Sharing, while the second is about SQLT XPLORE, which I call “the SQLT hidden child“. SQLT XPLORE is a stand-alone module inside SQLTXPLAIN (SQLT), but it does not require SQLT to be installed. This SQLT XPLORE uses brute force analysis in order to “discover” Execution Plans that may be elusive. Typical case is when you upgrade your database and your Execution Plan changed.
Stelios Charalambides writes about SQLT XPLORE in his book “Oracle SQL Tuning with Oracle SQLTXPLAIN“. In my session at ECO I will show some XPLORE samples, and will explain how to read its output. I am planing to do a live demo about executing this tool. And of course, all questions are welcomed!
I hope to see some familiar faces next week at ECO, and also to meet some new Oracle users and other speakers. Looking forward to speak at ECO next week!
YASTS: Yet Another SQL Tuning Script: planx.sql
Having SQLTXPLAIN and SQLHC available, WHY do I need yet another way to display execution plans?
New script planx.sql reports execution plans for one SQL_ID from RAC and AWR. It is lightweight and installs nothing. It produces list of performance metrics for given SQL out of gv$sqlstats, gv$sqlstats_plan_hash, gv$sql and dba_hist_sqlstat. It also displays execution plans from gv$sql_plan_statistics_all and dba_hist_sql_plan. It is RAC aware. It also reports on io_saved when executed on Exadata.
Most stand-alone light-weight scripts I have seen only report plans from connected RAC node. This script reports from all RAC nodes. The AWR piece is optional. In other words, if your site does not have a Diagnostics Pack License you can specify so when executing this script, thus all access to AWR data is simply skipped. Output is plain text and it executes in seconds.
I will be using this planx.sql as my first step in the analysis of queries performing slowly. If I need more, then I will use SQLHC or SQLTXPLAIN. This planx.sql script, as well as some others, are beginning to populate my new shared directory of “free” scripts. The link is at the right of the screen, and also here. Quite often I write small scripts to do my job, now they will have a new house there. A readme provides a one-line description of each script.
Conclusion
New planx.sql is an alternative to plain DBMS_XPLAIN.DISPLAY_CURSOR. It displays plans from all RAC nodes and from AWR(opt). It also reports relevant performance metrics for all recorded execution plans. It is fast and installs nothing.
SQL Tuning with SQLTXPLAIN 2-days Workshop
SQLTXPLAIN is a SQL Tuning tool widely used by the Oracle community. Available through My Oracle Support (MOS) under document 215187.1, this free tool is available for download and use to anyone with MOS access. It has helped thousands of times to expedite the resolution of SQL Tuning issues, and many Oracle DBAs and Developers benefit of its use on a daily basis.
Stelios Charalambides has done an excellent job writing a book on this topic. In his book Stelios covers many aspects about SQLTXPLAIN and some related topics. I highly recommend to get a copy of this book if you want to learn more about SQLTXPLAIN. It is available at Amazon and many other retailers.
The new 2-days SQLTXPLAIN Workshop offered by Enkitec (an Oracle Platinum business partner and my employer) is a completely new course that interleaves “how to use effectively SQLTXPLAIN” with important and related SQL Tuning Topics such as Plan Flexibility and Plan Stability. This hands-on workshop offers participants the unique opportunity to fully understand the contents of SQLTXPLAIN and its vast output through an interactive session. About half the time is dedicated to short guided labs, while the other half uses presentations and demos. This workshop is packed with lots of content. It was a real challenge packaging so much info in only two days, but I am very pleased with the result. It became a 2-days intensive knowledge transfer hands-on workshop on SQLTXPLAIN and SQL Tuning!
The first session of this workshop is scheduled for November 7-8 in Dallas, Texas. I expect this pilot session to fill out fast. Other sessions and onsite ones will be offered during 2014. I hope to meet many of you face to face on November 7!
About SQLT Repository
SQLTXPLAIN maintains a repository of metadata associated to a SQL statement being analyzed. A subset of this SQLT repository is automatically exported every time one of the main methods (like XTRACT) is used. A question sometimes I get is: what do you do with this SQLT repository? Well, in most cases: nothing. That is because most of the diagnostics we need are already included in the main report. But in some very particular cases we may want to dig into the SQLT repository. For example, in a recent case I wanted to understand some patterns about a particular wait event that happen to become “slower” after the application of an Exadata patch. Then, when IO Resource Manager IORM was configured from Basic to Auto, these waits became “fast” again. How to measure that? How to observe any trends and correlated to the times when the patch was applied and then when the IORM was adjusted? Fortunately SQLT had been used, and it captured ASH data out of AWR before it aged out. So I was able to use it in order to get to “see” these trends below.
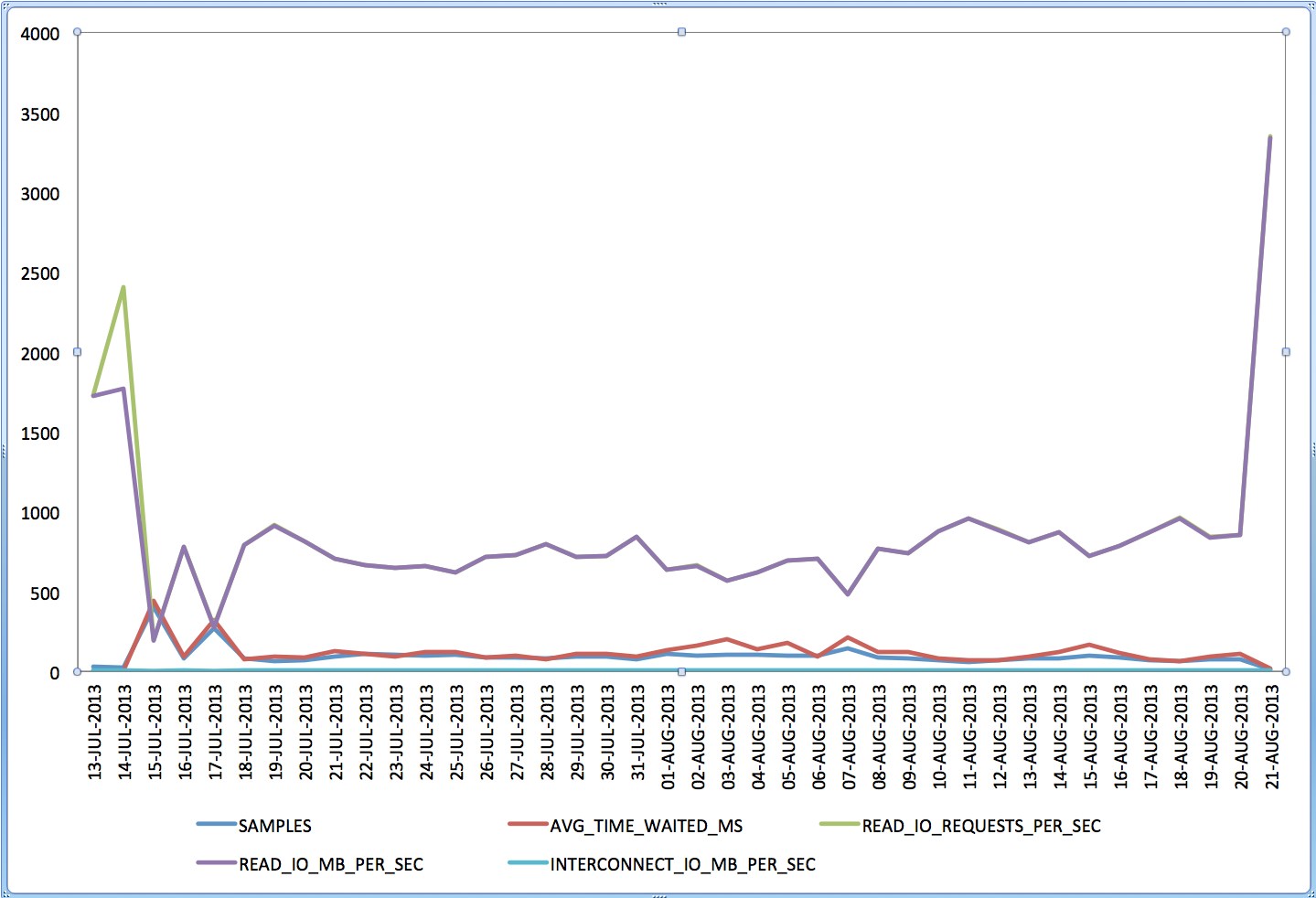
Now the question becomes: How do I produce this kind of graph? Well, with Excel it is easy, we just need to bring the piece of the SQLT repository that we want into Excel. For that, I first import the whole SQLT repository for a given sqlt_sNNNNN_*.zip file into my local SQLT repository. The command is spelled out in the sqlt_sNNNNN_readme.html as “import SQLT repository”, then I just use SQL Developer to export the output of a query into XLS (or CSV). In this case the SQL I used was the one below.
If you try to use the SQLT repository for some similar data analysis and you struggle with it, please let me know and I will help you out.
WITH awr_ash AS ( SELECT DISTINCT -- two or more statements can include same snaps sample_time, sql_plan_hash_value, sql_plan_line_id, wait_class, event, time_waited, ROUND(time_waited / 1e3) time_waited_ms, current_obj#, machine, delta_time, delta_read_io_requests, delta_write_io_requests, delta_read_io_bytes, delta_write_io_bytes, delta_interconnect_io_bytes, ROUND(delta_read_io_requests / (delta_time / 1e6)) read_io_requests_per_sec, ROUND(delta_write_io_requests / (delta_time / 1e6)) write_io_requests_per_sec, ROUND(delta_read_io_bytes / (delta_time / 1e6)) read_io_bytes_per_sec, ROUND(delta_write_io_bytes / (delta_time / 1e6)) write_io_bytes_per_sec, ROUND(delta_interconnect_io_bytes / (delta_time / 1e6)) interconnect_io_bytes_per_sec FROM sqlt$_dba_hist_active_sess_his WHERE statement_id IN (90959, 90960, 90962, 90963) AND session_state = 'WAITING' AND time_waited > 0 AND delta_time > 0 AND wait_class IS NOT NULL ), awr_ash_grp AS ( SELECT TRUNC(sample_time) sample_day, event, COUNT(*) samples, ROUND(AVG(time_waited_ms)) avg_time_waited_ms, ROUND(AVG(read_io_requests_per_sec)) read_io_requests_per_sec, ROUND(AVG(write_io_requests_per_sec)) write_io_requests_per_sec, ROUND(AVG(read_io_bytes_per_sec)) read_io_bytes_per_sec, ROUND(AVG(write_io_bytes_per_sec)) write_io_bytes_per_sec, ROUND(AVG(interconnect_io_bytes_per_sec)) interconnect_io_bytes_per_sec FROM awr_ash GROUP BY TRUNC(sample_time), event ), cell_smart_reads AS ( SELECT sample_day, TO_CHAR(sample_day, 'DD-MON-YYYY') sample_date, samples, avg_time_waited_ms, read_io_requests_per_sec, read_io_bytes_per_sec, ROUND(read_io_bytes_per_sec / (1024 * 1024)) read_io_mb_per_sec, interconnect_io_bytes_per_sec, ROUND(interconnect_io_bytes_per_sec / (1024 * 1024), 1) interconnect_io_mb_per_sec FROM awr_ash_grp WHERE event = 'cell smart table scan' ) SELECT sample_date, samples, avg_time_waited_ms, read_io_requests_per_sec, read_io_mb_per_sec, interconnect_io_mb_per_sec FROM cell_smart_reads ORDER BY sample_day;
SQLTXPLAIN 12.1.01 is now available
Mauro Pagano is doing a great job keeping SQLT well taken care! Version 12.1.01 is now available for download out of MOS (Metalink) doc_id 215187.1. With a monthly release, it is always a good idea to download the latest version at least every quarter. This latest version includes some adjustments for 12c and some other changes as seen below. Here is the list of changes for the past 3 months. The saga continues!
12.1.01 August 19, 2013
- BUG: Incorrect date wrapping in report “Non-Default or Modified Session Parameters”
- BUG: SQLHC Table Summary reporting section was skipping tables if they had no index defined on them
- BUG: The logic in “Newest Value” column in Modified System Parameters needed to be adjusted, the value was sometime incorrect
- BUG: CBO Environment section was reporting a parameter many times if that param had been changed more than once
- ENH: SQLT and SQLHC works on 12c!
- ENH: Improved SQLHC HC on corrupt histograms for 12c
- ENH: SQLT can now create user SQLTXADMIN in presence of password complexity verification function
- ENH: Stat table creation now supports Unicode charset in both SQLT TC and SQLT TCX
- ENH: Importing SQLT TC now handles IOT remapping
- ENH: Fix for 12c
sqlt$a: *** d:ORA-12899: value too large for column “SQLTXPLAIN”.”SQLT$_DBA_TAB_COLS”.”LOW_VALUE” (actual: 45, maximum: 40). - ENH: Added “version date” to SQLHC to make it easier to recognize if an old version is used
- ENH: Added “user” to SQLHC reporting the db login user
- ENH: SQLDX is now executed after SQLT/SQLHC completes, it helps in case SQLDX takes a long time to run since the zip file for SQLT/SQLHC is ready to be moved even when SQLDX is still running
- ENH: Added NUM_CPUs, NUM_COREs and NUM_CPU_SOCKETs info from V$OSSTAT to SQLT/SQLHC to help with multicore/multisocket CPUs
- ENH: Added Historical SQL Statistics – Total section to SQLHC
- ENH: SQLHC Exec now captures session statistics for the SQL analyzed
- ENH: New HC on Mviews not used in the SQL/plan that are defined on top of tables involved in the SQL/plan
- ENH: New column “If Offloadable” and “IO Saved %” on Exadata in Performance Statistics section
- ENH: New HC on Rewrite Equivalences defined by the owner of the objects involved in the SQL/plan
11.4.5.10 July 15, 2013
- BUG: Fixed issue with XPREXT and XPREXC where ASH was not turned off completely
- ENH: New health-check on plans with same PHV but predicates with different ordering
- ENH: SQLHC and SQLHCXEC now provides information about DBMS_STATS preferences
- ENH: SQLT shows when a parameter value has been changed (when this info is available in AWR)
- ENH: New link to Table Statistics Extensions directly available in the top menu
11.4.5.9 June 10, 2013
- ENH: New health-check on SDREADTIM/MREADTIM in Exadata
- ENH: Added SQLT parameter tcb_sampling_percent to control TCB sampling data percentage
- ENH: If no SQL is identified using the input string as HASH_VALUE then a search on PLAN_HASH_VALUE is performed
- ENH: Introduced new parameter c_ash_hist_days to split AWR data collection from ASH data collection and to limit the amount of info extracted from ASH
- ENH: Added scale information for TIMESTAMP datatype in Captured Binds sections
- ENH: ASH reports are now generated 1 per hour/instance starting from the interval where the SQL was most impacting
- ENH: SQLDX (SQL Dynamic eXtractor) collects only up to 10k rows per table/view
Carlos Sierra is joining Enkitec soon
In a few days I will be joining Enkitec. Sure I will miss Oracle after 17 good years there. I made some really good friends and I learned a lot. I had the opportunity to build tools I thought were needed by the Oracle community, and I am glad they are been deployed all over the world. I am also pleased to know all these tools will continue helping our SQL Tuning community with no disruption.
A question I am often asked is: WHY Enkitec? I could elaborate on an answer but to keep it short, I would simply say “because I like the idea of contributing to an expanding team of outstanding professionals in the Oracle space“. I also value the close relationship between Enkitec and Oracle. I see this as a win-win.
At Enkitec I will be doing a lot of stuff. My main focus at the beginning will be database performance in general and SQL Tuning in particular. I foresee the possibility to open some SQL Tuning hands-on workshops using SQLTXPLAIN, SQLHC and some other cool tools and techniques. I also expect some additional duties and new areas of expertise to develop, which I embrace as new challenges and opportunities.
Overall, I feel very excited and ready to start walking this new career path. What can I say… Just when I though life was good it simply got better!
You know how to reach me (here) or by email.
Cheers — Carlos
SQL Tuning 101 and Sushi
A question that I hear often is: “how to tune a query?”. It comes in several flavors, but what I usually read between lines is: I am new to this “sql tuning” thing, and I have been asked to improve the performance of this query, but I have no clue where to start.
Knowing about nothing on SQL Tuning is quite common for most DBAs. Even seasoned DBAs may stay away from SQL Tuning, mostly because they feel out of their comfort zone. In addition, I think SQL Tuning is like Sushi: You either love it or hate it! And same like Sushi, most would avoid it simply because they haven’t tried it. By the way, I am a Sushi lover but that is another story…
SQL Tuning 101
So, if you are like in square 1, and you are serious about learning SQL Tuning, where do you start? There are about a couple dozens of well recognized names on this space of SQL Tuning. Look at my blog roll to get some idea. The problem with this list is that most of the “gurus” walk on water and their very simple explanations require like tons of knowledge in related topics. Not bad if you are traveling the road from intermediate to advanced, but a newbie gets lost like in 5 seconds. There is also the risk of falling for all the misinformation you find in the internet written by some adventurous self-proclaimed “experts”.
I strongly suggest to start by reading the Concepts reference manual for your Oracle release, followed by the SQL Reference. Feeling comfortable writing SQL is a must. You don’t know SQL? Then, learn it first then move into SQL Tuning. If you have some Development experience that helps a lot. If you are a seasoned Developer you are half the way there already.
After reading the Concepts reference manual and becoming proficient in SQL, then get yourself a copy of the “Oracle SQL High-Performance Tuning (2nd Edition)” book written by Guy Harrison more than 10 years ago. Disregard the fact that the book is old. I like this book because it starts with the basics. It assumes nothing. I learned a lot from it when I first read it long time ago. If you search for it in Amazon just be aware the front-cover picture is incorrect, but the actual book is correct.
Another book I suggest is the recent one written by Stelios Charalambides. The title is “Oracle SQL Tuning with Oracle SQLTXPLAIN”. I like this one because it introduces SQLTXPLAIN like you would do with Sushi: Starting with a California Roll, then Sushi and last Sashimi. Also, you would get to learn of SQLTXPLAIN and how this FREE tool can help you to digest your dinner better… I mean your SQL Tuning.
Once you gain some experience doing some real SQL Tuning, then you can move to start reading endorsed blogs and books from the Sushi Masters. I hope you give it a try, and I hope you also get to love it!
