Discovering if a System level Parameter has changed its value (and when it happened)
Quite often I learn of a system where “nobody changed anything” and suddenly the system is experiencing some strange behavior. Then after diligent investigation it turns out someone changed a little parameter at the System level, but somehow disregarded mentioning it since he/she thought it had no connection to the unexpected behavior. As we all know, System parameters are big knobs that we don’t change lightly, still we often see “unknown” changes like the one described.
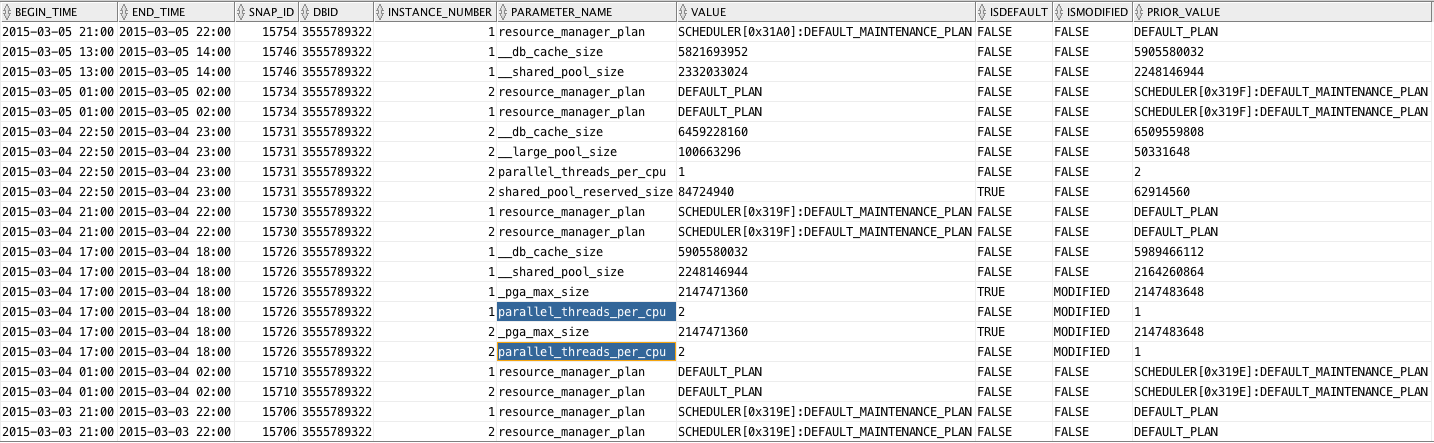
Script below produces a list of changes to System parameter values, indicating when a parameter was changed and from which value into which value. It does not filter out cache re-sizing operations, or resource manager plan changes. Both would be easy to exclude, but I’d rather see those global changes listed as well.
Note: This script below should only be executed if your site has a license for the Oracle Diagnostics pack (or Tuning pack), since it reads from AWR.
WITH
all_parameters AS (
SELECT snap_id,
dbid,
instance_number,
parameter_name,
value,
isdefault,
ismodified,
lag(value) OVER (PARTITION BY dbid, instance_number, parameter_hash ORDER BY snap_id) prior_value
FROM dba_hist_parameter
)
SELECT TO_CHAR(s.begin_interval_time, 'YYYY-MM-DD HH24:MI') begin_time,
TO_CHAR(s.end_interval_time, 'YYYY-MM-DD HH24:MI') end_time,
p.snap_id,
p.dbid,
p.instance_number,
p.parameter_name,
p.value,
p.isdefault,
p.ismodified,
p.prior_value
FROM all_parameters p,
dba_hist_snapshot s
WHERE p.value != p.prior_value
AND s.snap_id = p.snap_id
AND s.dbid = p.dbid
AND s.instance_number = p.instance_number
ORDER BY
s.begin_interval_time DESC,
p.dbid,
p.instance_number,
p.parameter_name
/
Sample output follows, where we can see a parameter affecting Degree of Parallelism was changed. This is just to illustrate its use. Enjoy this new free script! It is now part of edb360.
SQLTXPLAIN under new administration
During my 17 years at Oracle, I developed several tools and scripts. The largest and more widely used is SQLTXPLAIN. It is available through My Oracle Support (MOS) under document_id 215187.1.
SQLTXPLAIN, also know as SQLT, is a tool for SQL diagnostics, including Performance and Wrong Results. I am the original developer and author, but since very early stages of its development, this tool encapsulates the expertise of many bright engineers, DBAs, developers and others, who constantly helped to improve this tool on every new release by providing valuable feedback. SQLT is then nothing but the collection of many good ideas from many people. I was just the lucky guy that decided to build something useful for the Oracle SQL tuning community.
When I decided to join Enkitec back on 2013, I asked Mauro Pagano to look after my baby (I mean SQLT), and sure enough he did an excellent job. Mauro fixed most of my bugs, as he jokes about, and also incorporated some of his own :-). Mauro kept SQLT in good shape and he was able to continue improving it on every new release. Now Mauro also works for Enkitec, so SQLT has a new owner and custodian at Oracle.
Abel Macias is the new owner of SQLT, and as such he gets busy maintaining and enhancing this tool among other duties at Oracle. So, if you have enhancement requests, or positive feedback, please reach out to Abel at his Oracle account: abel.macias@oracle.com. If you come across some of my other tools and scripts, and they show my former Oracle account (carlos.sierra@oracle.com), please reach out to Abel and he might be able to route your concern or question.
Since one of my hobbies is to build free software that I also consume, my current efforts are on eDB360, eAdam and eSP. The most popular and openly available is eDB360, which basically gives your a 360-degree view of a database without installing anything. Then, Mauro is also building something cool on his own free time. Mauro is building the new SQLd360 tool, which is already available on the web (search for SQLd360). This SQLd360 tool, similar to eDB360, provides a 360-degree view, but instead of a database its focus is one SQL. And similarly than eDB360 it installs nothing on the database. Both are available as “free software” for anyone to download and use. That is the nice part: everyone likes free! (specially if any good).
What is the difference between SQLd360 and SQLT?
Both are exceptional tools. And both can be used for SQL Tuning and for SQL diagnostics. The main differences in my opinion are these:
- SQLT has it all. It is huge and it covers pretty much all corners. So, for SQL Tuning this SQLTXPLAIN is “THE” tool.
- SQLd360 in the other hand is smaller, newer and faster to execute. It gives me what is more important and most commonly used.
- SQLT requires to install a couple of schemas and hundreds of objects. SQLd360 installs nothing!
- To download SQLT you need to login into MOS. In contrast, SQLd360 is wide open (free software license), and no login is needed.
- Oracle Support requires SQLT, and Oracle Engineers are not exposed yet to SQLd360.
- SQLd360 uses Google charts (as well as eDB360 does) which enhance readability of large data sets, like time series for example. Thus SQLd360 output is quite readable.
- eDB360 calls SQLd360 on SQL of interest (large database consumers), so in that sense SQLd360 enhances eDB360. But SQLd360 can also be used stand-alone.
If you ask me which one would I recommend, I would answer: both!. If you can use both, then that is better than using just one. Each of these two tools (SQLT and SQLd360) has pros and cons compared to the other. But at the end both are great tools. And thanks to Abel Macias, SQLT continues its lifecycle with frequent enhancements. And thanks to Mauro, we have now a new kid on the block! I would say we have a win-win for our large Oracle community!
Learn how free new tool sqld360 can tell you so much about your favorite SQL!
New tool sqld360 is now available! Mauro Pagano released this cool new tool a few hours ago. And yes, it is free for all!
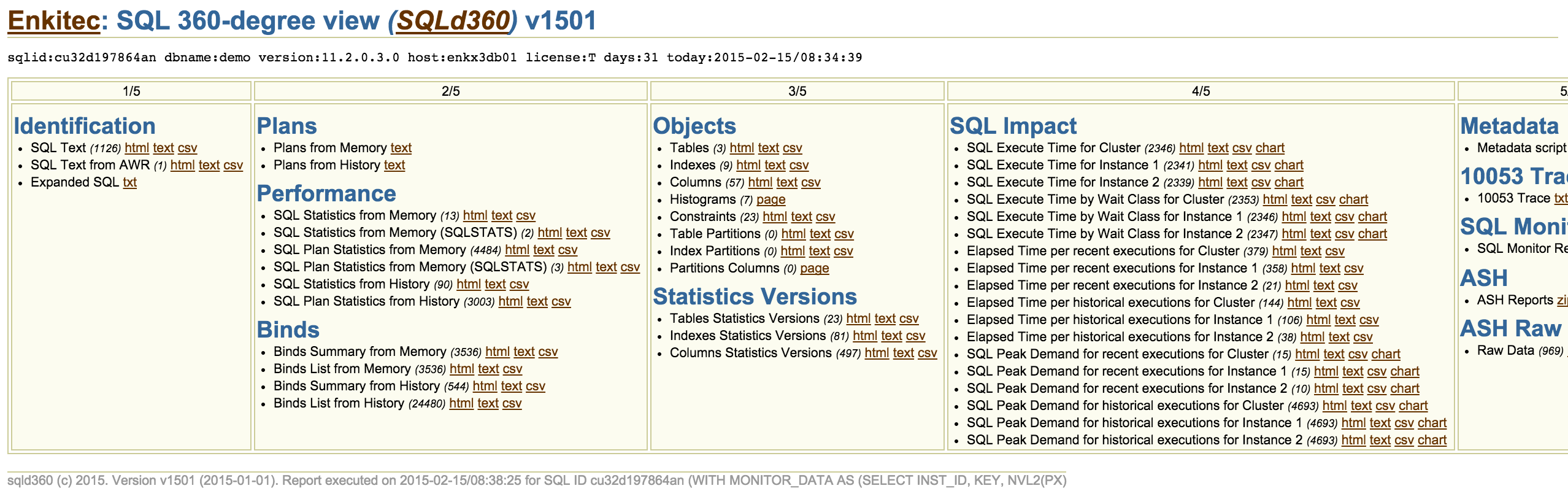
So, what is sqld360? Well, it is an install-nothing free software that tells you a lot about one SQL statement. And if your site has an Oracle Tuning Pack or Diagnostics Pack license, then you get a lot more from sqld360. Sample snapshot below shows you the dynamic menu for a simple SQL. This sqld360 new tool uses similar techniques than edb360, so it displays information as html, text, csv and in some cases it uses some cool Google charts.
The obvious question is why would I use this sqld360 instead of SQLT or SQLHC? The answer is: you can use them all. What makes sqld360 different to SQLT is that sqld360 installs nothing on the database. And what makes sqld360 different to SQLHC is that sqld360 is available as free software on a GitHub repository, so you don’t have to have a MOS account available. Any Oracle user can download and use sqld360 starting today!
In terms of content, I can say that SQLHC gives you some Observations and sqld360 does not (yet). Besides that, I think sqld360 is superior to SQLHC simply because it is more mature and developed from scratch using newer techniques.
SQLT is a different animal. It provides tons of functionality developed over a decade. This sqld360 is on its first release, but it will certainly grow over time but only in the right directions. From the beginning, sqld360 focuses on what is important for tuners and for those in need to diagnose a SQL misbehaving. So simply put, sqld360 is faster and better focused than SQLT and SQLHC. We can call it “the next generation”.
Why free? The answer is: Why not? When Mauro and I started discussing sqld360, we decided to continue developing cool scripts and tools on our own personal time, on our own hardware, and without taking anything from anyone. So this is kind of our contribution to our Oracle community. I have provided edb360 and Mauro is providing sqld360. Mauro and myself would love to blog more often, but if we have to decide where to put our personal time, we both are more inclined to invest on free tools (after of course our family duties).
It is hard to appreciate with a sample execution from one of our systems, but if you look at chart below you may get to see how a SQL of interest compares to the system load. This kind of chart is helpful when you are trying to understand how a particular SQL affects a given load for a certain time window. Or when you need to documents your findings to business leaders.
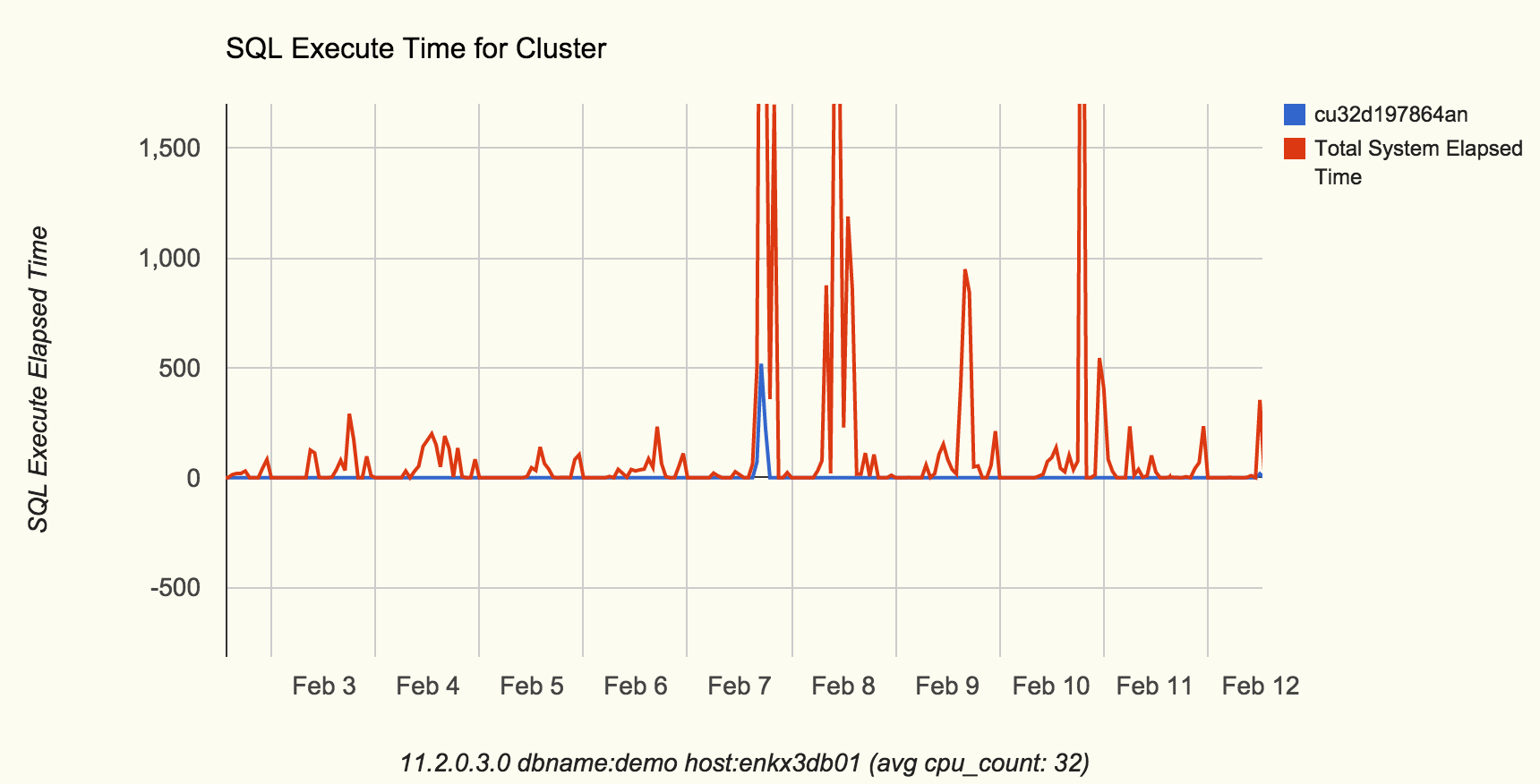
I could continue telling more about sqld360, but the best way to appreciate it is by actually trying it on one of your own SQL statements. You can go to Mauro’s blog post about sqld360 and download this tool following instructions there. Then give it a shot, after all you have nothing to loose.
Forgot to mention this: sqld360 as well as edb360 work through a SQL*Plus connection, either on the database server or on a PC client. This is important since quite often we road-warriors and even in-house developers may not have access to OEM or some other persistently-connected tools. Then, with sqld360 and edb360, using a SQL*Plus connection you can extract enough metadata to analyze and comprehend what is happening on the entire database or around one particular SQL, all without having to be persistently-connected to the database. Yes, you can do all your analysis remotely from home! yay!
And, by the way, as of today edb360 calls sqld360 on SQL of interest. So if you are already using edb360 you may want to download version v1504 dated February 15, 2015. This edb360 v1504 contains sqld360.
I hope you enjoy both tools. Life is Good!
Some eDB360 Frequently Asked Questions
As I get frequent questions about eDB360 I decided to post some FAQ here. First, some links to prior posts:
- Video: Introducing the eDB360 Tool
- What to do if edb360 takes long to run
- eDB360
- What is new with EDB360?
- How to execute eAdam and eDB360
- Meet “edb360″: a free tool that provides a 360-degree view of an Oracle database
- Presentations
Q: When is the best time to execute edb360?
A: At the end of a regular working day. Since it may take several hours to execute, some customers schedule it for a Friday evening.
Q: How long will edb360 take to execute on my production environment?
A: I don’t know. Best way to predict this is by executing edb360 in a lower but similar environment, like QA or TEST.
Q: Are there any risks on executing edb360 on a production environment?
A: No that I know. Think edb360 as a long sequence of SQL statements against DBA and GV$ views. Are they going to break anything? In theory not. So far I haven’t see edb360 breaking any environment. And if it does most probably it would a database bug. Most conservative approach is to try it first on a lower environment.
Q: Does edb360 install anything on my database?
A: No.
Q: Does edb360 changes the state of my database?
A: No.
Q: My edb360 seems to be hanging. How can I tell for sure?
A: Use any normal method: OEM, query long operations, look at V$SQL for active SQL. If you see edb360 is “stuck” at one SQL for let’s say more than one hour, you may want to report this to me. You can also find the SQL, kill the session, comment out that SQL out of edb360 code, and retry. When I have seen this, it happens to be either a known database bug, or lack of good statistics on schema objects behind particular query.
Q: Why is the output of edb360 so extensive?
A: We don’t know what we don’t know. Since edb360 is used for Oracle databases health-checks, trying to minimize the number of round trips to collect diagnostics, this tool collects many pieces of information. Sometimes we use most, sometimes we use a small subset. It all depends what we see.
Q: How do I read edb360?
A: Personally, I read everything. It takes me at least one day for an initial review. When I look at it for the 2nd or 3rd time, my search is narrower and deeper. While I look at it the 1st time I take some light notes, else I forget what I have seen so far.
Q: Can I use edb360 on any Oracle database?
A: Yes, as long as it is 10g, 11g or 12c. It works on any platform, but it works better on Linux and UNIX. It works for any application, including EBS, PSFT, Siebel, SAP and any custom one.
Q: Can I use edb360 on a non-Oracle database?
A: No.
Q: Is edb360 certified to run on 12c?
A: Not yet. It should work fine for single-tenant databases. I haven’t tested it on 12c although. I will do soon.
Q: Can I use edb360 for sizing and/or capacity?
A: Yes and no. edb360 captures sizing metadata using the eSP collector. The eSP application for Sizing and Provisioning is Enkitec’s proprietary (now Accenture’s). So we can use edb360 for sizing, but only internally and when our client asks for it.
Q: Is edb360 free software?
A: Yes. look for license file included on tool.
Q: Where do I get the latest version of this tool?
A: Look at the column at the right of this entry. There is a section with a “Download” title. That links will take you to a GitHub location where you can download the latest version.
Q: Can I use edb360 for SQL Tuning?
A: Actually, for that you may want to get SQLd360, which is work in progress by Mauro Pagano. In the meantime you can use planx.sql, sqlmon.sql, sqlash.sql (under my cscripts) or download SQLTXPLAIN and/or SQLHC from MOS.
Q: Can I share edb360 tool with others?
A: Absolutely! I developed this tool thinking on our Oracle community.
Q: I have some ideas to improve edb360. How can I provide them?
A: Send me an email, or post them here. Every so often I get some good ideas, which I put on my list and one day I get to them. Keep in mind that I work on edb360 on my free personal time, so some ideas take longer to implement than others.
Q: Where can I learn more about edb360?
A: Look at links at the top. There is a 1hr presentation that goes over what this tool does. There is also a fresh sample output available.
Why do you need to gather CBO Statistics?
As I help a peer with a SQL Tuning engagement, I face the frequent case of: “We do not want to gather CBO schema object statistics because we don’t want our Execution Plans to change”. Well, the bad news is that: not gathering stats only gives you a false sense of safety because your Execution Plans can change anyways. The reason has to do with Predicates referencing values out of range. Typical cases include range of dates, or columns seeded with values out of a sequence (surrogate keys). Most applications use them both. Example: predicate that references last X days of data. Imagine that date column on this predicate actually has statistics with low and high value that are outdated, lets say the high value refers to last time we gather stats (several months old). In such cases, the CBO uses some heuristics starting on 10g, where the cardinality of the Predicate is computed according to range of low/high and how far the value on Predicate is from this low/high range as per the stats. In short, the cardinality changes over time, as the Predicate on the last X days of data changes from one day to the next, and the next, and so on. At some point, the CBO may decide for a different Plan (with lower cost) and the performance of such SQL may indeed change abruptly. Then we scratch our heads and repeat to ourselves: but we did not gather statistics, why did the plan change?
So, if you understand the rationale above, then you would agree with the fact that: not updating CBO schema stats do not offer any real Plan Stability. So, my recommendation is simple: have reasonable CBO statistics and live with the possibility that some Plans will change (they would change anyways, even if you do not gather stats). Keep always in mind this:
The CBO has better chances to produce optimal Plans if we provide reasonable CBO statistics.
Now the good news: if you have some business critical SQL statements and you want them to have stable Plans, then Oracle already provides SQL Plan Management, which is designed exactly for Plan Stability. So, instead of gambling everyday, hoping for your Plans not to change preserving outdated stats, rather face reality, then gather stats, and create SQL Plan Baselines in those few SQL statements that may prove to have an otherwise unstable Plan and are indeed critical for your business. On 10g you can use SQL Profiles instead.
On 10g and 11g, just let the automatic job that gathers CBO schema statistics do its part. In most cases, that is good enough. If you have transient data, for example ETL tasks, then you may want to have the process workflow to gather stats on particular Tables as soon as the data is loaded or transformed and before it is consumed. The trick is simple: “have the stats represent the data at all times”. At the same time, there is no need to over do the stats, just care when the change on the data is sensible.
Finding SQL with Performance changing over time
I upgraded my database a couple of weeks ago and now my users complain their application is slower. They do not provide specifics but they “feel” it is running slower. Sounds familiar?
Every once in a while I get a request that goes like this: “how can I find if some SQL on my database is performing worse over time?”
It is very hard to deal with the ambiguities of some problems like “finding SQL that performs worse or better over time”. But if you simplify the problem and consider for example “Elapsed Time per Execution”, then you can easily produce a script like the one below, which returns a small list of SQL statements that seem to experience either a regression or an improvement over time. It uses linear regression on the ratio between “Elapsed Time per Execution” and its Median per SQL.
Then, If you are suspecting you have some SQL that may have regressed and need a hand to identify them, you can try this script below. It is now part of a small collection of scripts that you can download and use for free out of the cscripts link on the right hand side of this page, under “Downloads”.
----------------------------------------------------------------------------------------
--
-- File name: sql_performance_changed.sql
--
-- Purpose: Lists SQL Statements with Elapsed Time per Execution changing over time
--
-- Author: Carlos Sierra
--
-- Version: 2014/10/31
--
-- Usage: Lists statements that have changed their elapsed time per execution over
-- some history.
-- Uses the ration between "elapsed time per execution" and the median of
-- this metric for SQL statements within the sampled history, and using
-- linear regression identifies those that have changed the most. In other
-- words where the slope of the linear regression is larger. Positive slopes
-- are considered "improving" while negative are "regressing".
--
-- Example: @sql_performance_changed.sql
--
-- Notes: Developed and tested on 11.2.0.3.
--
-- Requires an Oracle Diagnostics Pack License since AWR data is accessed.
--
-- To further investigate poorly performing SQL use sqltxplain.sql or sqlhc
-- (or planx.sql or sqlmon.sql or sqlash.sql).
--
---------------------------------------------------------------------------------------
--
SPO sql_performance_changed.txt;
DEF days_of_history_accessed = '31';
DEF captured_at_least_x_times = '10';
DEF captured_at_least_x_days_apart = '5';
DEF med_elap_microsecs_threshold = '1e4';
DEF min_slope_threshold = '0.1';
DEF max_num_rows = '20';
SET lin 200 ver OFF;
COL row_n FOR A2 HEA '#';
COL med_secs_per_exec HEA 'Median Secs|Per Exec';
COL std_secs_per_exec HEA 'Std Dev Secs|Per Exec';
COL avg_secs_per_exec HEA 'Avg Secs|Per Exec';
COL min_secs_per_exec HEA 'Min Secs|Per Exec';
COL max_secs_per_exec HEA 'Max Secs|Per Exec';
COL plans FOR 9999;
COL sql_text_80 FOR A80;
PRO SQL Statements with "Elapsed Time per Execution" changing over time
WITH
per_time AS (
SELECT h.dbid,
h.sql_id,
SYSDATE - CAST(s.end_interval_time AS DATE) days_ago,
SUM(h.elapsed_time_total) / SUM(h.executions_total) time_per_exec
FROM dba_hist_sqlstat h,
dba_hist_snapshot s
WHERE h.executions_total > 0
AND s.snap_id = h.snap_id
AND s.dbid = h.dbid
AND s.instance_number = h.instance_number
AND CAST(s.end_interval_time AS DATE) > SYSDATE - &&days_of_history_accessed.
GROUP BY
h.dbid,
h.sql_id,
SYSDATE - CAST(s.end_interval_time AS DATE)
),
avg_time AS (
SELECT dbid,
sql_id,
MEDIAN(time_per_exec) med_time_per_exec,
STDDEV(time_per_exec) std_time_per_exec,
AVG(time_per_exec) avg_time_per_exec,
MIN(time_per_exec) min_time_per_exec,
MAX(time_per_exec) max_time_per_exec
FROM per_time
GROUP BY
dbid,
sql_id
HAVING COUNT(*) >= &&captured_at_least_x_times.
AND MAX(days_ago) - MIN(days_ago) >= &&captured_at_least_x_days_apart.
AND MEDIAN(time_per_exec) > &&med_elap_microsecs_threshold.
),
time_over_median AS (
SELECT h.dbid,
h.sql_id,
h.days_ago,
(h.time_per_exec / a.med_time_per_exec) time_per_exec_over_med,
a.med_time_per_exec,
a.std_time_per_exec,
a.avg_time_per_exec,
a.min_time_per_exec,
a.max_time_per_exec
FROM per_time h, avg_time a
WHERE a.sql_id = h.sql_id
),
ranked AS (
SELECT RANK () OVER (ORDER BY ABS(REGR_SLOPE(t.time_per_exec_over_med, t.days_ago)) DESC) rank_num,
t.dbid,
t.sql_id,
CASE WHEN REGR_SLOPE(t.time_per_exec_over_med, t.days_ago) > 0 THEN 'IMPROVING' ELSE 'REGRESSING' END change,
ROUND(REGR_SLOPE(t.time_per_exec_over_med, t.days_ago), 3) slope,
ROUND(AVG(t.med_time_per_exec)/1e6, 3) med_secs_per_exec,
ROUND(AVG(t.std_time_per_exec)/1e6, 3) std_secs_per_exec,
ROUND(AVG(t.avg_time_per_exec)/1e6, 3) avg_secs_per_exec,
ROUND(MIN(t.min_time_per_exec)/1e6, 3) min_secs_per_exec,
ROUND(MAX(t.max_time_per_exec)/1e6, 3) max_secs_per_exec
FROM time_over_median t
GROUP BY
t.dbid,
t.sql_id
HAVING ABS(REGR_SLOPE(t.time_per_exec_over_med, t.days_ago)) > &&min_slope_threshold.
)
SELECT LPAD(ROWNUM, 2) row_n,
r.sql_id,
r.change,
TO_CHAR(r.slope, '990.000MI') slope,
TO_CHAR(r.med_secs_per_exec, '999,990.000') med_secs_per_exec,
TO_CHAR(r.std_secs_per_exec, '999,990.000') std_secs_per_exec,
TO_CHAR(r.avg_secs_per_exec, '999,990.000') avg_secs_per_exec,
TO_CHAR(r.min_secs_per_exec, '999,990.000') min_secs_per_exec,
TO_CHAR(r.max_secs_per_exec, '999,990.000') max_secs_per_exec,
(SELECT COUNT(DISTINCT p.plan_hash_value) FROM dba_hist_sql_plan p WHERE p.dbid = r.dbid AND p.sql_id = r.sql_id) plans,
REPLACE((SELECT DBMS_LOB.SUBSTR(s.sql_text, 80) FROM dba_hist_sqltext s WHERE s.dbid = r.dbid AND s.sql_id = r.sql_id), CHR(10)) sql_text_80
FROM ranked r
WHERE r.rank_num <= &&max_num_rows.
ORDER BY
r.rank_num
/
SPO OFF;
Once you get the output of this script above, you can use the one below to actually list the time series for one of the SQL statements of interest:
----------------------------------------------------------------------------------------
--
-- File name: one_sql_time_series.sql
--
-- Purpose: Performance History for one SQL
--
-- Author: Carlos Sierra
--
-- Version: 2014/10/31
--
-- Usage: Script sql_performance_changed.sql lists SQL Statements with performance
-- improvement or regressed over some History.
-- This script one_sql_time_series.sql lists the Performance Time Series for
-- one SQL.
--
-- Parameters: SQL_ID
--
-- Example: @one_sql_time_series.sql
--
-- Notes: Developed and tested on 11.2.0.3.
--
-- Requires an Oracle Diagnostics Pack License since AWR data is accessed.
--
-- To further investigate poorly performing SQL use sqltxplain.sql or sqlhc
-- (or planx.sql or sqlmon.sql or sqlash.sql).
--
---------------------------------------------------------------------------------------
--
SPO one_sql_time_series.txt;
SET lin 200 ver OFF;
COL instance_number FOR 9999 HEA 'Inst';
COL end_time HEA 'End Time';
COL plan_hash_value HEA 'Plan|Hash Value';
COL executions_total FOR 999,999 HEA 'Execs|Total';
COL rows_per_exec HEA 'Rows Per Exec';
COL et_secs_per_exec HEA 'Elap Secs|Per Exec';
COL cpu_secs_per_exec HEA 'CPU Secs|Per Exec';
COL io_secs_per_exec HEA 'IO Secs|Per Exec';
COL cl_secs_per_exec HEA 'Clus Secs|Per Exec';
COL ap_secs_per_exec HEA 'App Secs|Per Exec';
COL cc_secs_per_exec HEA 'Conc Secs|Per Exec';
COL pl_secs_per_exec HEA 'PLSQL Secs|Per Exec';
COL ja_secs_per_exec HEA 'Java Secs|Per Exec';
SELECT h.instance_number,
TO_CHAR(CAST(s.end_interval_time AS DATE), 'YYYY-MM-DD HH24:MI') end_time,
h.plan_hash_value,
h.executions_total,
TO_CHAR(ROUND(h.rows_processed_total / h.executions_total), '999,999,999,999') rows_per_exec,
TO_CHAR(ROUND(h.elapsed_time_total / h.executions_total / 1e6, 3), '999,990.000') et_secs_per_exec,
TO_CHAR(ROUND(h.cpu_time_total / h.executions_total / 1e6, 3), '999,990.000') cpu_secs_per_exec,
TO_CHAR(ROUND(h.iowait_total / h.executions_total / 1e6, 3), '999,990.000') io_secs_per_exec,
TO_CHAR(ROUND(h.clwait_total / h.executions_total / 1e6, 3), '999,990.000') cl_secs_per_exec,
TO_CHAR(ROUND(h.apwait_total / h.executions_total / 1e6, 3), '999,990.000') ap_secs_per_exec,
TO_CHAR(ROUND(h.ccwait_total / h.executions_total / 1e6, 3), '999,990.000') cc_secs_per_exec,
TO_CHAR(ROUND(h.plsexec_time_total / h.executions_total / 1e6, 3), '999,990.000') pl_secs_per_exec,
TO_CHAR(ROUND(h.javexec_time_total / h.executions_total / 1e6, 3), '999,990.000') ja_secs_per_exec
FROM dba_hist_sqlstat h,
dba_hist_snapshot s
WHERE h.sql_id = '&sql_id.'
AND h.executions_total > 0
AND s.snap_id = h.snap_id
AND s.dbid = h.dbid
AND s.instance_number = h.instance_number
ORDER BY
h.sql_id,
h.instance_number,
s.end_interval_time,
h.plan_hash_value
/
SPO OFF;
Video: Introducing the eDB360 Tool
Some of you have asked if the “Introducing the eDB360 Tool” session at the Oaktable World 2014 was recorder. Actually it was, and thanks to Kyle Hailey it is now available as well as the slides. Just go to the agenda of this event and click on corresponding link. There you will also find video and/or slides for all other sessions.
Thanks Kyle for making this possible!
East Cost Oracle Users Group Conference 2014
The East Cost Oracle Users Group Conference 2014 is next week. To me, ECO is quite special. I am speaking there for my 3rd time!
The ECO group is kind of new (about 4 years old), and it is the clustering of several regional user groups including the Virginia Oracle Users Group, the Eastern States Oracle Applications Users Group, the Hampton Roads Oracle Users Group, and the Southeastern Oracle Users Group.
What I like about ECO is its size: small enough to remain cozy, and large enough to be a good opportunity to have one-on-one conversations with colleagues and friends.
This time at ECO 14, I will be delivering a session on “How a Developer Can Troubleshoot a SQL Performing Poorly on a Production DB” on Tuesday, November 4 at 3:15 PM (see agenda here). I will also co-deliver a 4-hours pre-conference workshop on “Oracle Performance Tuning” on Monday, November 3 at 1:00 PM. I will do this with Mauro Pagano, who is now a regular speaker and he is becoming a blogger. You can read his brand new blog at mauro-pagano.com.
Looking forward to meet old friends at ECO 14, and to make new ones!
What to do if edb360 takes long to run
Every once in a while it comes to my attention that edb360 takes several hours to run. What can be done? My advice is to let it run for several hours if possible. In most environment it completes in less that 1 hour, but I have seen cases where it may take 5 or 6. The reason is simple: too many SQL statements to execute. And some of those queries are executed on top of large historical sets. The good news is that edb360, as it executes each script, it compresses the output and catalogues it inside the main output ZIP file. So, even if you have to stop edb360 after hours of execution, the output is useful. On top of that, the least relevant collection happens at the end, so within the first hour or so you most probably have the essence of your system. Then, if you find yourself in a situation where edb360 has been in execution for several hours and you decide to kill it, please still use the output ZIP file. Also, within that file there are a couple of logs that can help to determine where exactly it got “stuck” (meaning which query is taking longer in your system). Since we don’t know in advance if edb360 will take more than 1hr to run, the best time to start its execution is at the end of a normal work day, or during the weekend.
Presentations
How a Developer Can Troubleshoot a SQL Performing Poorly on a Production DB (Nov 4, 2014)
Oracle Performance Tools of the Trade (Nov 4, 2014)
Oracle Performance Tuning Fundamentals (Nov 4, 2014)
Introducing the eDB360 Tool (Sep 30, 2014)
SQLT XPLORE: The SQLT XPLAIN hidden child (Jun 21, 2014)
SQL Tuning Tools of the Trade (Jun 21, 2014)
SQL Tuning made easier with SQLTXPLAIN (SQLT) (Jun 21, 2014)
Using SQL Plan Management (SPM) to balance Plan Flexibility and Plan Stability (Jun 21, 2014)
Understanding How is that Adaptive Cursor Sharing (ACS) produces multiple Optimal Plans (Jun 21, 2014)
